 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to reason about and to act on physical cascading events
Paper and Code
Feb 02, 2022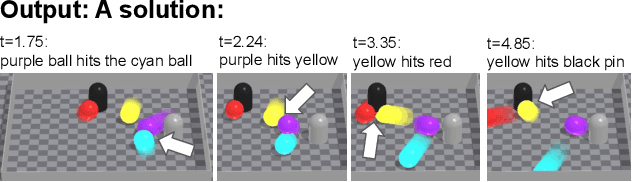
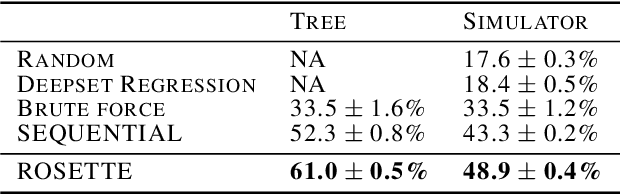


Reasoning and interacting with dynamic environments is a fundamental problem in AI, but it becomes extremely challenging when actions can trigger cascades of cross-dependent events. We introduce a new supervised learning setup called {\em Cascade} where an agent is shown a video of a physically simulated dynamic scene, and is asked to intervene and trigger a cascade of events, such that the system reaches a "counterfactual" goal. For instance, the agent may be asked to "Make the blue ball hit the red one, by pushing the green ball". The agent intervention is drawn from a continuous space, and cascades of events makes the dynamics highly non-linear. We combine semantic tree search with an event-driven forward model and devise an algorithm that learns to search in semantic trees in continuous spaces. We demonstrate that our approach learns to effectively follow instructions to intervene in previously unseen complex scenes. It can also reason about alternative outcomes, when provided an observed cascade of events.