 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Hallucinations in SpeechLLMs at Inference Time Using Attention Maps
Apr 21, 2026Hallucinations in Speech Large Language Models (SpeechLLMs) pose significant risks, yet existing detection methods typically rely on gold-standard outputs that are costly or impractical to obtain. Moreover, hallucination detection methods developed for text-based LLMs do not directly capture audio-specific signals. We investigate four attention-derived metrics: AUDIORATIO, AUDIOCONSISTENCY, AUDIOENTROPY, and TEXTENTROPY, designed to capture pathological attention patterns associated with hallucination, and train lightweight logistic regression classifiers on these features for efficient inference-time detection. Across automatic speech recognition and speech-to-text translation tasks, evaluations on Qwen-2-Audio and Voxtral-3B show that our approach outperforms uncertainty-based and prior attention-based baselines on in-domain data, achieving improvements of up to +0.23 PR-AUC, and generalises to out-of-domain ASR settings. We further find that strong performance can be achieved with approximately 100 attention heads, improving out-of-domain generalisation compared to using all heads. While effectiveness is model-dependent and task-specific training is required, our results demonstrate that attention patterns provide a valuable tool for hallucination detection in SpeechLLMs.
Fully-Automatic Pipeline for Document Signature Analysis to Detect Money Laundering Activities
Jul 29, 2021



Signatures present on corporate documents are often used in investigations of relationships between persons of interest, and prior research into the task of offline signature verification has evaluated a wide range of methods on standard signature datasets. However, such tasks often benefit from prior human supervision in the collection, adjustment and labelling of isolated signature images from which all real-world context has been removed. Signatures found in online document repositories such as the United Kingdom Companies House regularly contain high variation in location, size, quality and degrees of obfuscation under stamps. We propose an integrated pipeline of signature extraction and curation, with no human assistance from the obtaining of company documents to the clustering of individual signatures. We use a sequence of heuristic methods, convolutional neural networks, generative adversarial networks and convolutional Siamese networks for signature extraction, filtering, cleaning and embedding respectively. We evaluate both the effectiveness of the pipeline at matching obscured same-author signature pairs and the effectiveness of the entire pipeline against a human baseline for document signature analysis, as well as presenting uses for such a pipeline in the field of real-world anti-money laundering investigation.
Agree to Disagree: When Deep Learning Models With Identical Architectures Produce Distinct Explanations
May 14, 2021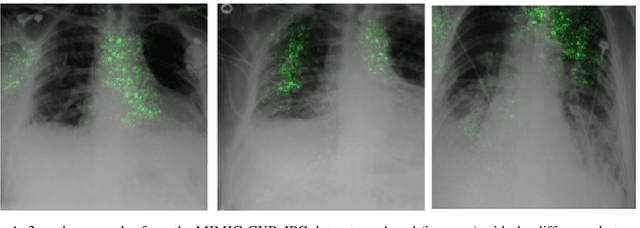
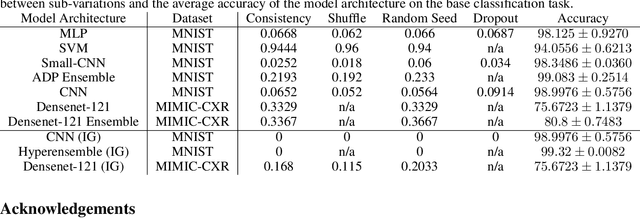
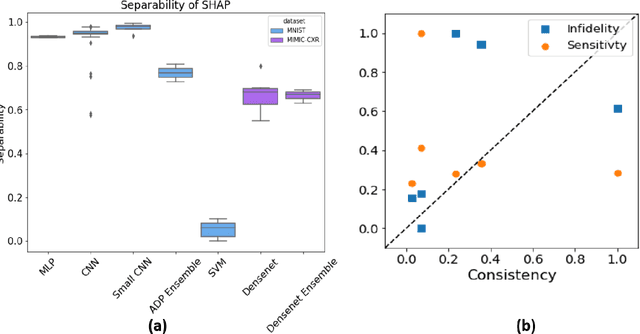
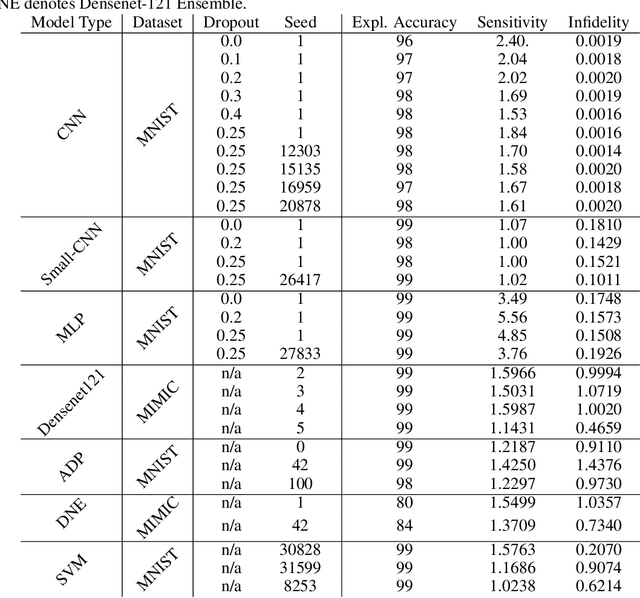
Deep Learning of neural networks has progressively become more prominent in healthcare with models reaching, or even surpassing, expert accuracy levels. However, these success stories are tainted by concerning reports on the lack of model transparency and bias against some medical conditions or patients' sub-groups. Explainable methods are considered the gateway to alleviate many of these concerns. In this study we demonstrate that the generated explanations are volatile to changes in model training that are perpendicular to the classification task and model structure. This raises further questions about trust in deep learning models for healthcare. Mainly, whether the models capture underlying causal links in the data or just rely on spurious correlations that are made visible via explanation methods. We demonstrate that the output of explainability methods on deep neural networks can vary significantly by changes of hyper-parameters, such as the random seed or how the training set is shuffled. We introduce a measure of explanation consistency which we use to highlight the identified problems on the MIMIC-CXR dataset. We find explanations of identical models but with different training setups have a low consistency: $\approx$ 33% on average. On the contrary, kernel methods are robust against any orthogonal changes, with explanation consistency at 94%. We conclude that current trends in model explanation are not sufficient to mitigate the risks of deploying models in real life healthcare applications.
Finding the Ground-Truth from Multiple Labellers: Why Parameters of the Task Matter
Feb 16, 2021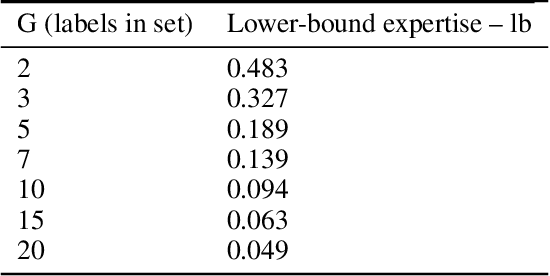
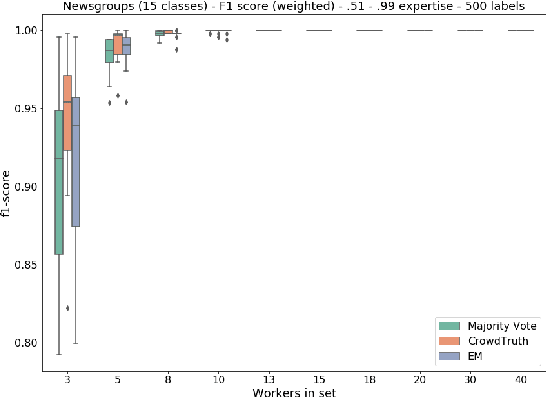
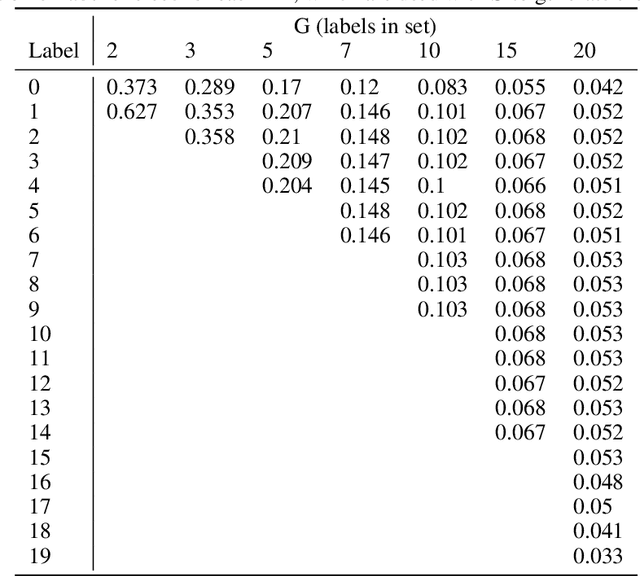
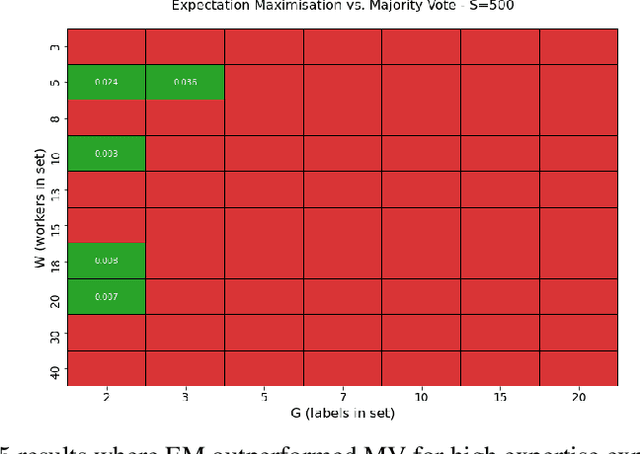
Employing multiple workers to label data for machine learning models has become increasingly important in recent years with greater demand to collect huge volumes of labelled data to train complex models while mitigating the risk of incorrect and noisy labelling. Whether it is large scale data gathering on popular crowd-sourcing platforms or smaller sets of workers in high-expertise labelling exercises, there are various methods recommended to gather a consensus from employed workers and establish ground-truth labels. However, there is very little research on how the various parameters of a labelling task can impact said methods. These parameters include the number of workers, worker expertise, number of labels in a taxonomy and sample size. In this paper, Majority Vote, CrowdTruth and Binomial Expectation Maximisation are investigated against the permutations of these parameters in order to provide better understanding of the parameter settings to give an advantage in ground-truth inference. Findings show that both Expectation Maximisation and CrowdTruth are only likely to give an advantage over majority vote under certain parameter conditions, while there are many cases where the methods can be shown to have no major impact. Guidance is given as to what parameters methods work best under, while the experimental framework provides a way of testing other established methods and also testing new methods that can attempt to provide advantageous performance where the methods in this paper did not. A greater level of understanding regarding optimal crowd-sourcing parameters is also achieved.
Bayesian Stress Testing of Models in a Classification Hierarchy
May 25, 2020
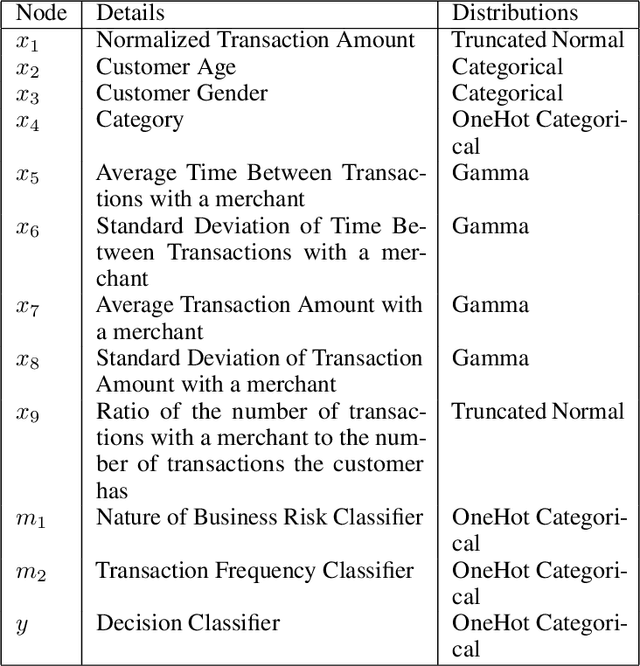


Building a machine learning solution in real-life applications often involves the decomposition of the problem into multiple models of various complexity. This has advantages in terms of overall performance, better interpretability of the outcomes, and easier model maintenance. In this work we propose a Bayesian framework to model the interaction amongst models in such a hierarchy. We show that the framework can facilitate stress testing of the overall solution, giving more confidence in its expected performance prior to active deployment. Finally, we test the proposed framework on a toy problem and financial fraud detection dataset to demonstrate how it can be applied for any machine learning based solution, regardless of the underlying modelling required.