 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivAug: Plug-in Automated Data Augmentation with Explicit Diversity Maximization
Paper and Code
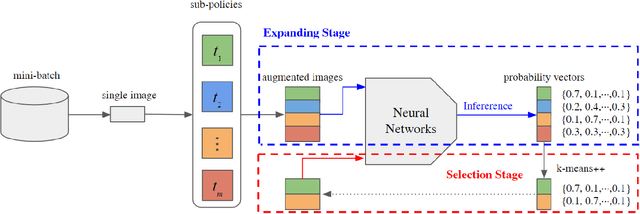

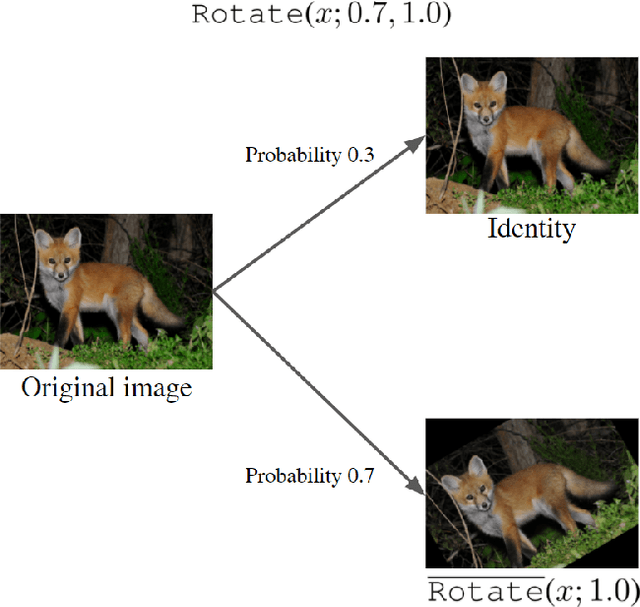
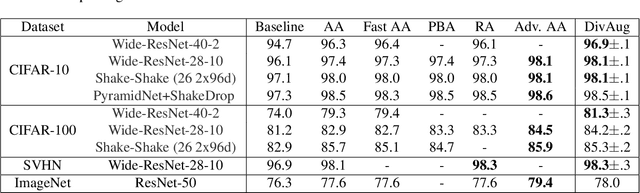
Human-designed data augmentation strategies have been replaced by automatically learned augmentation policy in the past two years. Specifically, recent work has empirically shown that the superior performance of the automated data augmentation methods stems from increasing the diversity of augmented data. However, two factors regarding the diversity of augmented data are still missing: 1) the explicit definition (and thus measurement) of diversity and 2) the quantifiable relationship between diversity and its regularization effects. To bridge this gap, we propose a diversity measure called Variance Diversity and theoretically show that the regularization effect of data augmentation is promised by Variance Diversity. We validate in experiments that the relative gain from automated data augmentation in test accuracy is highly correlated to Variance Diversity. An unsupervised sampling-based framework, DivAug, is designed to directly maximize Variance Diversity and hence strengthen the regularization effect. Without requiring a separate search process, the performance gain from DivAug is comparable with the state-of-the-art method with better efficiency. Moreover, under the semi-supervised setting, our framework can further improve the performance of semi-supervised learning algorithms when compared to RandAugment, making it highly applicable to real-world problems, where labeled data is scarce.