 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter LLM Reasoning via Dual-Play
Nov 19, 2025Large Language Models (LLMs) have achieved remarkable progress through Reinforcement Learning with Verifiable Rewards (RLVR), yet still rely heavily on external supervision (e.g., curated labels). Adversarial learning, particularly through self-play, offers a promising alternative that enables models to iteratively learn from themselves - thus reducing reliance on external supervision. Dual-play extends adversarial learning by assigning specialized roles to two models and training them against each other, fostering sustained competition and mutual evolution. Despite its promise, adapting dual-play training to LLMs remains limited, largely due to their susceptibility to reward hacking and training instability. In this paper, we introduce PasoDoble, a novel LLM dual-play framework. PasoDoble adversarially trains two models initialized from the same base model: a Proposer, which generates challenging questions with ground-truth answers, and a Solver, which attempts to solve them. We enrich the Proposer with knowledge from a pre-training dataset to ensure the questions' quality and diversity. To avoid reward hacking, the Proposer is rewarded for producing only valid questions that push the Solver's limit, while the Solver is rewarded for solving them correctly, and both are updated jointly. To further enhance training stability, we introduce an optional offline paradigm that decouples Proposer and Solver updates, alternately updating each for several steps while holding the other fixed. Notably, PasoDoble operates without supervision during training. Experimental results show that PasoDoble can improve the reasoning performance of LLMs. Our project page is available at https://hcy123902.github.io/PasoDoble.
HAPO: Training Language Models to Reason Concisely via History-Aware Policy Optimization
May 16, 2025



While scaling the length of responses at test-time has been shown to markedly improve the reasoning abilities and performance of large language models (LLMs), it often results in verbose outputs and increases inference cost. Prior approaches for efficient test-time scaling, typically using universal budget constraints or query-level length optimization, do not leverage historical information from previous encounters with the same problem during training. We hypothesize that this limits their ability to progressively make solutions more concise over time. To address this, we present History-Aware Policy Optimization (HAPO), which keeps track of a history state (e.g., the minimum length over previously generated correct responses) for each problem. HAPO employs a novel length reward function based on this history state to incentivize the discovery of correct solutions that are more concise than those previously found. Crucially, this reward structure avoids overly penalizing shorter incorrect responses with the goal of facilitating exploration towards more efficient solutions. By combining this length reward with a correctness reward, HAPO jointly optimizes for correctness and efficiency. We use HAPO to train DeepSeek-R1-Distill-Qwen-1.5B, DeepScaleR-1.5B-Preview, and Qwen-2.5-1.5B-Instruct, and evaluate HAPO on several math benchmarks that span various difficulty levels. Experiment results demonstrate that HAPO effectively induces LLMs' concise reasoning abilities, producing length reductions of 33-59% with accuracy drops of only 2-5%.
Towards More Robust Retrieval-Augmented Generation: Evaluating RAG Under Adversarial Poisoning Attacks
Dec 21, 2024Retrieval-Augmented Generation (RAG) systems have emerged as a promising solution to mitigate LLM hallucinations and enhance their performance in knowledge-intensive domains. However, these systems are vulnerable to adversarial poisoning attacks, where malicious passages injected into retrieval databases can mislead the model into generating factually incorrect outputs. In this paper, we investigate both the retrieval and the generation components of RAG systems to understand how to enhance their robustness against such attacks. From the retrieval perspective, we analyze why and how the adversarial contexts are retrieved and assess how the quality of the retrieved passages impacts downstream generation. From a generation perspective, we evaluate whether LLMs' advanced critical thinking and internal knowledge capabilities can be leveraged to mitigate the impact of adversarial contexts, i.e., using skeptical prompting as a self-defense mechanism. Our experiments and findings provide actionable insights into designing safer and more resilient retrieval-augmented frameworks, paving the way for their reliable deployment in real-world applications.
Gradient Flows and Riemannian Structure in the Gromov-Wasserstein Geometry
Jul 16, 2024



The Wasserstein space of probability measures is known for its intricate Riemannian structure, which underpins the Wasserstein geometry and enables gradient flow algorithms. However, the Wasserstein geometry may not be suitable for certain tasks or data modalities. Motivated by scenarios where the global structure of the data needs to be preserved, this work initiates the study of gradient flows and Riemannian structure in the Gromov-Wasserstein (GW) geometry, which is particularly suited for such purposes. We focus on the inner product GW (IGW) distance between distributions on $\mathbb{R}^d$. Given a functional $\mathsf{F}:\mathcal{P}_2(\mathbb{R}^d)\to\mathbb{R}$ to optimize, we present an implicit IGW minimizing movement scheme that generates a sequence of distributions $\{\rho_i\}_{i=0}^n$, which are close in IGW and aligned in the 2-Wasserstein sense. Taking the time step to zero, we prove that the discrete solution converges to an IGW generalized minimizing movement (GMM) $(\rho_t)_t$ that follows the continuity equation with a velocity field $v_t\in L^2(\rho_t;\mathbb{R}^d)$, specified by a global transformation of the Wasserstein gradient of $\mathsf{F}$. The transformation is given by a mobility operator that modifies the Wasserstein gradient to encode not only local information, but also global structure. Our gradient flow analysis leads us to identify the Riemannian structure that gives rise to the intrinsic IGW geometry, using which we establish a Benamou-Brenier-like formula for IGW. We conclude with a formal derivation, akin to the Otto calculus, of the IGW gradient as the inverse mobility acting on the Wasserstein gradient. Numerical experiments validating our theory and demonstrating the global nature of IGW interpolations are provided.
Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized Large Language Models
Jan 13, 2024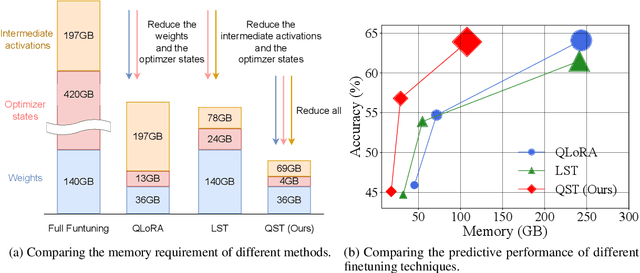
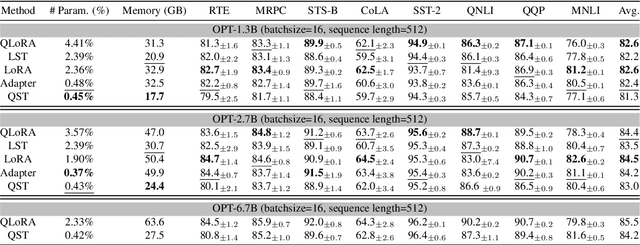
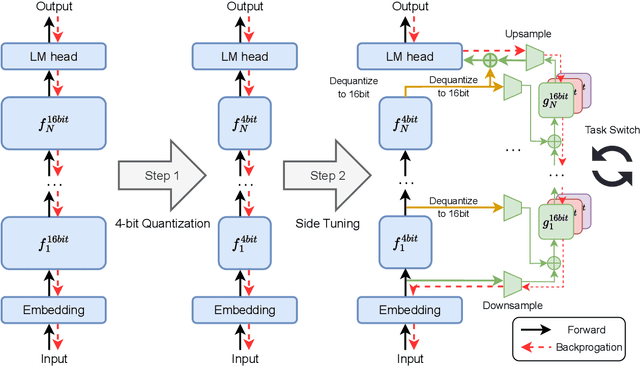

Finetuning large language models (LLMs) has been empirically effective on a variety of downstream tasks. Existing approaches to finetuning an LLM either focus on parameter-efficient finetuning, which only updates a small number of trainable parameters, or attempt to reduce the memory footprint during the training phase of the finetuning. Typically, the memory footprint during finetuning stems from three contributors: model weights, optimizer states, and intermediate activations. However, existing works still require considerable memory and none can simultaneously mitigate memory footprint for all three sources. In this paper, we present Quantized Side Tuing (QST), which enables memory-efficient and fast finetuning of LLMs by operating through a dual-stage process. First, QST quantizes an LLM's model weights into 4-bit to reduce the memory footprint of the LLM's original weights; QST also introduces a side network separated from the LLM, which utilizes the hidden states of the LLM to make task-specific predictions. Using a separate side network avoids performing backpropagation through the LLM, thus reducing the memory requirement of the intermediate activations. Furthermore, QST leverages several low-rank adaptors and gradient-free downsample modules to significantly reduce the trainable parameters, so as to save the memory footprint of the optimizer states. Experiments show that QST can reduce the total memory footprint by up to 2.3 $\times$ and speed up the finetuning process by up to 3 $\times$ while achieving competent performance compared with the state-of-the-art. When it comes to full finetuning, QST can reduce the total memory footprint up to 7 $\times$.
Cycle Consistent Probability Divergences Across Different Spaces
Nov 22, 2021


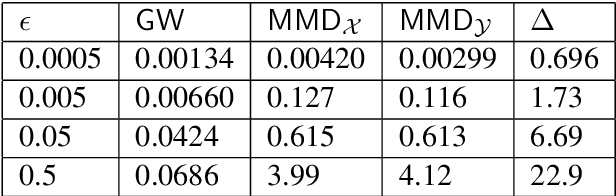
Discrepancy measures between probability distributions are at the core of statistical inference and machine learning. In many applications, distributions of interest are supported on different spaces, and yet a meaningful correspondence between data points is desired. Motivated to explicitly encode consistent bidirectional maps into the discrepancy measure, this work proposes a novel unbalanced Monge optimal transport formulation for matching, up to isometries, distributions on different spaces. Our formulation arises as a principled relaxation of the Gromov-Haussdroff distance between metric spaces, and employs two cycle-consistent maps that push forward each distribution onto the other. We study structural properties of the proposed discrepancy and, in particular, show that it captures the popular cycle-consistent generative adversarial network (GAN) framework as a special case, thereby providing the theory to explain it. Motivated by computational efficiency, we then kernelize the discrepancy and restrict the mappings to parametric function classes. The resulting kernelized version is coined the generalized maximum mean discrepancy (GMMD). Convergence rates for empirical estimation of GMMD are studied and experiments to support our theory are provided.
Non-Asymptotic Performance Guarantees for Neural Estimation of $\mathsf{f}$-Divergences
Mar 16, 2021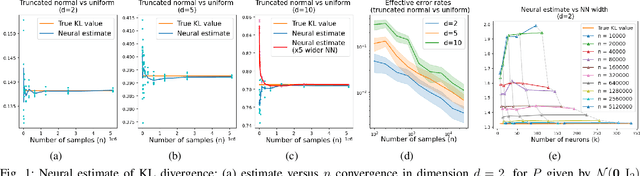
Statistical distances (SDs), which quantify the dissimilarity between probability distributions, are central to machine learning and statistics. A modern method for estimating such distances from data relies on parametrizing a variational form by a neural network (NN) and optimizing it. These estimators are abundantly used in practice, but corresponding performance guarantees are partial and call for further exploration. In particular, there seems to be a fundamental tradeoff between the two sources of error involved: approximation and estimation. While the former needs the NN class to be rich and expressive, the latter relies on controlling complexity. This paper explores this tradeoff by means of non-asymptotic error bounds, focusing on three popular choices of SDs -- Kullback-Leibler divergence, chi-squared divergence, and squared Hellinger distance. Our analysis relies on non-asymptotic function approximation theorems and tools from empirical process theory. Numerical results validating the theory are also provided.
Road Extraction by Deep Residual U-Net
Nov 29, 2017



Road extraction from aerial images has been a hot research topic in the field of remote sensing image analysis. In this letter, a semantic segmentation neural network which combines the strengths of residual learning and U-Net is proposed for road area extraction. The network is built with residual units and has similar architecture to that of U-Net. The benefits of this model is two-fold: first, residual units ease training of deep networks. Second, the rich skip connections within the network could facilitate information propagation, allowing us to design networks with fewer parameters however better performance. We test our network on a public road dataset and compare it with U-Net and other two state of the art deep learning based road extraction methods. The proposed approach outperforms all the comparing methods, which demonstrates its superiority over recently developed state of the arts.