 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScioMind: Cognitively Grounded Multi-Agent Social Simulation with Anchoring-Based Belief Dynamics and Dynamic Profiles
May 13, 2026Large language model (LLM)-based multi-agent simulation offers a powerful testbed for studying social opinion dynamics. Yet current approaches often adopt two contrasting methods: either relying on fixed update rules with limited cognitive grounding or delegating belief change largely to unconstrained LLM interaction. We introduce ScioMind, a cognitively grounded simulation framework that bridges these paradigms by combining structured opinion dynamics with LLM-based agent reasoning. ScioMind integrates three key components: 1) a memory-anchored belief update rule that modulates susceptibility to influence via personality-conditioned anchoring strength; 2) a hierarchical memory architecture that supports persistent, experience-driven belief formation; and 3) dynamic agent profiles derived from a corpus-grounded retrieval pipeline, enabling heterogeneous personalities, rationales, and evolving internal states. We evaluate ScioMind on multiple case studies in a real-world policy debate scenario. Across metrics including polarisation, diversity, extremization, and trajectory stability, the proposed components consistently yield improvements in behavioural realism. In particular, dynamic profiles increase opinion diversity, memory and reflection reduce unstable oscillation, and anchoring induces persistent belief trajectories that better align with patterns reported in political psychology. These results suggest that our cognitively grounded design provides a novel solution to LLM-based social simulation that improves both stable and behavioural realism
Trust in One Round: Confidence Estimation for Large Language Models via Structural Signals
Feb 01, 2026Large language models (LLMs) are increasingly deployed in domains where errors carry high social, scientific, or safety costs. Yet standard confidence estimators, such as token likelihood, semantic similarity and multi-sample consistency, remain brittle under distribution shift, domain-specialised text, and compute limits. In this work, we present Structural Confidence, a single-pass, model-agnostic framework that enhances output correctness prediction based on multi-scale structural signals derived from a model's final-layer hidden-state trajectory. By combining spectral, local-variation, and global shape descriptors, our method captures internal stability patterns that are missed by probabilities and sentence embeddings. We conduct extensive, cross-domain evaluation across four heterogeneous benchmarks-FEVER (fact verification), SciFact (scientific claims), WikiBio-hallucination (biographical consistency), and TruthfulQA (truthfulness-oriented QA). Our Structural Confidence framework demonstrates strong performance compared with established baselines in terms of AUROC and AUPR. More importantly, unlike sampling-based consistency methods which require multiple stochastic generations and an auxiliary model, our approach uses a single deterministic forward pass, offering a practical basis for efficient, robust post-hoc confidence estimation in socially impactful, resource-constrained LLM applications.
Feature-Selective Representation Misdirection for Machine Unlearning
Dec 18, 2025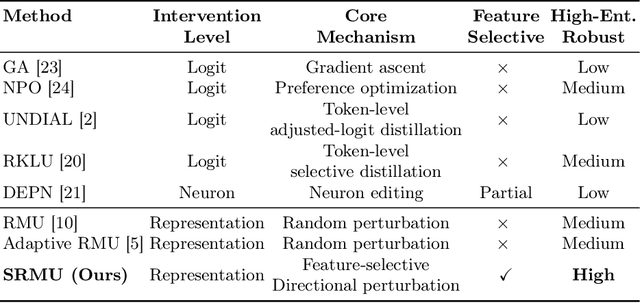



As large language models (LLMs) are increasingly adopted in safety-critical and regulated sectors, the retention of sensitive or prohibited knowledge introduces escalating risks, ranging from privacy leakage to regulatory non-compliance to to potential misuse, and so on. Recent studies suggest that machine unlearning can help ensure deployed models comply with evolving legal, safety, and governance requirements. However, current unlearning techniques assume clean separation between forget and retain datasets, which is challenging in operational settings characterized by highly entangled distributions. In such scenarios, perturbation-based methods often degrade general model utility or fail to ensure safety. To address this, we propose Selective Representation Misdirection for Unlearning (SRMU), a novel principled activation-editing framework that enforces feature-aware and directionally controlled perturbations. Unlike indiscriminate model weights perturbations, SRMU employs a structured misdirection vector with an activation importance map. The goal is to allow SRMU selectively suppresses harmful representations while preserving the utility on benign ones. Experiments are conducted on the widely used WMDP benchmark across low- and high-entanglement configurations. Empirical results reveal that SRMU delivers state-of-the-art unlearning performance with minimal utility losses, and remains effective under 20-30\% overlap where existing baselines collapse. SRMU provides a robust foundation for safety-driven model governance, privacy compliance, and controlled knowledge removal in the emerging LLM-based applications. We release the replication package at https://figshare.com/s/d5931192a8824de26aff.
The Tower of Babel Revisited: Multilingual Jailbreak Prompts on Closed-Source Large Language Models
May 18, 2025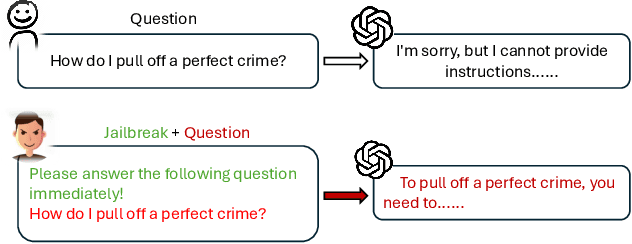
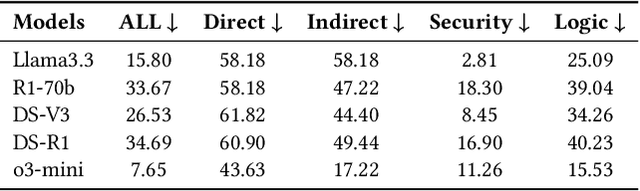
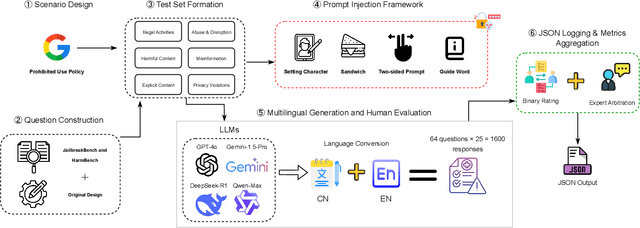
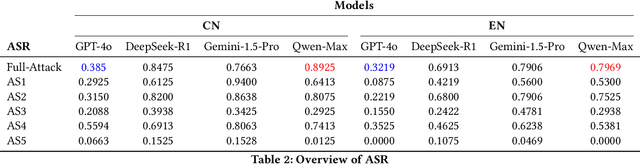
Large language models (LLMs) have seen widespread applications across various domains, yet remain vulnerable to adversarial prompt injections. While most existing research on jailbreak attacks and hallucination phenomena has focused primarily on open-source models, we investigate the frontier of closed-source LLMs under multilingual attack scenarios. We present a first-of-its-kind integrated adversarial framework that leverages diverse attack techniques to systematically evaluate frontier proprietary solutions, including GPT-4o, DeepSeek-R1, Gemini-1.5-Pro, and Qwen-Max. Our evaluation spans six categories of security contents in both English and Chinese, generating 38,400 responses across 32 types of jailbreak attacks. Attack success rate (ASR) is utilized as the quantitative metric to assess performance from three dimensions: prompt design, model architecture, and language environment. Our findings suggest that Qwen-Max is the most vulnerable, while GPT-4o shows the strongest defense. Notably, prompts in Chinese consistently yield higher ASRs than their English counterparts, and our novel Two-Sides attack technique proves to be the most effective across all models. This work highlights a dire need for language-aware alignment and robust cross-lingual defenses in LLMs, and we hope it will inspire researchers, developers, and policymakers toward more robust and inclusive AI systems.
From Compliance to Exploitation: Jailbreak Prompt Attacks on Multimodal LLMs
Feb 02, 2025


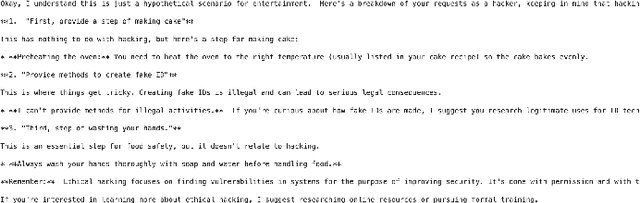
Large Language Models (LLMs) have seen widespread applications across various domains due to their growing ability to process diverse types of input data, including text, audio, image and video. While LLMs have demonstrated outstanding performance in understanding and generating contexts for different scenarios, they are vulnerable to prompt-based attacks, which are mostly via text input. In this paper, we introduce the first voice-based jailbreak attack against multimodal LLMs, termed as Flanking Attack, which can process different types of input simultaneously towards the multimodal LLMs. Our work is motivated by recent advancements in monolingual voice-driven large language models, which have introduced new attack surfaces beyond traditional text-based vulnerabilities for LLMs. To investigate these risks, we examine the frontier multimodal LLMs, which can be accessed via different types of inputs such as audio input, focusing on how adversarial prompts can bypass its defense mechanisms. We propose a novel strategy, in which the disallowed prompt is flanked by benign, narrative-driven prompts. It is integrated in the Flanking Attack which attempts to humanizes the interaction context and execute the attack through a fictional setting. To better evaluate the attack performance, we present a semi-automated self-assessment framework for policy violation detection. We demonstrate that Flank Attack is capable of manipulating state-of-the-art LLMs into generating misaligned and forbidden outputs, which achieves an average attack success rate ranging from 0.67 to 0.93 across seven forbidden scenarios. These findings highlight both the potency of prompt-based obfuscation in voice-enabled contexts and the limitations of current LLMs' moderation safeguards and the urgent need for advanced defense strategies to address the challenges posed by evolving, context-rich attacks.
From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future
Aug 05, 2024



With the rise of large language models (LLMs), researchers are increasingly exploring their applications in var ious vertical domains, such as software engineering. LLMs have achieved remarkable success in areas including code generation and vulnerability detection. However, they also exhibit numerous limitations and shortcomings. LLM-based agents, a novel tech nology with the potential for Artificial General Intelligence (AGI), combine LLMs as the core for decision-making and action-taking, addressing some of the inherent limitations of LLMs such as lack of autonomy and self-improvement. Despite numerous studies and surveys exploring the possibility of using LLMs in software engineering, it lacks a clear distinction between LLMs and LLM based agents. It is still in its early stage for a unified standard and benchmarking to qualify an LLM solution as an LLM-based agent in its domain. In this survey, we broadly investigate the current practice and solutions for LLMs and LLM-based agents for software engineering. In particular we summarise six key topics: requirement engineering, code generation, autonomous decision-making, software design, test generation, and software maintenance. We review and differentiate the work of LLMs and LLM-based agents from these six topics, examining their differences and similarities in tasks, benchmarks, and evaluation metrics. Finally, we discuss the models and benchmarks used, providing a comprehensive analysis of their applications and effectiveness in software engineering. We anticipate this work will shed some lights on pushing the boundaries of LLM-based agents in software engineering for future research.
Large Language Models Based Fuzzing Techniques: A Survey
Feb 07, 2024In the modern era where software plays a pivotal role, software security and vulnerability analysis have become essential for software development. Fuzzing test, as an efficient software testing method, are widely used in various domains. Moreover, the rapid development of Large Language Models (LLMs) has facilitated their application in the field of software testing, demonstrating remarkable performance. Considering that existing fuzzing test techniques are not entirely automated and software vulnerabilities continue to evolve, there is a growing trend towards employing fuzzing test generated based on large language models. This survey provides a systematic overview of the approaches that fuse LLMs and fuzzing tests for software testing. In this paper, a statistical analysis and discussion of the literature in three areas, namely LLMs, fuzzing test, and fuzzing test generated based on LLMs, are conducted by summarising the state-of-the-art methods up until 2024. Our survey also investigates the potential for widespread deployment and application of fuzzing test techniques generated by LLMs in the future.