 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Prompt Hacking of Large Language Models
Paper and Code
Oct 16, 2024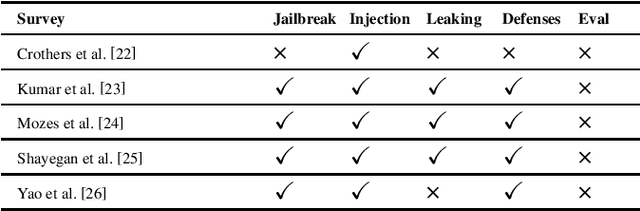



The safety and robustness of large language models (LLMs) based applications remain critical challenges in artificial intelligence. Among the key threats to these applications are prompt hacking attacks, which can significantly undermine the security and reliability of LLM-based systems. In this work, we offer a comprehensive and systematic overview of three distinct types of prompt hacking: jailbreaking, leaking, and injection, addressing the nuances that differentiate them despite their overlapping characteristics. To enhance the evaluation of LLM-based applications, we propose a novel framework that categorizes LLM responses into five distinct classes, moving beyond the traditional binary classification. This approach provides more granular insights into the AI's behavior, improving diagnostic precision and enabling more targeted enhancements to the system's safety and robustness.