 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Integration of Labels across Categories for Component Identification (MILCCI)
Feb 04, 2026Many fields collect large-scale temporal data through repeated measurements (trials), where each trial is labeled with a set of metadata variables spanning several categories. For example, a trial in a neuroscience study may be linked to a value from category (a): task difficulty, and category (b): animal choice. A critical challenge in time-series analysis is to understand how these labels are encoded within the multi-trial observations, and disentangle the distinct effect of each label entry across categories. Here, we present MILCCI, a novel data-driven method that i) identifies the interpretable components underlying the data, ii) captures cross-trial variability, and iii) integrates label information to understand each category's representation within the data. MILCCI extends a sparse per-trial decomposition that leverages label similarities within each category to enable subtle, label-driven cross-trial adjustments in component compositions and to distinguish the contribution of each category. MILCCI also learns each component's corresponding temporal trace, which evolves over time within each trial and varies flexibly across trials. We demonstrate MILCCI's performance through both synthetic and real-world examples, including voting patterns, online page view trends, and neuronal recordings.
Whole-Body Proprioceptive Morphing: A Modular Soft Gripper for Robust Cross-Scale Grasping
Oct 31, 2025Biological systems, such as the octopus, exhibit masterful cross-scale manipulation by adaptively reconfiguring their entire form, a capability that remains elusive in robotics. Conventional soft grippers, while compliant, are mostly constrained by a fixed global morphology, and prior shape-morphing efforts have been largely confined to localized deformations, failing to replicate this biological dexterity. Inspired by this natural exemplar, we introduce the paradigm of collaborative, whole-body proprioceptive morphing, realized in a modular soft gripper architecture. Our design is a distributed network of modular self-sensing pneumatic actuators that enables the gripper to intelligently reconfigure its entire topology, achieving multiple morphing states that are controllable to form diverse polygonal shapes. By integrating rich proprioceptive feedback from embedded sensors, our system can seamlessly transition from a precise pinch to a large envelope grasp. We experimentally demonstrate that this approach expands the grasping envelope and enhances generalization across diverse object geometries (standard and irregular) and scales (up to 10$\times$), while also unlocking novel manipulation modalities such as multi-object and internal hook grasping. This work presents a low-cost, easy-to-fabricate, and scalable framework that fuses distributed actuation with integrated sensing, offering a new pathway toward achieving biological levels of dexterity in robotic manipulation.
Top-$k$ Feature Importance Ranking
Sep 18, 2025



Accurate ranking of important features is a fundamental challenge in interpretable machine learning with critical applications in scientific discovery and decision-making. Unlike feature selection and feature importance, the specific problem of ranking important features has received considerably less attention. We introduce RAMPART (Ranked Attributions with MiniPatches And Recursive Trimming), a framework that utilizes any existing feature importance measure in a novel algorithm specifically tailored for ranking the top-$k$ features. Our approach combines an adaptive sequential halving strategy that progressively focuses computational resources on promising features with an efficient ensembling technique using both observation and feature subsampling. Unlike existing methods that convert importance scores to ranks as post-processing, our framework explicitly optimizes for ranking accuracy. We provide theoretical guarantees showing that RAMPART achieves the correct top-$k$ ranking with high probability under mild conditions, and demonstrate through extensive simulation studies that RAMPART consistently outperforms popular feature importance methods, concluding with a high-dimensional genomics case study.
Knowing or Guessing? Robust Medical Visual Question Answering via Joint Consistency and Contrastive Learning
Aug 26, 2025In high-stakes medical applications, consistent answering across diverse question phrasings is essential for reliable diagnosis. However, we reveal that current Medical Vision-Language Models (Med-VLMs) exhibit concerning fragility in Medical Visual Question Answering, as their answers fluctuate significantly when faced with semantically equivalent rephrasings of medical questions. We attribute this to two limitations: (1) insufficient alignment of medical concepts, leading to divergent reasoning patterns, and (2) hidden biases in training data that prioritize syntactic shortcuts over semantic understanding. To address these challenges, we construct RoMed, a dataset built upon original VQA datasets containing 144k questions with variations spanning word-level, sentence-level, and semantic-level perturbations. When evaluating state-of-the-art (SOTA) models like LLaVA-Med on RoMed, we observe alarming performance drops (e.g., a 40\% decline in Recall) compared to original VQA benchmarks, exposing critical robustness gaps. To bridge this gap, we propose Consistency and Contrastive Learning (CCL), which integrates two key components: (1) knowledge-anchored consistency learning, aligning Med-VLMs with medical knowledge rather than shallow feature patterns, and (2) bias-aware contrastive learning, mitigating data-specific priors through discriminative representation refinement. CCL achieves SOTA performance on three popular VQA benchmarks and notably improves answer consistency by 50\% on the challenging RoMed test set, demonstrating significantly enhanced robustness. Code will be released.
Practical Poisoning Attacks against Retrieval-Augmented Generation
Apr 04, 2025Large language models (LLMs) have demonstrated impressive natural language processing abilities but face challenges such as hallucination and outdated knowledge. Retrieval-Augmented Generation (RAG) has emerged as a state-of-the-art approach to mitigate these issues. While RAG enhances LLM outputs, it remains vulnerable to poisoning attacks. Recent studies show that injecting poisoned text into the knowledge database can compromise RAG systems, but most existing attacks assume that the attacker can insert a sufficient number of poisoned texts per query to outnumber correct-answer texts in retrieval, an assumption that is often unrealistic. To address this limitation, we propose CorruptRAG, a practical poisoning attack against RAG systems in which the attacker injects only a single poisoned text, enhancing both feasibility and stealth. Extensive experiments across multiple datasets demonstrate that CorruptRAG achieves higher attack success rates compared to existing baselines.
MT-PCR: Leveraging Modality Transformation for Large-Scale Point Cloud Registration with Limited Overlap
Mar 17, 2025



Large-scale scene point cloud registration with limited overlap is a challenging task due to computational load and constrained data acquisition. To tackle these issues, we propose a point cloud registration method, MT-PCR, based on Modality Transformation. MT-PCR leverages a BEV capturing the maximal overlap information to improve the accuracy and utilizes images to provide complementary spatial features. Specifically, MT-PCR converts 3D point clouds to BEV images and eastimates correspondence by 2D image keypoints extraction and matching. Subsequently, the 2D correspondence estimates are then transformed back to 3D point clouds using inverse mapping. We have applied MT-PCR to Terrestrial Laser Scanning and Aerial Laser Scanning point cloud registration on the GrAco dataset, involving 8 low-overlap, square-kilometer scale registration scenarios. Experiments and comparisons with commonly used methods demonstrate that MT-PCR can achieve superior accuracy and robustness in large-scale scenes with limited overlap.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.
Deep Reinforcement Learning-Assisted Federated Learning for Robust Short-term Utility Demand Forecasting in Electricity Wholesale Markets
Jun 23, 2022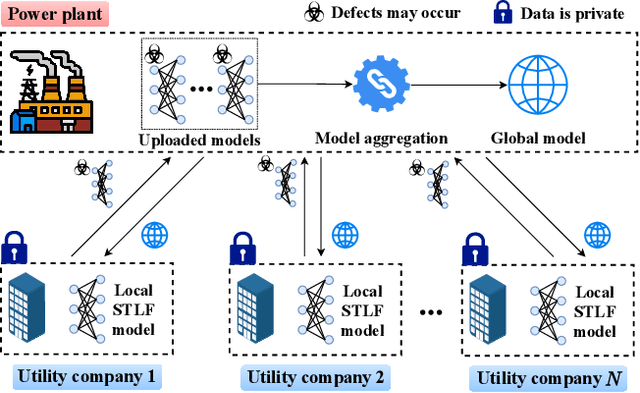
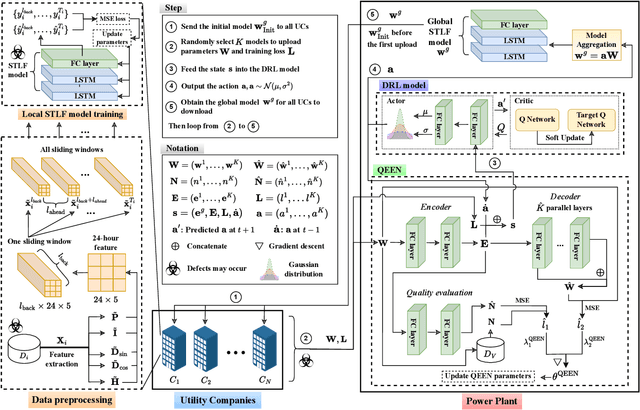
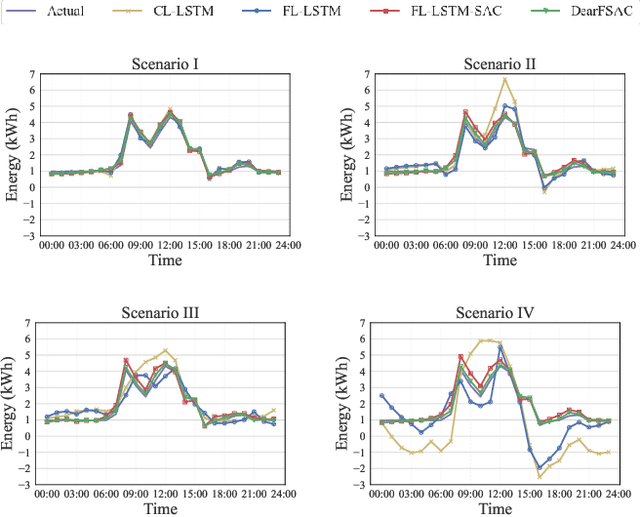
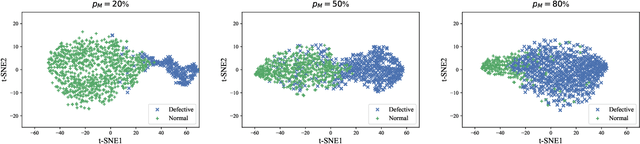
Short-term load forecasting (STLF) plays a significant role in the operation of electricity trading markets. Considering the growing concern of data privacy, federated learning (FL) is increasingly adopted to train STLF models for utility companies (UCs) in recent research. Inspiringly, in wholesale markets, as it is not realistic for power plants (PPs) to access UCs' data directly, FL is definitely a feasible solution of obtaining an accurate STLF model for PPs. However, due to FL's distributed nature and intense competition among UCs, defects increasingly occur and lead to poor performance of the STLF model, indicating that simply adopting FL is not enough. In this paper, we propose a DRL-assisted FL approach, DEfect-AwaRe federated soft actor-critic (DearFSAC), to robustly train an accurate STLF model for PPs to forecast precise short-term utility electricity demand. Firstly. we design a STLF model based on long short-term memory (LSTM) using just historical load data and time data. Furthermore, considering the uncertainty of defects occurrence, a deep reinforcement learning (DRL) algorithm is adopted to assist FL by alleviating model degradation caused by defects. In addition, for faster convergence of FL training, an auto-encoder is designed for both dimension reduction and quality evaluation of uploaded models. In the simulations, we validate our approach on real data of Helsinki's UCs in 2019. The results show that DearFSAC outperforms all the other approaches no matter if defects occur or not.
DearFSAC: An Approach to Optimizing Unreliable Federated Learning via Deep Reinforcement Learning
Jan 30, 2022In federated learning (FL), model aggregation has been widely adopted for data privacy. In recent years, assigning different weights to local models has been used to alleviate the FL performance degradation caused by differences between local datasets. However, when various defects make the FL process unreliable, most existing FL approaches expose weak robustness. In this paper, we propose the DEfect-AwaRe federated soft actor-critic (DearFSAC) to dynamically assign weights to local models to improve the robustness of FL. The deep reinforcement learning algorithm soft actor-critic is adopted for near-optimal performance and stable convergence. Besides, an auto-encoder is trained to output low-dimensional embedding vectors that are further utilized to evaluate model quality. In the experiments, DearFSAC outperforms three existing approaches on four datasets for both independent and identically distributed (IID) and non-IID settings under defective scenarios.
Protum: A New Method For Prompt Tuning Based on ""
Jan 28, 2022Recently, prompt tuning \cite{lester2021power} has gradually become a new paradigm for NLP, which only depends on the representation of the words by freezing the parameters of pre-trained language models (PLMs) to obtain remarkable performance on downstream tasks. It maintains the consistency of Masked Language Model (MLM) \cite{devlin2018bert} task in the process of pre-training, and avoids some issues that may happened during fine-tuning. Naturally, we consider that the "[MASK]" tokens carry more useful information than other tokens because the model combines with context to predict the masked tokens. Among the current prompt tuning methods, there will be a serious problem of random composition of the answer tokens in prediction when they predict multiple words so that they have to map tokens to labels with the help verbalizer. In response to the above issue, we propose a new \textbf{Pro}mpt \textbf{Tu}ning based on "[\textbf{M}ASK]" (\textbf{Protum}) method in this paper, which constructs a classification task through the information carried by the hidden layer of "[MASK]" tokens and then predicts the labels directly rather than the answer tokens. At the same time, we explore how different hidden layers under "[MASK]" impact on our classification model on many different data sets. Finally, we find that our \textbf{Protum} can achieve much better performance than fine-tuning after continuous pre-training with less time consumption. Our model facilitates the practical application of large models in NLP.