 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Secure Logging: Characterizing and Benchmarking Logging Code Security Issues with LLMs
Apr 22, 2026Logging code plays an important role in software systems by recording key events and behaviors, which are essential for debugging and monitoring. However, insecure logging practices can inadvertently expose sensitive information or enable attacks such as log injection, posing serious threats to system security and privacy. Prior research has examined general defects in logging code, but systematic analysis of logging code security issues remains limited, particularly in leveraging LLMs for detection and repair. In this paper, we derive a comprehensive taxonomy of logging code security issues, encompassing four common issue categories and 10 corresponding patterns. We further construct a benchmark dataset with 101 real-world logging security issue reports that have been manually reviewed and annotated. We then propose an automated framework that incorporates various contextual knowledge to evaluate LLMs' capabilities in detecting and repairing logging security issues. Our experimental results reveal a notable disparity in performance: while LLMs are moderately effective at detecting security issues (e.g., the accuracy ranges from 12.9% to 52.5% on average), they face noticeable challenges in reliably generating correct code repairs. We also find that the issue description alone improves the LLMs' detection accuracy more than the security pattern explanation or a combination of both. Overall, our findings provide actionable insights for practitioners and highlight the potential and limitations of current LLMs for secure logging.
LLMParser: An Exploratory Study on Using Large Language Models for Log Parsing
Apr 27, 2024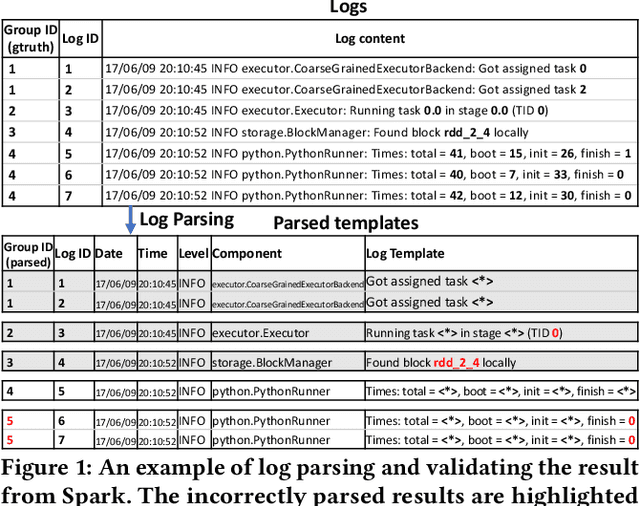

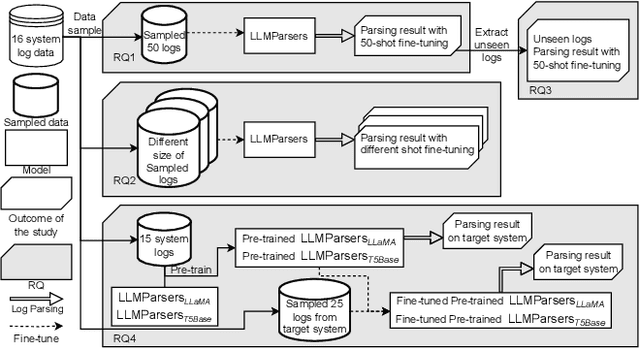
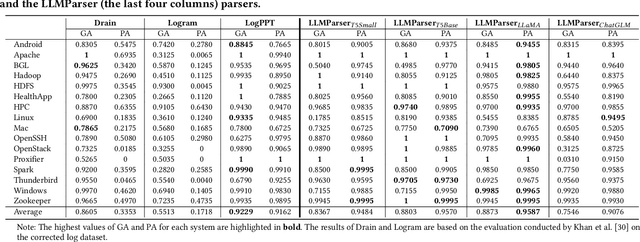
Logs are important in modern software development with runtime information. Log parsing is the first step in many log-based analyses, that involve extracting structured information from unstructured log data. Traditional log parsers face challenges in accurately parsing logs due to the diversity of log formats, which directly impacts the performance of downstream log-analysis tasks. In this paper, we explore the potential of using Large Language Models (LLMs) for log parsing and propose LLMParser, an LLM-based log parser based on generative LLMs and few-shot tuning. We leverage four LLMs, Flan-T5-small, Flan-T5-base, LLaMA-7B, and ChatGLM-6B in LLMParsers. Our evaluation of 16 open-source systems shows that LLMParser achieves statistically significantly higher parsing accuracy than state-of-the-art parsers (a 96% average parsing accuracy). We further conduct a comprehensive empirical analysis on the effect of training size, model size, and pre-training LLM on log parsing accuracy. We find that smaller LLMs may be more effective than more complex LLMs; for instance where Flan-T5-base achieves comparable results as LLaMA-7B with a shorter inference time. We also find that using LLMs pre-trained using logs from other systems does not always improve parsing accuracy. While using pre-trained Flan-T5-base shows an improvement in accuracy, pre-trained LLaMA results in a decrease (decrease by almost 55% in group accuracy). In short, our study provides empirical evidence for using LLMs for log parsing and highlights the limitations and future research direction of LLM-based log parsers.