 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttack-agnostic Adversarial Detection on Medical Data Using Explainable Machine Learning
Paper and Code

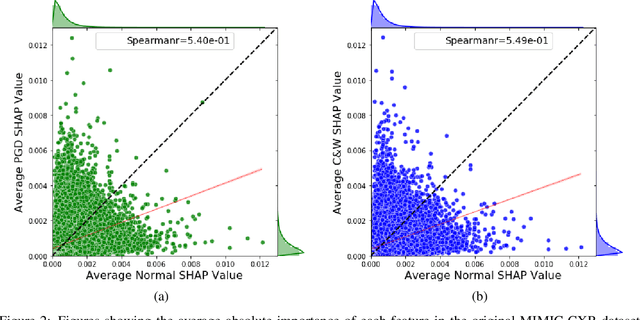

Explainable machine learning has become increasingly prevalent, especially in healthcare where explainable models are vital for ethical and trusted automated decision making. Work on the susceptibility of deep learning models to adversarial attacks has shown the ease of designing samples to mislead a model into making incorrect predictions. In this work, we propose a model agnostic explainability-based method for the accurate detection of adversarial samples on two datasets with different complexity and properties: Electronic Health Record (EHR) and chest X-ray (CXR) data. On the MIMIC-III and Henan-Renmin EHR datasets, we report a detection accuracy of 77% against the Longitudinal Adversarial Attack. On the MIMIC-CXR dataset, we achieve an accuracy of 88%; significantly improving on the state of the art of adversarial detection in both datasets by over 10% in all settings. We propose an anomaly detection based method using explainability techniques to detect adversarial samples which is able to generalise to different attack methods without a need for retraining.