 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Input Order Bias on Large Language Models for Software Fault Localization
Dec 25, 2024



Large Language Models (LLMs) show great promise in software engineering tasks like Fault Localization (FL) and Automatic Program Repair (APR). This study examines how input order and context size affect LLM performance in FL, a key step for many downstream software engineering tasks. We test different orders for methods using Kendall Tau distances, including "perfect" (where ground truths come first) and "worst" (where ground truths come last). Our results show a strong bias in order, with Top-1 accuracy falling from 57\% to 20\% when we reverse the code order. Breaking down inputs into smaller contexts helps reduce this bias, narrowing the performance gap between perfect and worst orders from 22\% to just 1\%. We also look at ordering methods based on traditional FL techniques and metrics. Ordering using DepGraph's ranking achieves 48\% Top-1 accuracy, better than more straightforward ordering approaches like CallGraph. These findings underscore the importance of how we structure inputs, manage contexts, and choose ordering methods to improve LLM performance in FL and other software engineering tasks.
OpenLogParser: Unsupervised Parsing with Open-Source Large Language Models
Aug 02, 2024



Log parsing is a critical step that transforms unstructured log data into structured formats, facilitating subsequent log-based analysis. Traditional syntax-based log parsers are efficient and effective, but they often experience decreased accuracy when processing logs that deviate from the predefined rules. Recently, large language models (LLM) based log parsers have shown superior parsing accuracy. However, existing LLM-based parsers face three main challenges: 1)time-consuming and labor-intensive manual labeling for fine-tuning or in-context learning, 2)increased parsing costs due to the vast volume of log data and limited context size of LLMs, and 3)privacy risks from using commercial models like ChatGPT with sensitive log information. To overcome these limitations, this paper introduces OpenLogParser, an unsupervised log parsing approach that leverages open-source LLMs (i.e., Llama3-8B) to enhance privacy and reduce operational costs while achieving state-of-the-art parsing accuracy. OpenLogParser first groups logs with similar static text but varying dynamic variables using a fixed-depth grouping tree. It then parses logs within these groups using three components: i)similarity scoring-based retrieval augmented generation: selects diverse logs within each group based on Jaccard similarity, helping the LLM distinguish between static text and dynamic variables; ii)self-reflection: iteratively query LLMs to refine log templates to improve parsing accuracy; and iii) log template memory: stores parsed templates to reduce LLM queries for improved parsing efficiency. Our evaluation on LogHub-2.0 shows that OpenLogParser achieves 25% higher parsing accuracy and processes logs 2.7 times faster compared to state-of-the-art LLM-based parsers. In short, OpenLogParser addresses privacy and cost concerns of using commercial LLMs while achieving state-of-the-arts parsing efficiency and accuracy.
Identifying Performance-Sensitive Configurations in Software Systems through Code Analysis with LLM Agents
Jun 18, 2024



Configuration settings are essential for tailoring software behavior to meet specific performance requirements. However, incorrect configurations are widespread, and identifying those that impact system performance is challenging due to the vast number and complexity of possible settings. In this work, we present PerfSense, a lightweight framework that leverages Large Language Models (LLMs) to efficiently identify performance-sensitive configurations with minimal overhead. PerfSense employs LLM agents to simulate interactions between developers and performance engineers using advanced prompting techniques such as prompt chaining and retrieval-augmented generation (RAG). Our evaluation of seven open-source Java systems demonstrates that PerfSense achieves an average accuracy of 64.77% in classifying performance-sensitive configurations, outperforming both our LLM baseline (50.36%) and the previous state-of-the-art method (61.75%). Notably, our prompt chaining technique improves recall by 10% to 30% while maintaining similar precision levels. Additionally, a manual analysis of 362 misclassifications reveals common issues, including LLMs' misunderstandings of requirements (26.8%). In summary, PerfSense significantly reduces manual effort in classifying performance-sensitive configurations and offers valuable insights for future LLM-based code analysis research.
LLMParser: An Exploratory Study on Using Large Language Models for Log Parsing
Apr 27, 2024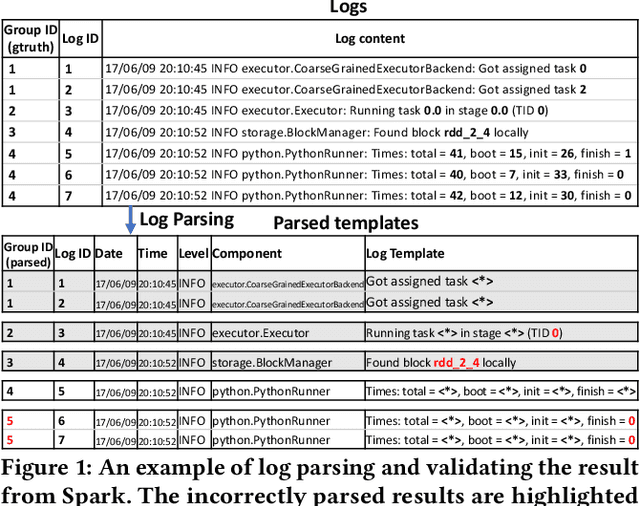

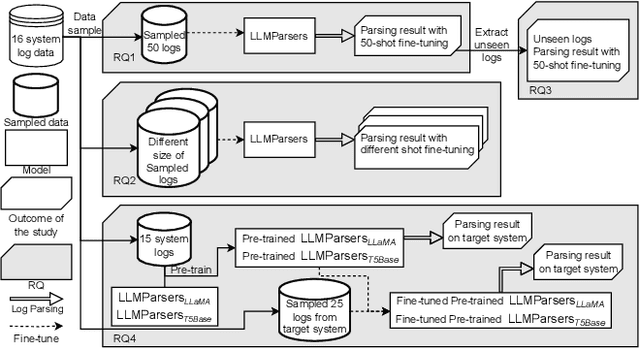
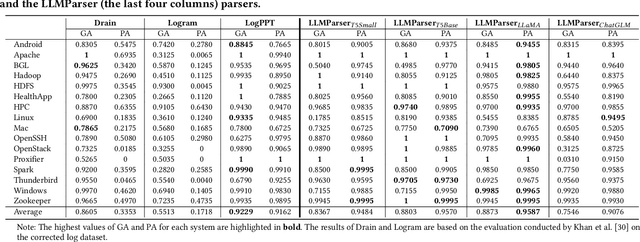
Logs are important in modern software development with runtime information. Log parsing is the first step in many log-based analyses, that involve extracting structured information from unstructured log data. Traditional log parsers face challenges in accurately parsing logs due to the diversity of log formats, which directly impacts the performance of downstream log-analysis tasks. In this paper, we explore the potential of using Large Language Models (LLMs) for log parsing and propose LLMParser, an LLM-based log parser based on generative LLMs and few-shot tuning. We leverage four LLMs, Flan-T5-small, Flan-T5-base, LLaMA-7B, and ChatGLM-6B in LLMParsers. Our evaluation of 16 open-source systems shows that LLMParser achieves statistically significantly higher parsing accuracy than state-of-the-art parsers (a 96% average parsing accuracy). We further conduct a comprehensive empirical analysis on the effect of training size, model size, and pre-training LLM on log parsing accuracy. We find that smaller LLMs may be more effective than more complex LLMs; for instance where Flan-T5-base achieves comparable results as LLaMA-7B with a shorter inference time. We also find that using LLMs pre-trained using logs from other systems does not always improve parsing accuracy. While using pre-trained Flan-T5-base shows an improvement in accuracy, pre-trained LLaMA results in a decrease (decrease by almost 55% in group accuracy). In short, our study provides empirical evidence for using LLMs for log parsing and highlights the limitations and future research direction of LLM-based log parsers.