 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the Ground-Truth from Multiple Labellers: Why Parameters of the Task Matter
Feb 16, 2021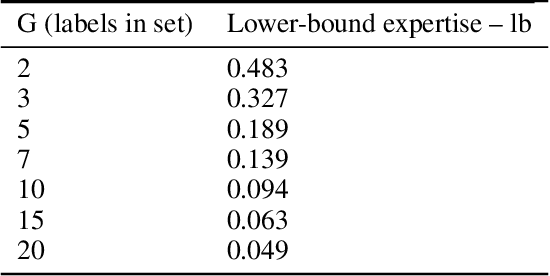
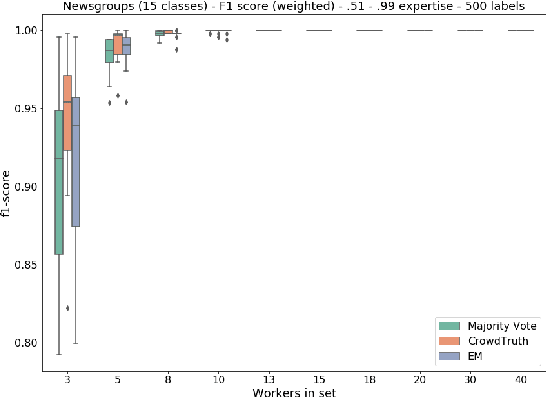
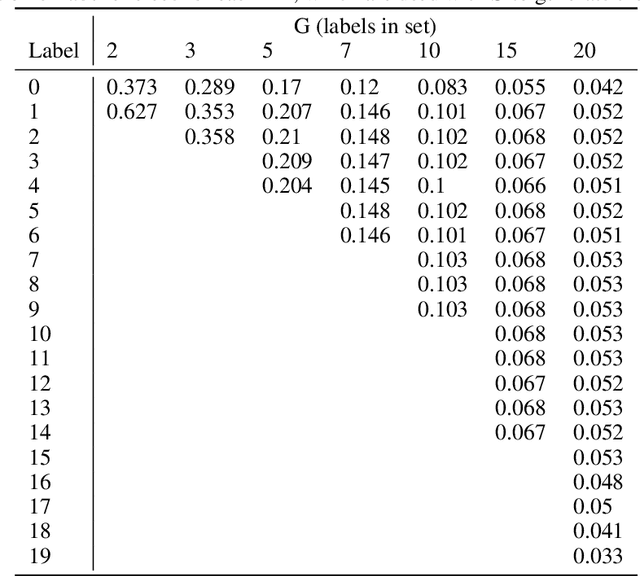
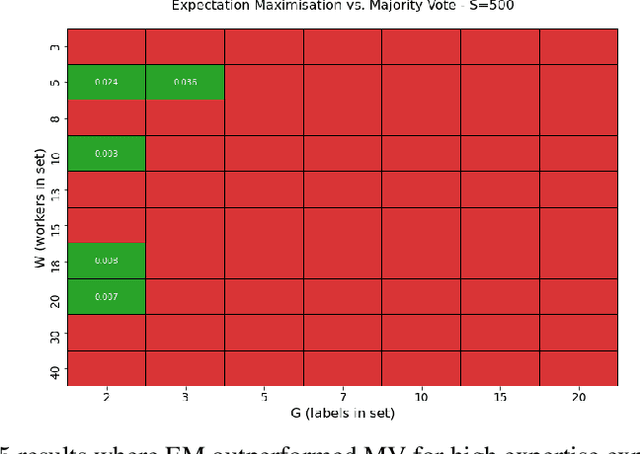
Employing multiple workers to label data for machine learning models has become increasingly important in recent years with greater demand to collect huge volumes of labelled data to train complex models while mitigating the risk of incorrect and noisy labelling. Whether it is large scale data gathering on popular crowd-sourcing platforms or smaller sets of workers in high-expertise labelling exercises, there are various methods recommended to gather a consensus from employed workers and establish ground-truth labels. However, there is very little research on how the various parameters of a labelling task can impact said methods. These parameters include the number of workers, worker expertise, number of labels in a taxonomy and sample size. In this paper, Majority Vote, CrowdTruth and Binomial Expectation Maximisation are investigated against the permutations of these parameters in order to provide better understanding of the parameter settings to give an advantage in ground-truth inference. Findings show that both Expectation Maximisation and CrowdTruth are only likely to give an advantage over majority vote under certain parameter conditions, while there are many cases where the methods can be shown to have no major impact. Guidance is given as to what parameters methods work best under, while the experimental framework provides a way of testing other established methods and also testing new methods that can attempt to provide advantageous performance where the methods in this paper did not. A greater level of understanding regarding optimal crowd-sourcing parameters is also achieved.