 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Prompt KV Cache: Where It Becomes Dispensable
May 28, 2026Prior KV cache compression schemes empirically demonstrate that the prompt cache is partially redundant during decoding, dropping or summarising entries with little accuracy loss. We ask when and what kind of redundancy: at which layers, after how many decoding steps, and in what form can the prompt span KV cache be replaced without breaking the task. A controlled splice intervention swept over layer cutoff and decoding steps shows this redundancy is about form (chat template scaffolding) rather than content. Replacing the upper layer prompt span KV cache with KV cache from a chat template scaffold whose user content is a neutral filler recovers near clean accuracy, while zeroing the same slots collapses accuracy. The dissociation replicates across the Qwen3, Gemma 3, and Llama 3 families on multiple datasets.
When Facts Change: Probing LLMs on Evolving Knowledge with evolveQA
Oct 22, 2025LLMs often fail to handle temporal knowledge conflicts--contradictions arising when facts evolve over time within their training data. Existing studies evaluate this phenomenon through benchmarks built on structured knowledge bases like Wikidata, but they focus on widely-covered, easily-memorized popular entities and lack the dynamic structure needed to fairly evaluate LLMs with different knowledge cut-off dates. We introduce evolveQA, a benchmark specifically designed to evaluate LLMs on temporally evolving knowledge, constructed from 3 real-world, time-stamped corpora: AWS updates, Azure changes, and WHO disease outbreak reports. Our framework identifies naturally occurring knowledge evolution and generates questions with gold answers tailored to different LLM knowledge cut-off dates. Through extensive evaluation of 12 open and closed-source LLMs across 3 knowledge probing formats, we demonstrate significant performance drops of up to 31% on evolveQA compared to static knowledge questions.
Multi-Faceted Evaluation of Tool-Augmented Dialogue Systems
Oct 22, 2025Evaluating conversational AI systems that use external tools is challenging, as errors can arise from complex interactions among user, agent, and tools. While existing evaluation methods assess either user satisfaction or agents' tool-calling capabilities, they fail to capture critical errors in multi-turn tool-augmented dialogues-such as when agents misinterpret tool results yet appear satisfactory to users. We introduce TRACE, a benchmark of systematically synthesized tool-augmented conversations covering diverse error cases, and SCOPE, an evaluation framework that automatically discovers diverse error patterns and evaluation rubrics in tool-augmented dialogues. Experiments show SCOPE significantly outperforms the baseline, particularly on challenging cases where user satisfaction signals are misleading.
Privacy Adhering Machine Un-learning in NLP
Dec 19, 2022



Regulations introduced by General Data Protection Regulation (GDPR) in the EU or California Consumer Privacy Act (CCPA) in the US have included provisions on the \textit{right to be forgotten} that mandates industry applications to remove data related to an individual from their systems. In several real world industry applications that use Machine Learning to build models on user data, such mandates require significant effort both in terms of data cleansing as well as model retraining while ensuring the models do not deteriorate in prediction quality due to removal of data. As a result, continuous removal of data and model retraining steps do not scale if these applications receive such requests at a very high frequency. Recently, a few researchers proposed the idea of \textit{Machine Unlearning} to tackle this challenge. Despite the significant importance of this task, the area of Machine Unlearning is under-explored in Natural Language Processing (NLP) tasks. In this paper, we explore the Unlearning framework on various GLUE tasks \cite{Wang:18}, such as, QQP, SST and MNLI. We propose computationally efficient approaches (SISA-FC and SISA-A) to perform \textit{guaranteed} Unlearning that provides significant reduction in terms of both memory (90-95\%), time (100x) and space consumption (99\%) in comparison to the baselines while keeping model performance constant.
Unsupervised Neural Stylistic Text Generation using Transfer learning and Adapters
Oct 07, 2022



Research has shown that personality is a key driver to improve engagement and user experience in conversational systems. Conversational agents should also maintain a consistent persona to have an engaging conversation with a user. However, text generation datasets are often crowd sourced and thereby have an averaging effect where the style of the generation model is an average style of all the crowd workers that have contributed to the dataset. While one can collect persona-specific datasets for each task, it would be an expensive and time consuming annotation effort. In this work, we propose a novel transfer learning framework which updates only $0.3\%$ of model parameters to learn style specific attributes for response generation. For the purpose of this study, we tackle the problem of stylistic story ending generation using the ROC stories Corpus. We learn style specific attributes from the PERSONALITY-CAPTIONS dataset. Through extensive experiments and evaluation metrics we show that our novel training procedure can improve the style generation by 200 over Encoder-Decoder baselines while maintaining on-par content relevance metrics with
Dr.Quad at MEDIQA 2019: Towards Textual Inference and Question Entailment using contextualized representations
Jul 23, 2019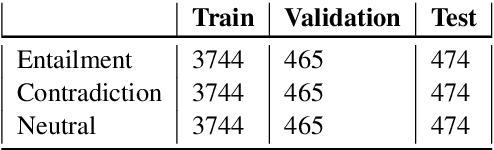
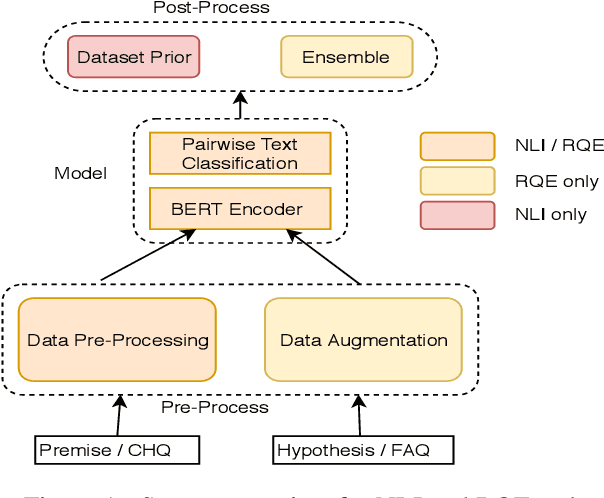

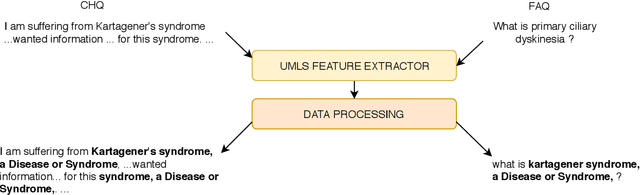
This paper presents the submissions by Team Dr.Quad to the ACL-BioNLP 2019 shared task on Textual Inference and Question Entailment in the Medical Domain. Our system is based on the prior work Liu et al. (2019) which uses a multi-task objective function for textual entailment. In this work, we explore different strategies for generalizing state-of-the-art language understanding models to the specialized medical domain. Our results on the shared task demonstrate that incorporating domain knowledge through data augmentation is a powerful strategy for addressing challenges posed by specialized domains such as medicine.
WriterForcing: Generating more interesting story endings
Jul 18, 2019

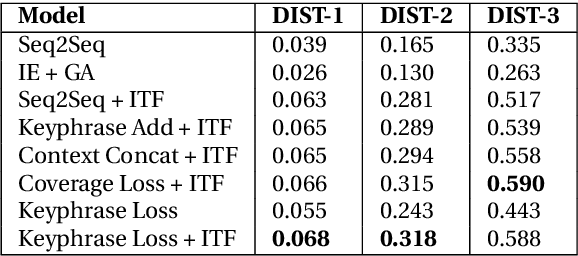
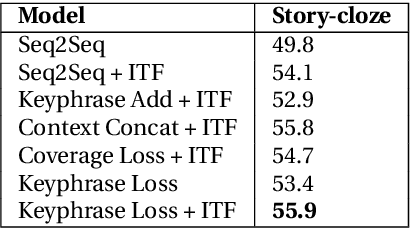
We study the problem of generating interesting endings for stories. Neural generative models have shown promising results for various text generation problems. Sequence to Sequence (Seq2Seq) models are typically trained to generate a single output sequence for a given input sequence. However, in the context of a story, multiple endings are possible. Seq2Seq models tend to ignore the context and generate generic and dull responses. Very few works have studied generating diverse and interesting story endings for a given story context. In this paper, we propose models which generate more diverse and interesting outputs by 1) training models to focus attention on important keyphrases of the story, and 2) promoting generation of non-generic words. We show that the combination of the two leads to more diverse and interesting endings.