 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study On Mixup-inspired Augmentation Methods For Software Vulnerability Detection
Apr 22, 2025Various Deep Learning (DL) methods have recently been utilized to detect software vulnerabilities. Real-world software vulnerability datasets are rare and hard to acquire as there's no simple metric for classifying vulnerability. Such datasets are heavily imbalanced, and none of the current datasets are considered huge for DL models. To tackle these problems a recent work has tried to augment the dataset using the source code and generate realistic single-statement vulnerabilities which is not quite practical and requires manual checking of the generated vulnerabilities. In this regard, we aim to explore the augmentation of vulnerabilities at the representation level to help current models learn better which has never been done before to the best of our knowledge. We implement and evaluate the 5 augmentation techniques that augment the embedding of the data and recently have been used for code search which is a completely different software engineering task. We also introduced a conditioned version of those augmentation methods, which ensures the augmentation does not change the vulnerable section of the vector representation. We show that such augmentation methods can be helpful and increase the f1-score by up to 9.67%, yet they cannot beat Random Oversampling when balancing datasets which increases the f1-score by 10.82%!
SoK: Prompt Hacking of Large Language Models
Oct 16, 2024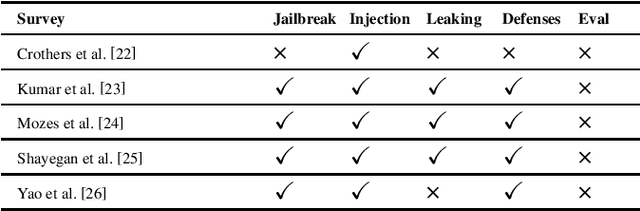



The safety and robustness of large language models (LLMs) based applications remain critical challenges in artificial intelligence. Among the key threats to these applications are prompt hacking attacks, which can significantly undermine the security and reliability of LLM-based systems. In this work, we offer a comprehensive and systematic overview of three distinct types of prompt hacking: jailbreaking, leaking, and injection, addressing the nuances that differentiate them despite their overlapping characteristics. To enhance the evaluation of LLM-based applications, we propose a novel framework that categorizes LLM responses into five distinct classes, moving beyond the traditional binary classification. This approach provides more granular insights into the AI's behavior, improving diagnostic precision and enabling more targeted enhancements to the system's safety and robustness.
Handwritten Word Recognition using Deep Learning Approach: A Novel Way of Generating Handwritten Words
Mar 13, 2023



A handwritten word recognition system comes with issues such as lack of large and diverse datasets. It is necessary to resolve such issues since millions of official documents can be digitized by training deep learning models using a large and diverse dataset. Due to the lack of data availability, the trained model does not give the expected result. Thus, it has a high chance of showing poor results. This paper proposes a novel way of generating diverse handwritten word images using handwritten characters. The idea of our project is to train the BiLSTM-CTC architecture with generated synthetic handwritten words. The whole approach shows the process of generating two types of large and diverse handwritten word datasets: overlapped and non-overlapped. Since handwritten words also have issues like overlapping between two characters, we have tried to put it into our experimental part. We have also demonstrated the process of recognizing handwritten documents using the deep learning model. For the experiments, we have targeted the Bangla language, which lacks the handwritten word dataset, and can be followed for any language. Our approach is less complex and less costly than traditional GAN models. Finally, we have evaluated our model using Word Error Rate (WER), accuracy, f1-score, precision, and recall metrics. The model gives 39% WER score, 92% percent accuracy, and 92% percent f1 scores using non-overlapped data and 63% percent WER score, 83% percent accuracy, and 85% percent f1 scores using overlapped data.