 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative diffusion models for agricultural AI: plant image generation, indoor-to-outdoor translation, and expert preference alignment
Dec 22, 2025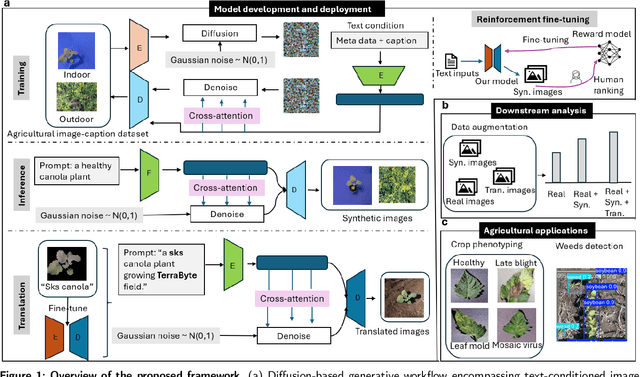
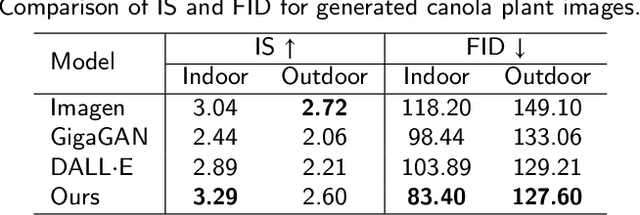
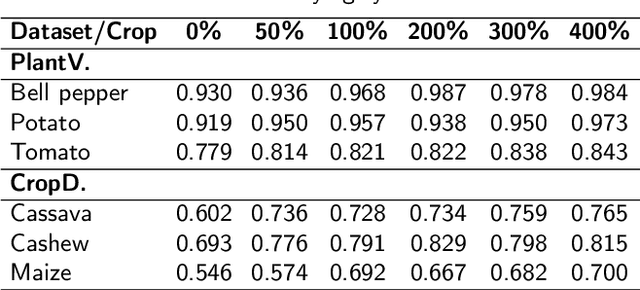
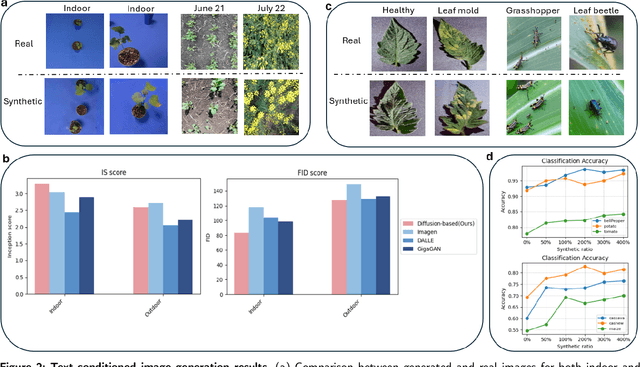
The success of agricultural artificial intelligence depends heavily on large, diverse, and high-quality plant image datasets, yet collecting such data in real field conditions is costly, labor intensive, and seasonally constrained. This paper investigates diffusion-based generative modeling to address these challenges through plant image synthesis, indoor-to-outdoor translation, and expert preference aligned fine tuning. First, a Stable Diffusion model is fine tuned on captioned indoor and outdoor plant imagery to generate realistic, text conditioned images of canola and soybean. Evaluation using Inception Score, Frechet Inception Distance, and downstream phenotype classification shows that synthetic images effectively augment training data and improve accuracy. Second, we bridge the gap between high resolution indoor datasets and limited outdoor imagery using DreamBooth-based text inversion and image guided diffusion, generating translated images that enhance weed detection and classification with YOLOv8. Finally, a preference guided fine tuning framework trains a reward model on expert scores and applies reward weighted updates to produce more stable and expert aligned outputs. Together, these components demonstrate a practical pathway toward data efficient generative pipelines for agricultural AI.
A Study On Mixup-inspired Augmentation Methods For Software Vulnerability Detection
Apr 22, 2025Various Deep Learning (DL) methods have recently been utilized to detect software vulnerabilities. Real-world software vulnerability datasets are rare and hard to acquire as there's no simple metric for classifying vulnerability. Such datasets are heavily imbalanced, and none of the current datasets are considered huge for DL models. To tackle these problems a recent work has tried to augment the dataset using the source code and generate realistic single-statement vulnerabilities which is not quite practical and requires manual checking of the generated vulnerabilities. In this regard, we aim to explore the augmentation of vulnerabilities at the representation level to help current models learn better which has never been done before to the best of our knowledge. We implement and evaluate the 5 augmentation techniques that augment the embedding of the data and recently have been used for code search which is a completely different software engineering task. We also introduced a conditioned version of those augmentation methods, which ensures the augmentation does not change the vulnerable section of the vector representation. We show that such augmentation methods can be helpful and increase the f1-score by up to 9.67%, yet they cannot beat Random Oversampling when balancing datasets which increases the f1-score by 10.82%!