 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Tensor Network Contraction Using Reinforcement Learning
Apr 18, 2022
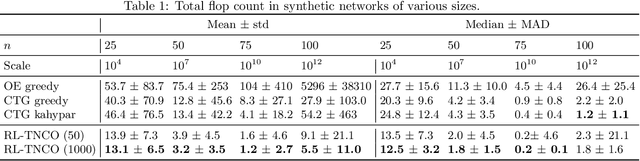
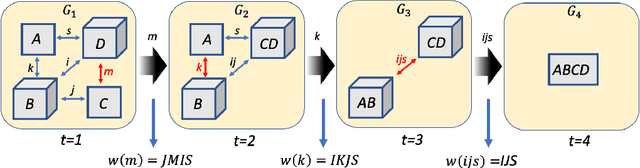

Quantum Computing (QC) stands to revolutionize computing, but is currently still limited. To develop and test quantum algorithms today, quantum circuits are often simulated on classical computers. Simulating a complex quantum circuit requires computing the contraction of a large network of tensors. The order (path) of contraction can have a drastic effect on the computing cost, but finding an efficient order is a challenging combinatorial optimization problem. We propose a Reinforcement Learning (RL) approach combined with Graph Neural Networks (GNN) to address the contraction ordering problem. The problem is extremely challenging due to the huge search space, the heavy-tailed reward distribution, and the challenging credit assignment. We show how a carefully implemented RL-agent that uses a GNN as the basic policy construct can address these challenges and obtain significant improvements over state-of-the-art techniques in three varieties of circuits, including the largest scale networks used in contemporary QC.
"This is my unicorn, Fluffy": Personalizing frozen vision-language representations
Apr 04, 2022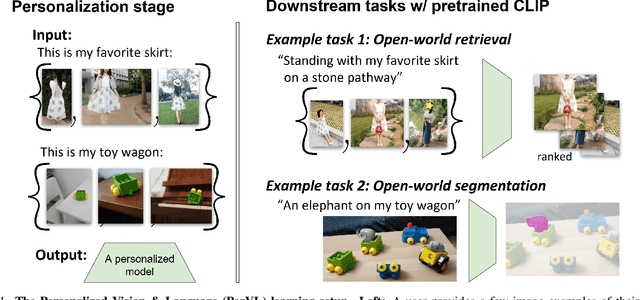
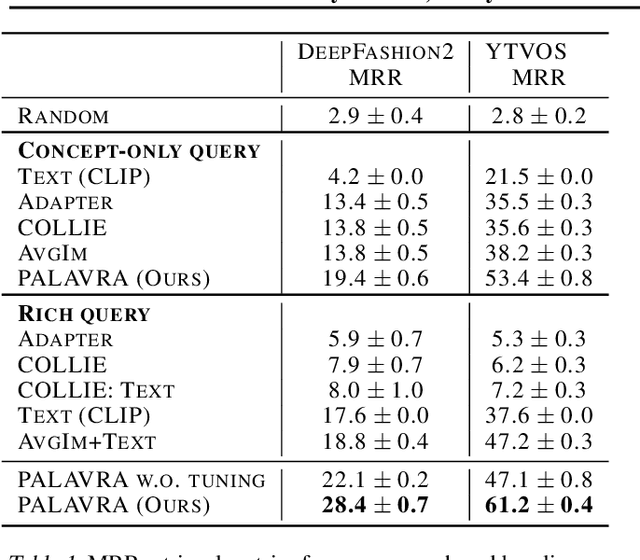
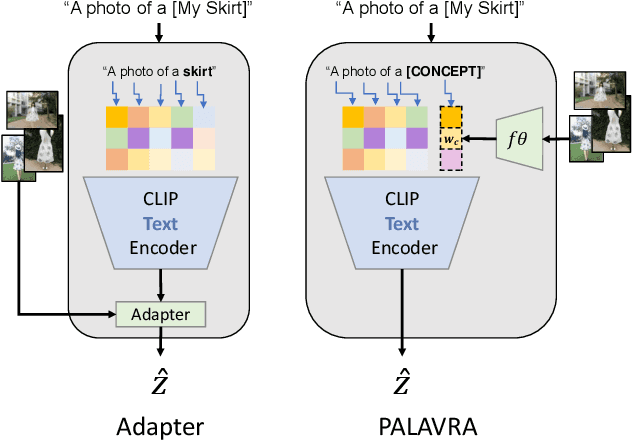

Large Vision & Language models pretrained on web-scale data provide representations that are invaluable for numerous V&L problems. However, it is unclear how they can be used for reasoning about user-specific visual concepts in unstructured language. This problem arises in multiple domains, from personalized image retrieval to personalized interaction with smart devices. We introduce a new learning setup called Personalized Vision & Language (PerVL) with two new benchmark datasets for retrieving and segmenting user-specific "personalized" concepts "in the wild". In PerVL, one should learn personalized concepts (1) independently of the downstream task (2) allowing a pretrained model to reason about them with free language, and (3) does not require personalized negative examples. We propose an architecture for solving PerVL that operates by extending the input vocabulary of a pretrained model with new word embeddings for the new personalized concepts. The model can then reason about them by simply using them in a sentence. We demonstrate that our approach learns personalized visual concepts from a few examples and can effectively apply them in image retrieval and semantic segmentation using rich textual queries.
Learning to reason about and to act on physical cascading events
Feb 02, 2022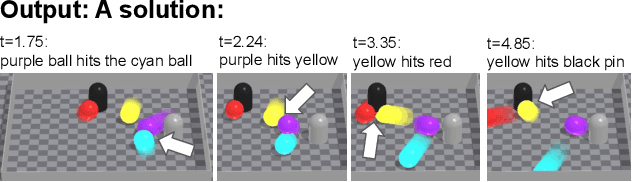
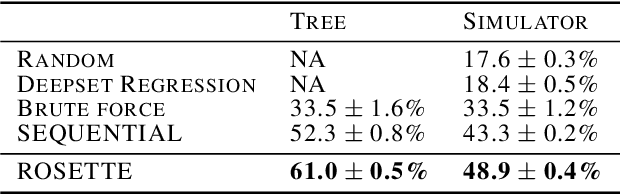


Reasoning and interacting with dynamic environments is a fundamental problem in AI, but it becomes extremely challenging when actions can trigger cascades of cross-dependent events. We introduce a new supervised learning setup called {\em Cascade} where an agent is shown a video of a physically simulated dynamic scene, and is asked to intervene and trigger a cascade of events, such that the system reaches a "counterfactual" goal. For instance, the agent may be asked to "Make the blue ball hit the red one, by pushing the green ball". The agent intervention is drawn from a continuous space, and cascades of events makes the dynamics highly non-linear. We combine semantic tree search with an event-driven forward model and devise an algorithm that learns to search in semantic trees in continuous spaces. We demonstrate that our approach learns to effectively follow instructions to intervene in previously unseen complex scenes. It can also reason about alternative outcomes, when provided an observed cascade of events.
How to Stop Epidemics: Controlling Graph Dynamics with Reinforcement Learning and Graph Neural Networks
Oct 26, 2020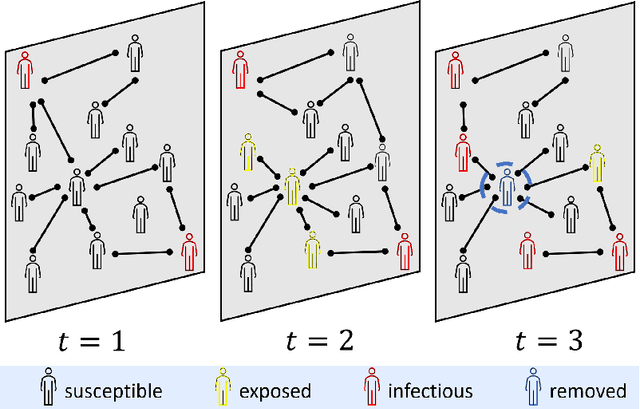
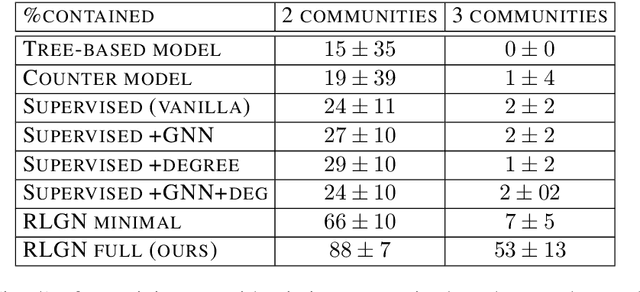
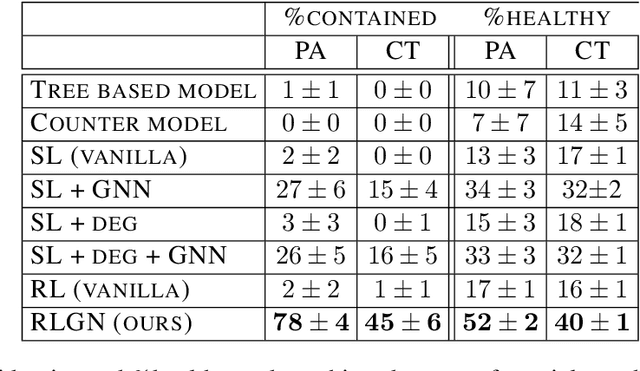
We consider the problem of monitoring and controlling a partially-observed dynamic process that spreads over a graph. This problem naturally arises in contexts such as scheduling virus tests or quarantining individuals to curb a spreading epidemic; detecting fake news spreading on online networks by manually inspecting posted articles; and targeted marketing where the objective is to encourage the spread of a product. Curbing the spread and constraining the fraction of infected population becomes challenging when only a fraction of the population can be tested or quarantined. To address this challenge, we formulate this setup as a sequential decision problem over a graph. In face of an exponential state space, combinatorial action space and partial observability, we design RLGN, a novel tractable Reinforcement Learning (RL) scheme to prioritize which nodes should be tested, using Graph Neural Networks (GNNs) to rank the graph nodes. We evaluate this approach in three types of social-networks: community-structured, preferential attachment, and based on statistics from real cellular tracking. RLGN consistently outperforms all baselines in our experiments. It suggests that prioritizing tests using RL on temporal graphs can increase the number of healthy people by $25\%$ and contain the epidemic $30\%$ more often than supervised approaches and $2.5\times$ more often than non-learned baselines using the same resources.
Localized epidemic detection in networks with overwhelming noise
Feb 06, 2014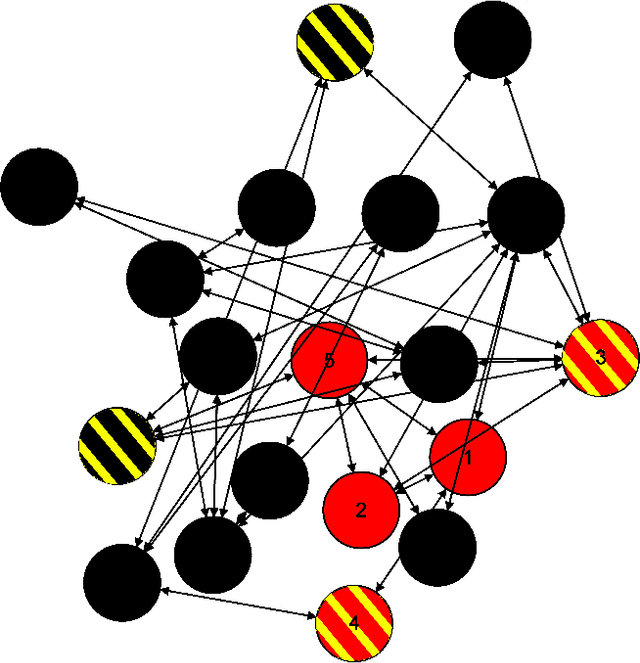
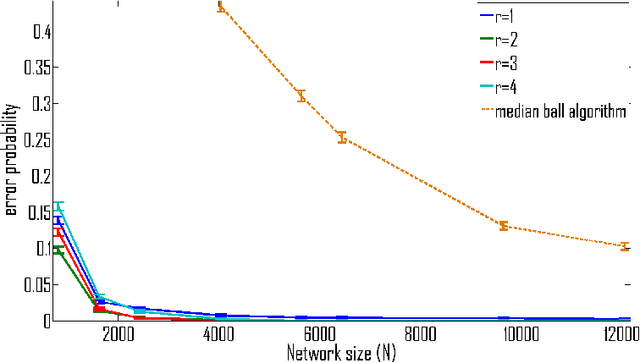
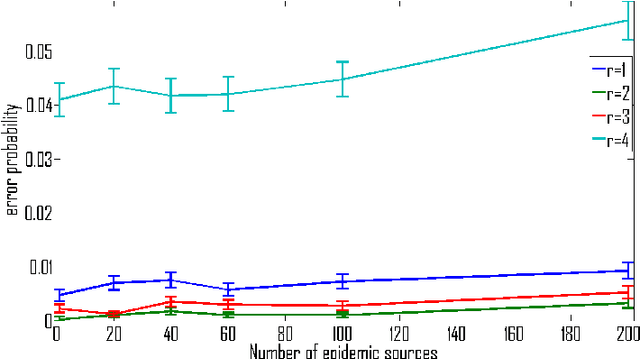
We consider the problem of detecting an epidemic in a population where individual diagnoses are extremely noisy. The motivation for this problem is the plethora of examples (influenza strains in humans, or computer viruses in smartphones, etc.) where reliable diagnoses are scarce, but noisy data plentiful. In flu/phone-viruses, exceedingly few infected people/phones are professionally diagnosed (only a small fraction go to a doctor) but less reliable secondary signatures (e.g., people staying home, or greater-than-typical upload activity) are more readily available. These secondary data are often plagued by unreliability: many people with the flu do not stay home, and many people that stay home do not have the flu. This paper identifies the precise regime where knowledge of the contact network enables finding the needle in the haystack: we provide a distributed, efficient and robust algorithm that can correctly identify the existence of a spreading epidemic from highly unreliable local data. Our algorithm requires only local-neighbor knowledge of this graph, and in a broad array of settings that we describe, succeeds even when false negatives and false positives make up an overwhelming fraction of the data available. Our results show it succeeds in the presence of partial information about the contact network, and also when there is not a single "patient zero", but rather many (hundreds, in our examples) of initial patient-zeroes, spread across the graph.