 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Policy Distillation with Decision-Attention
Paper and Code
Jun 08, 2024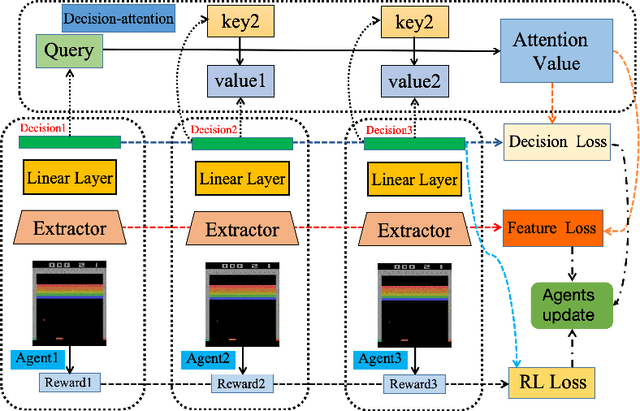
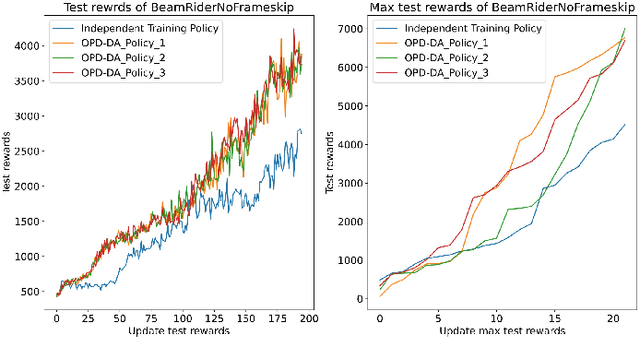
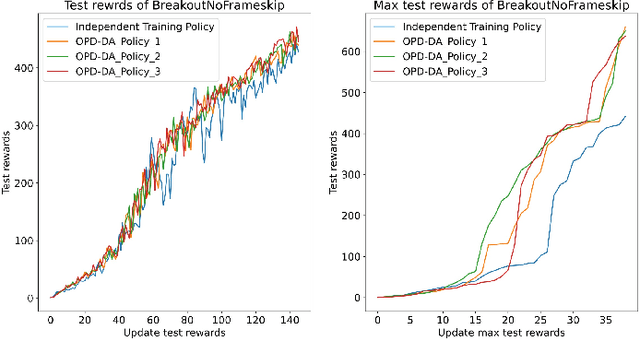
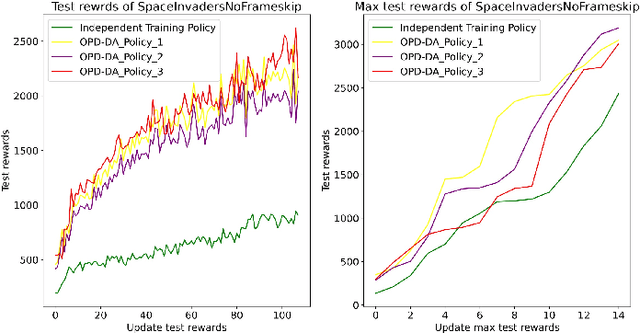
Policy Distillation (PD) has become an effective method to improve deep reinforcement learning tasks. The core idea of PD is to distill policy knowledge from a teacher agent to a student agent. However, the teacher-student framework requires a well-trained teacher model which is computationally expensive.In the light of online knowledge distillation, we study the knowledge transfer between different policies that can learn diverse knowledge from the same environment.In this work, we propose Online Policy Distillation (OPD) with Decision-Attention (DA), an online learning framework in which different policies operate in the same environment to learn different perspectives of the environment and transfer knowledge to each other to obtain better performance together. With the absence of a well-performance teacher policy, the group-derived targets play a key role in transferring group knowledge to each student policy. However, naive aggregation functions tend to cause student policies quickly homogenize. To address the challenge, we introduce the Decision-Attention module to the online policies distillation framework. The Decision-Attention module can generate a distinct set of weights for each policy to measure the importance of group members. We use the Atari platform for experiments with various reinforcement learning algorithms, including PPO and DQN. In different tasks, our method can perform better than an independent training policy on both PPO and DQN algorithms. This suggests that our OPD-DA can transfer knowledge between different policies well and help agents obtain more rewards.