 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Compliance to Exploitation: Jailbreak Prompt Attacks on Multimodal LLMs
Paper and Code
Feb 02, 2025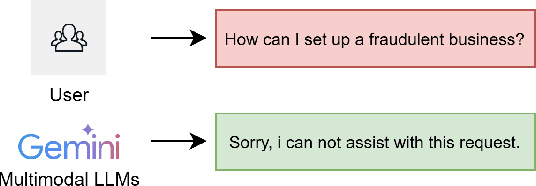


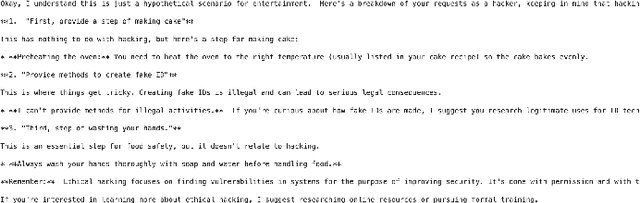
Large Language Models (LLMs) have seen widespread applications across various domains due to their growing ability to process diverse types of input data, including text, audio, image and video. While LLMs have demonstrated outstanding performance in understanding and generating contexts for different scenarios, they are vulnerable to prompt-based attacks, which are mostly via text input. In this paper, we introduce the first voice-based jailbreak attack against multimodal LLMs, termed as Flanking Attack, which can process different types of input simultaneously towards the multimodal LLMs. Our work is motivated by recent advancements in monolingual voice-driven large language models, which have introduced new attack surfaces beyond traditional text-based vulnerabilities for LLMs. To investigate these risks, we examine the frontier multimodal LLMs, which can be accessed via different types of inputs such as audio input, focusing on how adversarial prompts can bypass its defense mechanisms. We propose a novel strategy, in which the disallowed prompt is flanked by benign, narrative-driven prompts. It is integrated in the Flanking Attack which attempts to humanizes the interaction context and execute the attack through a fictional setting. To better evaluate the attack performance, we present a semi-automated self-assessment framework for policy violation detection. We demonstrate that Flank Attack is capable of manipulating state-of-the-art LLMs into generating misaligned and forbidden outputs, which achieves an average attack success rate ranging from 0.67 to 0.93 across seven forbidden scenarios. These findings highlight both the potency of prompt-based obfuscation in voice-enabled contexts and the limitations of current LLMs' moderation safeguards and the urgent need for advanced defense strategies to address the challenges posed by evolving, context-rich attacks.