 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Statistical Estimation: Differentially Private Individual Computation in the Shuffle Model
Paper and Code
Jun 26, 2024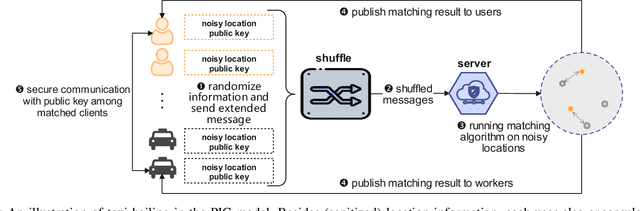
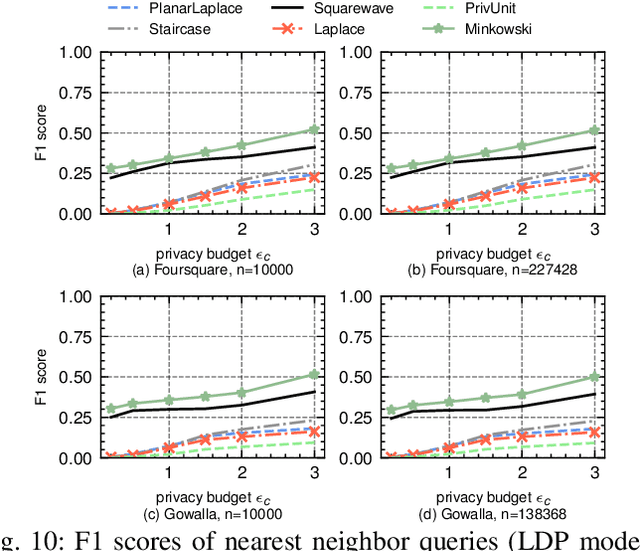
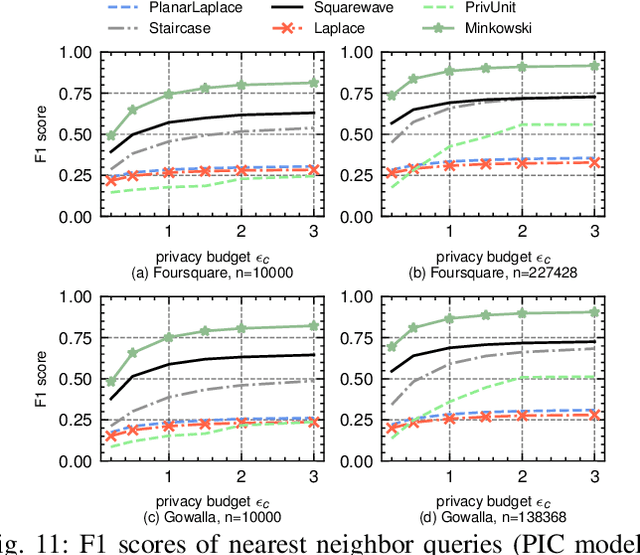
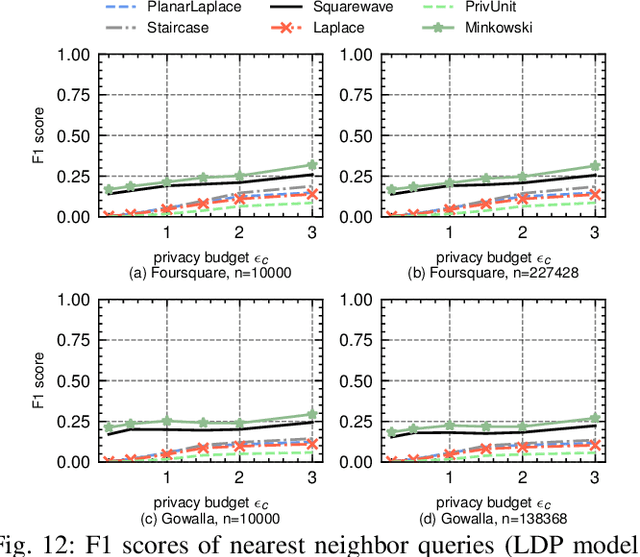
The shuffle model of differential privacy (DP) has recently emerged as a powerful one for decentralized computation without fully trustable parties. Since it anonymizes and permutes messages from clients through a shuffler, the privacy can be amplified and utility can be improved. However, the shuffling procedure in turn restricts its applications only to statistical tasks that are permutation-invariant. This work explores the feasibility of shuffle privacy amplification for prevalent non-statistical computations: spatial crowdsourcing, combinatorial optimization, location-based social systems, and federated learning with incentives, which suffer either computationally intractability or intolerable utility loss in existing approaches (e.g., secure MPC and local DP). We proposes a new paradigm of shuffle model that can provide critical security functionalities like message authorization and result access control, meanwhile maintaining the most of privacy amplification effects. It incurs almost the same computation/communication costs as the non-private setting, and permits the server to run arbitrary algorithms on (noisy) client information in plaintext. Our novel technique is introducing statistically random identity into DP and force identical random distribution on all clients, so as to support secure functionalities even after message shuffling and to maintain privacy amplification simultaneously. Given that existing DP randomizers fails in the new shuffle model, we also propose a new mechanism and prove its optimality therein. Experimental results on spatial crowdsourcing, location-based social system, and federated learning with incentives, show that our paradigm and mechanism is fast as non-private settings, while reducing up to 90% error and increasing utility performance indicates by 100%-300% relatively, and can be practical under reasonable privacy budget.