 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study On Mixup-inspired Augmentation Methods For Software Vulnerability Detection
Apr 22, 2025Various Deep Learning (DL) methods have recently been utilized to detect software vulnerabilities. Real-world software vulnerability datasets are rare and hard to acquire as there's no simple metric for classifying vulnerability. Such datasets are heavily imbalanced, and none of the current datasets are considered huge for DL models. To tackle these problems a recent work has tried to augment the dataset using the source code and generate realistic single-statement vulnerabilities which is not quite practical and requires manual checking of the generated vulnerabilities. In this regard, we aim to explore the augmentation of vulnerabilities at the representation level to help current models learn better which has never been done before to the best of our knowledge. We implement and evaluate the 5 augmentation techniques that augment the embedding of the data and recently have been used for code search which is a completely different software engineering task. We also introduced a conditioned version of those augmentation methods, which ensures the augmentation does not change the vulnerable section of the vector representation. We show that such augmentation methods can be helpful and increase the f1-score by up to 9.67%, yet they cannot beat Random Oversampling when balancing datasets which increases the f1-score by 10.82%!
GUI Element Detection Using SOTA YOLO Deep Learning Models
Aug 07, 2024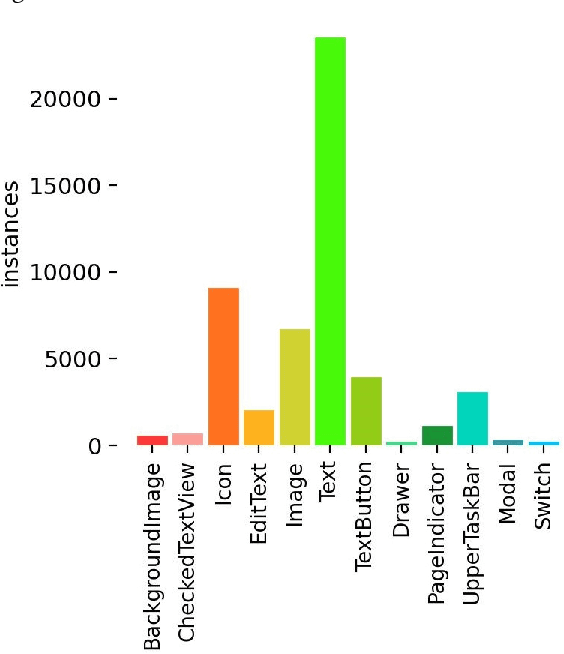



Detection of Graphical User Interface (GUI) elements is a crucial task for automatic code generation from images and sketches, GUI testing, and GUI search. Recent studies have leveraged both old-fashioned and modern computer vision (CV) techniques. Oldfashioned methods utilize classic image processing algorithms (e.g. edge detection and contour detection) and modern methods use mature deep learning solutions for general object detection tasks. GUI element detection, however, is a domain-specific case of object detection, in which objects overlap more often, and are located very close to each other, plus the number of object classes is considerably lower, yet there are more objects in the images compared to natural images. Hence, the studies that have been carried out on comparing various object detection models, might not apply to GUI element detection. In this study, we evaluate the performance of the four most recent successful YOLO models for general object detection tasks on GUI element detection and investigate their accuracy performance in detecting various GUI elements.
Exploring RAG-based Vulnerability Augmentation with LLMs
Aug 07, 2024

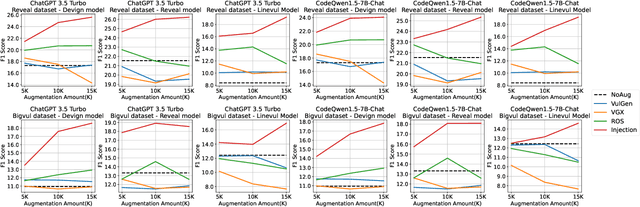
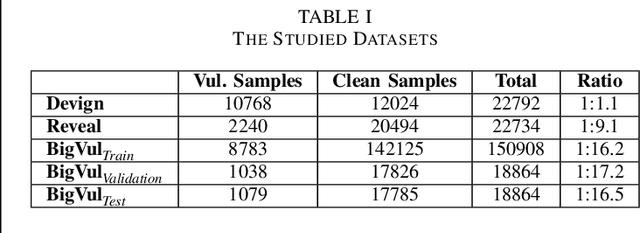
Detecting vulnerabilities is a crucial task for maintaining the integrity, availability, and security of software systems. Utilizing DL-based models for vulnerability detection has become commonplace in recent years. However, such deep learning-based vulnerability detectors (DLVD) suffer from a shortage of sizable datasets to train effectively. Data augmentation can potentially alleviate the shortage of data, but augmenting vulnerable code is challenging and requires designing a generative solution that maintains vulnerability. Hence, the work on generating vulnerable code samples has been limited and previous works have only focused on generating samples that contain single statements or specific types of vulnerabilities. Lately, large language models (LLMs) are being used for solving various code generation and comprehension tasks and have shown inspiring results, especially when fused with retrieval augmented generation (RAG). In this study, we explore three different strategies to augment vulnerabilities both single and multi-statement vulnerabilities, with LLMs, namely Mutation, Injection, and Extension. We conducted an extensive evaluation of our proposed approach on three vulnerability datasets and three DLVD models, using two LLMs. Our results show that our injection-based clustering-enhanced RAG method beats the baseline setting (NoAug), Vulgen, and VGX (two SOTA methods), and Random Oversampling (ROS) by 30.80\%, 27.48\%, 27.93\%, and 15.41\% in f1-score with 5K generated vulnerable samples on average, and 53.84\%, 54.10\%, 69.90\%, and 40.93\% with 15K generated vulnerable samples. Our approach demonstrates its feasibility for large-scale data augmentation by generating 1K samples at as cheap as US$ 1.88.