 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-Guided Student Self-Knowledge Distillation Using Diffusion Model
Feb 02, 2026Existing Knowledge Distillation (KD) methods often align feature information between teacher and student by exploring meaningful feature processing and loss functions. However, due to the difference in feature distributions between the teacher and student, the student model may learn incompatible information from the teacher. To address this problem, we propose teacher-guided student Diffusion Self-KD, dubbed as DSKD. Instead of the direct teacher-student alignment, we leverage the teacher classifier to guide the sampling process of denoising student features through a light-weight diffusion model. We then propose a novel locality-sensitive hashing (LSH)-guided feature distillation method between the original and denoised student features. The denoised student features encapsulate teacher knowledge and could be regarded as a teacher role. In this way, our DSKD method could eliminate discrepancies in mapping manners and feature distributions between the teacher and student, while learning meaningful knowledge from the teacher. Experiments on visual recognition tasks demonstrate that DSKD significantly outperforms existing KD methods across various models and datasets. Our code is attached in supplementary material.
APT: Affine Prototype-Timestamp For Time Series Forecasting Under Distribution Shift
Nov 17, 2025Time series forecasting under distribution shift remains challenging, as existing deep learning models often rely on local statistical normalization (e.g., mean and variance) that fails to capture global distribution shift. Methods like RevIN and its variants attempt to decouple distribution and pattern but still struggle with missing values, noisy observations, and invalid channel-wise affine transformation. To address these limitations, we propose Affine Prototype Timestamp (APT), a lightweight and flexible plug-in module that injects global distribution features into the normalization-forecasting pipeline. By leveraging timestamp conditioned prototype learning, APT dynamically generates affine parameters that modulate both input and output series, enabling the backbone to learn from self-supervised, distribution-aware clustered instances. APT is compatible with arbitrary forecasting backbones and normalization strategies while introducing minimal computational overhead. Extensive experiments across six benchmark datasets and multiple backbone-normalization combinations demonstrate that APT significantly improves forecasting performance under distribution shift.
Merlin: Multi-View Representation Learning for Robust Multivariate Time Series Forecasting with Unfixed Missing Rates
Jun 14, 2025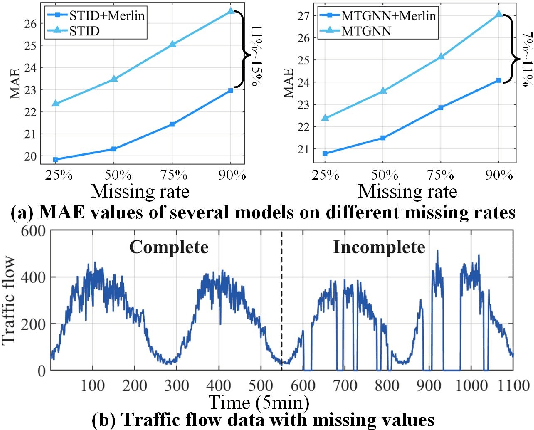
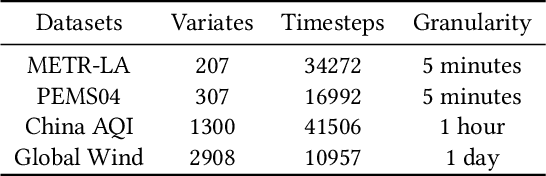
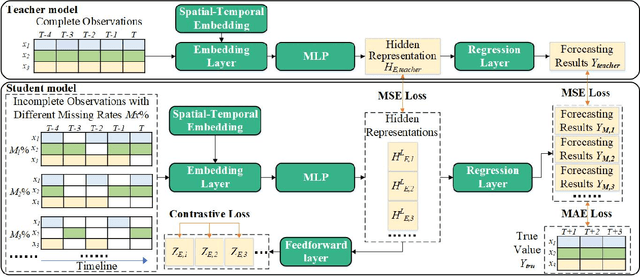
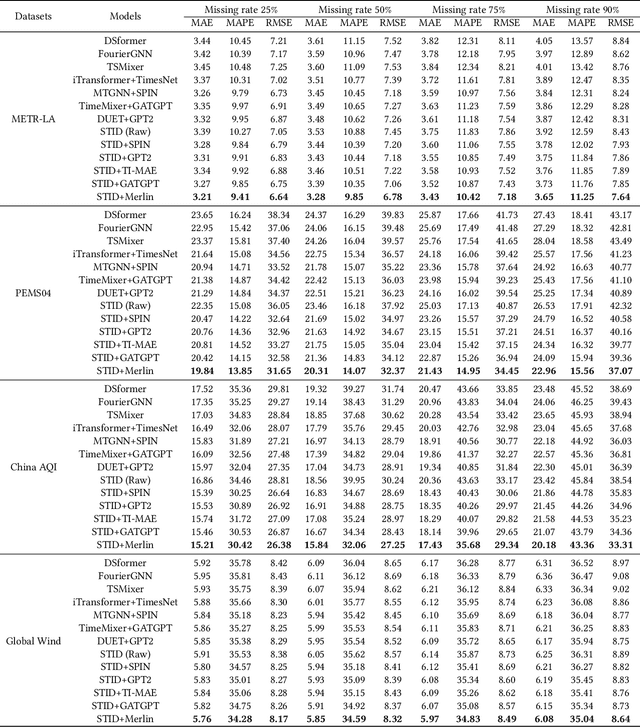
Multivariate Time Series Forecasting (MTSF) involves predicting future values of multiple interrelated time series. Recently, deep learning-based MTSF models have gained significant attention for their promising ability to mine semantics (global and local information) within MTS data. However, these models are pervasively susceptible to missing values caused by malfunctioning data collectors. These missing values not only disrupt the semantics of MTS, but their distribution also changes over time. Nevertheless, existing models lack robustness to such issues, leading to suboptimal forecasting performance. To this end, in this paper, we propose Multi-View Representation Learning (Merlin), which can help existing models achieve semantic alignment between incomplete observations with different missing rates and complete observations in MTS. Specifically, Merlin consists of two key modules: offline knowledge distillation and multi-view contrastive learning. The former utilizes a teacher model to guide a student model in mining semantics from incomplete observations, similar to those obtainable from complete observations. The latter improves the student model's robustness by learning from positive/negative data pairs constructed from incomplete observations with different missing rates, ensuring semantic alignment across different missing rates. Therefore, Merlin is capable of effectively enhancing the robustness of existing models against unfixed missing rates while preserving forecasting accuracy. Experiments on four real-world datasets demonstrate the superiority of Merlin.
BLAST: Balanced Sampling Time Series Corpus for Universal Forecasting Models
May 23, 2025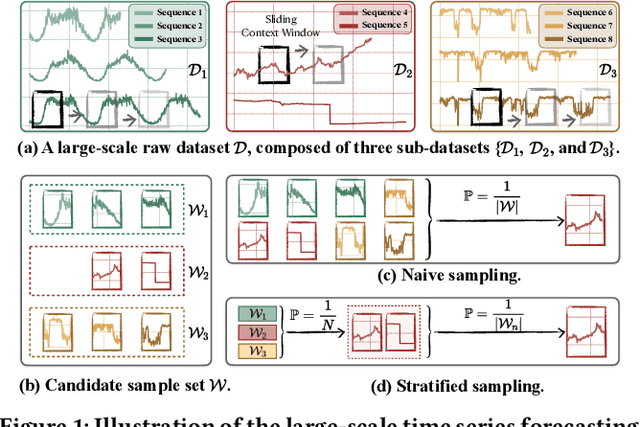
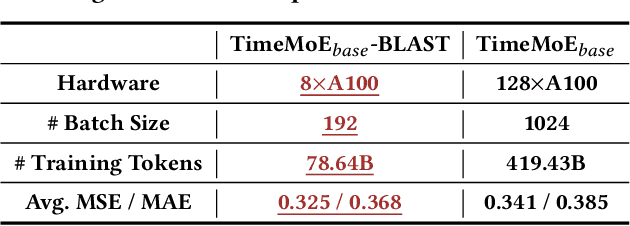
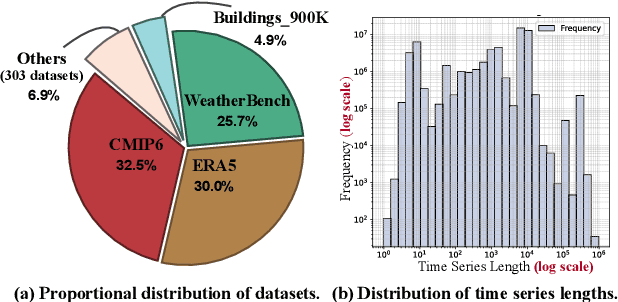
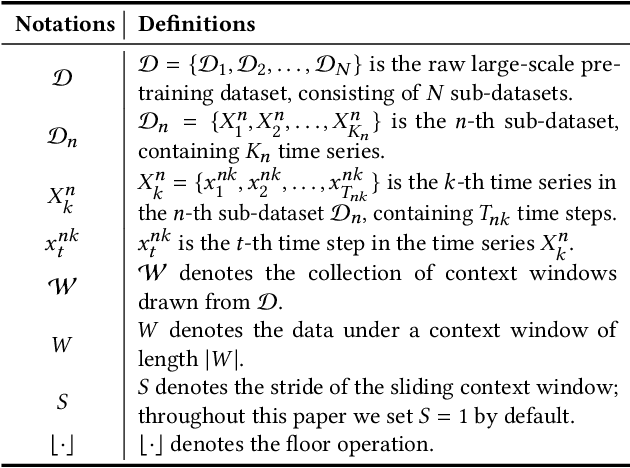
The advent of universal time series forecasting models has revolutionized zero-shot forecasting across diverse domains, yet the critical role of data diversity in training these models remains underexplored. Existing large-scale time series datasets often suffer from inherent biases and imbalanced distributions, leading to suboptimal model performance and generalization. To address this gap, we introduce BLAST, a novel pre-training corpus designed to enhance data diversity through a balanced sampling strategy. First, BLAST incorporates 321 billion observations from publicly available datasets and employs a comprehensive suite of statistical metrics to characterize time series patterns. Then, to facilitate pattern-oriented sampling, the data is implicitly clustered using grid-based partitioning. Furthermore, by integrating grid sampling and grid mixup techniques, BLAST ensures a balanced and representative coverage of diverse patterns. Experimental results demonstrate that models pre-trained on BLAST achieve state-of-the-art performance with a fraction of the computational resources and training tokens required by existing methods. Our findings highlight the pivotal role of data diversity in improving both training efficiency and model performance for the universal forecasting task.
Multi-Teacher Knowledge Distillation with Reinforcement Learning for Visual Recognition
Feb 22, 2025Multi-teacher Knowledge Distillation (KD) transfers diverse knowledge from a teacher pool to a student network. The core problem of multi-teacher KD is how to balance distillation strengths among various teachers. Most existing methods often develop weighting strategies from an individual perspective of teacher performance or teacher-student gaps, lacking comprehensive information for guidance. This paper proposes Multi-Teacher Knowledge Distillation with Reinforcement Learning (MTKD-RL) to optimize multi-teacher weights. In this framework, we construct both teacher performance and teacher-student gaps as state information to an agent. The agent outputs the teacher weight and can be updated by the return reward from the student. MTKD-RL reinforces the interaction between the student and teacher using an agent in an RL-based decision mechanism, achieving better matching capability with more meaningful weights. Experimental results on visual recognition tasks, including image classification, object detection, and semantic segmentation tasks, demonstrate that MTKD-RL achieves state-of-the-art performance compared to the existing multi-teacher KD works.
LightWeather: Harnessing Absolute Positional Encoding to Efficient and Scalable Global Weather Forecasting
Aug 19, 2024



Recently, Transformers have gained traction in weather forecasting for their capability to capture long-term spatial-temporal correlations. However, their complex architectures result in large parameter counts and extended training times, limiting their practical application and scalability to global-scale forecasting. This paper aims to explore the key factor for accurate weather forecasting and design more efficient solutions. Interestingly, our empirical findings reveal that absolute positional encoding is what really works in Transformer-based weather forecasting models, which can explicitly model the spatial-temporal correlations even without attention mechanisms. We theoretically prove that its effectiveness stems from the integration of geographical coordinates and real-world time features, which are intrinsically related to the dynamics of weather. Based on this, we propose LightWeather, a lightweight and effective model for station-based global weather forecasting. We employ absolute positional encoding and a simple MLP in place of other components of Transformer. With under 30k parameters and less than one hour of training time, LightWeather achieves state-of-the-art performance on global weather datasets compared to other advanced DL methods. The results underscore the superiority of integrating spatial-temporal knowledge over complex architectures, providing novel insights for DL in weather forecasting.
Online Policy Distillation with Decision-Attention
Jun 08, 2024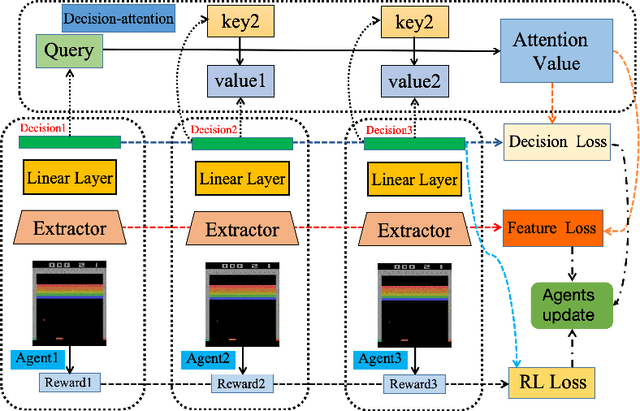
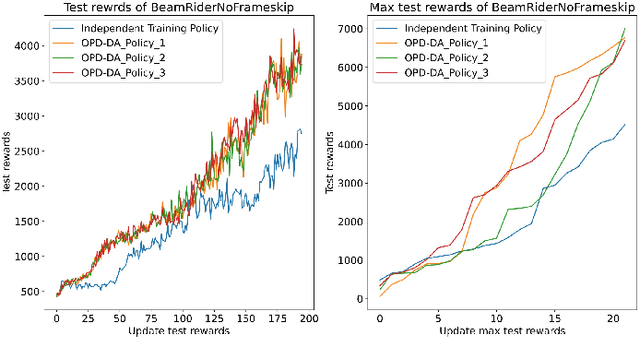
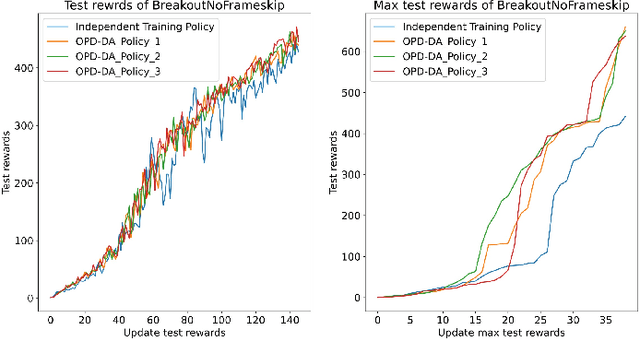
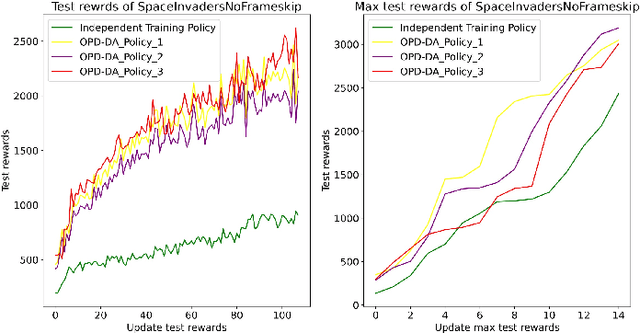
Policy Distillation (PD) has become an effective method to improve deep reinforcement learning tasks. The core idea of PD is to distill policy knowledge from a teacher agent to a student agent. However, the teacher-student framework requires a well-trained teacher model which is computationally expensive.In the light of online knowledge distillation, we study the knowledge transfer between different policies that can learn diverse knowledge from the same environment.In this work, we propose Online Policy Distillation (OPD) with Decision-Attention (DA), an online learning framework in which different policies operate in the same environment to learn different perspectives of the environment and transfer knowledge to each other to obtain better performance together. With the absence of a well-performance teacher policy, the group-derived targets play a key role in transferring group knowledge to each student policy. However, naive aggregation functions tend to cause student policies quickly homogenize. To address the challenge, we introduce the Decision-Attention module to the online policies distillation framework. The Decision-Attention module can generate a distinct set of weights for each policy to measure the importance of group members. We use the Atari platform for experiments with various reinforcement learning algorithms, including PPO and DQN. In different tasks, our method can perform better than an independent training policy on both PPO and DQN algorithms. This suggests that our OPD-DA can transfer knowledge between different policies well and help agents obtain more rewards.
GinAR: An End-To-End Multivariate Time Series Forecasting Model Suitable for Variable Missing
May 18, 2024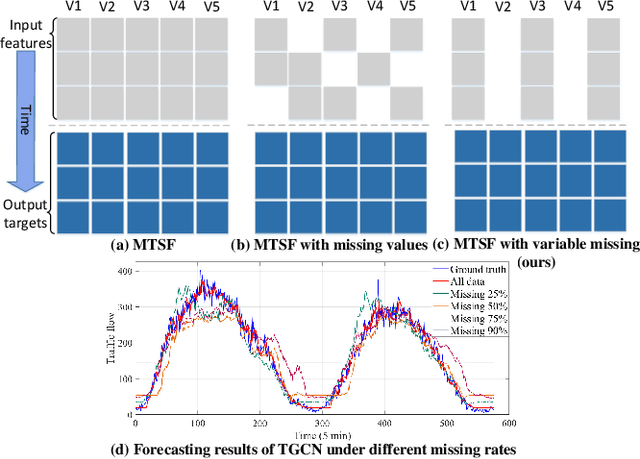
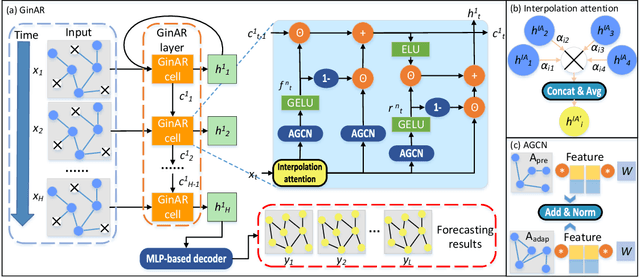
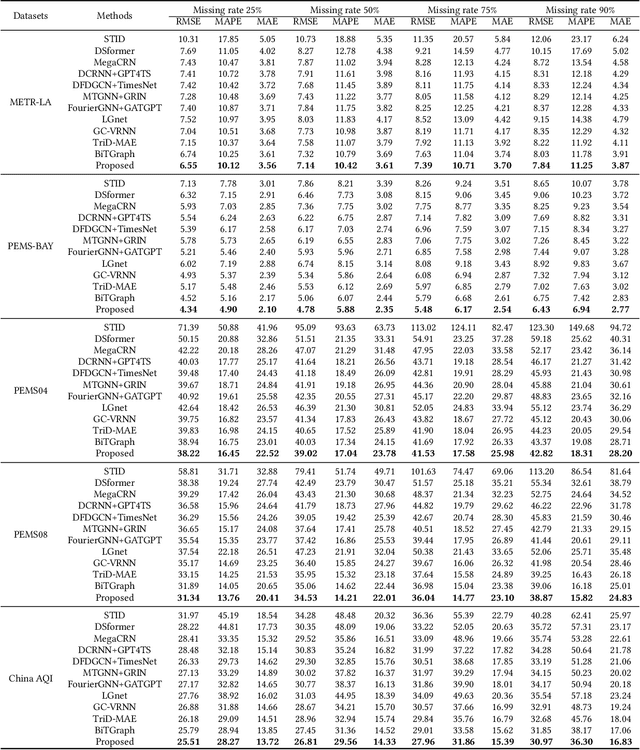
Multivariate time series forecasting (MTSF) is crucial for decision-making to precisely forecast the future values/trends, based on the complex relationships identified from historical observations of multiple sequences. Recently, Spatial-Temporal Graph Neural Networks (STGNNs) have gradually become the theme of MTSF model as their powerful capability in mining spatial-temporal dependencies, but almost of them heavily rely on the assumption of historical data integrity. In reality, due to factors such as data collector failures and time-consuming repairment, it is extremely challenging to collect the whole historical observations without missing any variable. In this case, STGNNs can only utilize a subset of normal variables and easily suffer from the incorrect spatial-temporal dependency modeling issue, resulting in the degradation of their forecasting performance. To address the problem, in this paper, we propose a novel Graph Interpolation Attention Recursive Network (named GinAR) to precisely model the spatial-temporal dependencies over the limited collected data for forecasting. In GinAR, it consists of two key components, that is, interpolation attention and adaptive graph convolution to take place of the fully connected layer of simple recursive units, and thus are capable of recovering all missing variables and reconstructing the correct spatial-temporal dependencies for recursively modeling of multivariate time series data, respectively. Extensive experiments conducted on five real-world datasets demonstrate that GinAR outperforms 11 SOTA baselines, and even when 90% of variables are missing, it can still accurately predict the future values of all variables.
Exploring Progress in Multivariate Time Series Forecasting: Comprehensive Benchmarking and Heterogeneity Analysis
Oct 09, 2023Multivariate Time Series (MTS) widely exists in real-word complex systems, such as traffic and energy systems, making their forecasting crucial for understanding and influencing these systems. Recently, deep learning-based approaches have gained much popularity for effectively modeling temporal and spatial dependencies in MTS, specifically in Long-term Time Series Forecasting (LTSF) and Spatial-Temporal Forecasting (STF). However, the fair benchmarking issue and the choice of technical approaches have been hotly debated in related work. Such controversies significantly hinder our understanding of progress in this field. Thus, this paper aims to address these controversies to present insights into advancements achieved. To resolve benchmarking issues, we introduce BasicTS, a benchmark designed for fair comparisons in MTS forecasting. BasicTS establishes a unified training pipeline and reasonable evaluation settings, enabling an unbiased evaluation of over 30 popular MTS forecasting models on more than 18 datasets. Furthermore, we highlight the heterogeneity among MTS datasets and classify them based on temporal and spatial characteristics. We further prove that neglecting heterogeneity is the primary reason for generating controversies in technical approaches. Moreover, based on the proposed BasicTS and rich heterogeneous MTS datasets, we conduct an exhaustive and reproducible performance and efficiency comparison of popular models, providing insights for researchers in selecting and designing MTS forecasting models.
DSformer: A Double Sampling Transformer for Multivariate Time Series Long-term Prediction
Aug 07, 2023Multivariate time series long-term prediction, which aims to predict the change of data in a long time, can provide references for decision-making. Although transformer-based models have made progress in this field, they usually do not make full use of three features of multivariate time series: global information, local information, and variables correlation. To effectively mine the above three features and establish a high-precision prediction model, we propose a double sampling transformer (DSformer), which consists of the double sampling (DS) block and the temporal variable attention (TVA) block. Firstly, the DS block employs down sampling and piecewise sampling to transform the original series into feature vectors that focus on global information and local information respectively. Then, TVA block uses temporal attention and variable attention to mine these feature vectors from different dimensions and extract key information. Finally, based on a parallel structure, DSformer uses multiple TVA blocks to mine and integrate different features obtained from DS blocks respectively. The integrated feature information is passed to the generative decoder based on a multi-layer perceptron to realize multivariate time series long-term prediction. Experimental results on nine real-world datasets show that DSformer can outperform eight existing baselines.