 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOOVDet: Low-Density Prior Learning for Zero-Shot Out-of-Vocabulary Object Detection
Jan 30, 2026Zero-shot out-of-vocabulary detection (ZS-OOVD) aims to accurately recognize objects of in-vocabulary (IV) categories provided at zero-shot inference, while simultaneously rejecting undefined ones (out-of-vocabulary, OOV) that lack corresponding category prompts. However, previous methods are prone to overfitting the IV classes, leading to the OOV or undefined classes being misclassified as IV ones with a high confidence score. To address this issue, this paper proposes a zero-shot OOV detector (OOVDet), a novel framework that effectively detects predefined classes while reliably rejecting undefined ones in zero-shot scenes. Specifically, due to the model's lack of prior knowledge about the distribution of OOV data, we synthesize region-level OOV prompts by sampling from the low-likelihood regions of the class-conditional Gaussian distributions in the hidden space, motivated by the assumption that unknown semantics are more likely to emerge in low-density areas of the latent space. For OOV images, we further propose a Dirichlet-based gradient attribution mechanism to mine pseudo-OOV image samples, where the attribution gradients are interpreted as Dirichlet evidence to estimate prediction uncertainty, and samples with high uncertainty are selected as pseudo-OOV images. Building on these synthesized OOV prompts and pseudo-OOV images, we construct the OOV decision boundary through a low-density prior constraint, which regularizes the optimization of OOV classes using Gaussian kernel density estimation in accordance with the above assumption. Experimental results show that our method significantly improves the OOV detection performance in zero-shot scenes. The code is available at https://github.com/binyisu/OOV-detector.
Season-Independent PV Disaggregation Using Multi-Scale Net Load Temporal Feature Extraction and Weather Factor Fusion
May 24, 2025With the advancement of energy Internet and energy system integration, the increasing adoption of distributed photovoltaic (PV) systems presents new challenges on smart monitoring and measurement for utility companies, particularly in separating PV generation from net electricity load. Existing methods struggle with feature extraction from net load and capturing the relevance between weather factors. This paper proposes a PV disaggregation method that integrates Hierarchical Interpolation (HI) and multi-head self-attention mechanisms. By using HI to extract net load features and multi-head self-attention to capture the complex dependencies between weather factors, the method achieves precise PV generation predictions. Simulation experiments demonstrate the effectiveness of the proposed method in real-world data, supporting improved monitoring and management of distributed energy systems.
Agent-Based Decentralized Energy Management of EV Charging Station with Solar Photovoltaics via Multi-Agent Reinforcement Learning
May 24, 2025In the pursuit of energy net zero within smart cities, transportation electrification plays a pivotal role. The adoption of Electric Vehicles (EVs) keeps increasing, making energy management of EV charging stations critically important. While previous studies have managed to reduce energy cost of EV charging while maintaining grid stability, they often overlook the robustness of EV charging management against uncertainties of various forms, such as varying charging behaviors and possible faults in faults in some chargers. To address the gap, a novel Multi-Agent Reinforcement Learning (MARL) approach is proposed treating each charger to be an agent and coordinate all the agents in the EV charging station with solar photovoltaics in a more realistic scenario, where system faults may occur. A Long Short-Term Memory (LSTM) network is incorporated in the MARL algorithm to extract temporal features from time-series. Additionally, a dense reward mechanism is designed for training the agents in the MARL algorithm to improve EV charging experience. Through validation on a real-world dataset, we show that our approach is robust against system uncertainties and faults and also effective in minimizing EV charging costs and maximizing charging service satisfaction.
Smart Energy Guardian: A Hybrid Deep Learning Model for Detecting Fraudulent PV Generation
May 24, 2025With the proliferation of smart grids, smart cities face growing challenges due to cyber-attacks and sophisticated electricity theft behaviors, particularly in residential photovoltaic (PV) generation systems. Traditional Electricity Theft Detection (ETD) methods often struggle to capture complex temporal dependencies and integrating multi-source data, limiting their effectiveness. In this work, we propose an efficient ETD method that accurately identifies fraudulent behaviors in residential PV generation, thus ensuring the supply-demand balance in smart cities. Our hybrid deep learning model, combining multi-scale Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM), and Transformer, excels in capturing both short-term and long-term temporal dependencies. Additionally, we introduce a data embedding technique that seamlessly integrates time-series data with discrete temperature variables, enhancing detection robustness. Extensive simulation experiments using real-world data validate the effectiveness of our approach, demonstrating significant improvements in the accuracy of detecting sophisticated energy theft activities, thereby contributing to the stability and fairness of energy systems in smart cities.
FedCRL: Personalized Federated Learning with Contrastive Shared Representations for Label Heterogeneity in Non-IID Data
Apr 27, 2024



To deal with heterogeneity resulting from label distribution skew and data scarcity in distributed machine learning scenarios, this paper proposes a novel Personalized Federated Learning (PFL) algorithm, named Federated Contrastive Representation Learning (FedCRL). FedCRL introduces contrastive representation learning (CRL) on shared representations to facilitate knowledge acquisition of clients. Specifically, both local model parameters and averaged values of local representations are considered as shareable information to the server, both of which are then aggregated globally. CRL is applied between local representations and global representations to regularize personalized training by drawing similar representations closer and separating dissimilar ones, thereby enhancing local models with external knowledge and avoiding being harmed by label distribution skew. Additionally, FedCRL adopts local aggregation between each local model and the global model to tackle data scarcity. A loss-wise weighting mechanism is introduced to guide the local aggregation using each local model's contrastive loss to coordinate the global model involvement in each client, thus helping clients with scarce data. Our simulations demonstrate FedCRL's effectiveness in mitigating label heterogeneity by achieving accuracy improvements over existing methods on datasets with varying degrees of label heterogeneity.
PokerGPT: An End-to-End Lightweight Solver for Multi-Player Texas Hold'em via Large Language Model
Jan 04, 2024Poker, also known as Texas Hold'em, has always been a typical research target within imperfect information games (IIGs). IIGs have long served as a measure of artificial intelligence (AI) development. Representative prior works, such as DeepStack and Libratus heavily rely on counterfactual regret minimization (CFR) to tackle heads-up no-limit Poker. However, it is challenging for subsequent researchers to learn CFR from previous models and apply it to other real-world applications due to the expensive computational cost of CFR iterations. Additionally, CFR is difficult to apply to multi-player games due to the exponential growth of the game tree size. In this work, we introduce PokerGPT, an end-to-end solver for playing Texas Hold'em with arbitrary number of players and gaining high win rates, established on a lightweight large language model (LLM). PokerGPT only requires simple textual information of Poker games for generating decision-making advice, thus guaranteeing the convenient interaction between AI and humans. We mainly transform a set of textual records acquired from real games into prompts, and use them to fine-tune a lightweight pre-trained LLM using reinforcement learning human feedback technique. To improve fine-tuning performance, we conduct prompt engineering on raw data, including filtering useful information, selecting behaviors of players with high win rates, and further processing them into textual instruction using multiple prompt engineering techniques. Through the experiments, we demonstrate that PokerGPT outperforms previous approaches in terms of win rate, model size, training time, and response speed, indicating the great potential of LLMs in solving IIGs.
Large Foundation Models for Power Systems
Dec 12, 2023Foundation models, such as Large Language Models (LLMs), can respond to a wide range of format-free queries without any task-specific data collection or model training, creating various research and application opportunities for the modeling and operation of large-scale power systems. In this paper, we outline how such large foundation model such as GPT-4 are developed, and discuss how they can be leveraged in challenging power and energy system tasks. We first investigate the potential of existing foundation models by validating their performance on four representative tasks across power system domains, including the optimal power flow (OPF), electric vehicle (EV) scheduling, knowledge retrieval for power engineering technical reports, and situation awareness. Our results indicate strong capabilities of such foundation models on boosting the efficiency and reliability of power system operational pipelines. We also provide suggestions and projections on future deployment of foundation models in power system applications.
Deep Reinforcement Learning-Assisted Federated Learning for Robust Short-term Utility Demand Forecasting in Electricity Wholesale Markets
Jun 23, 2022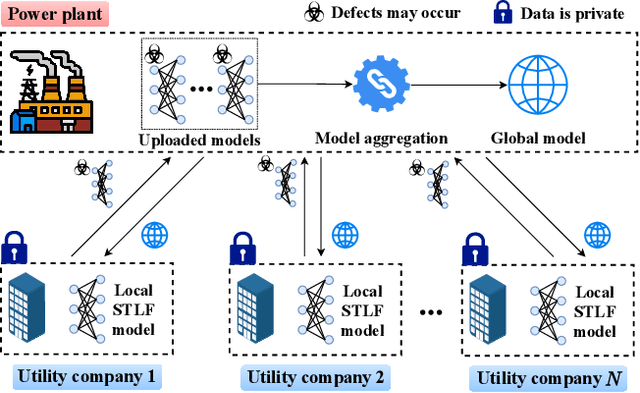
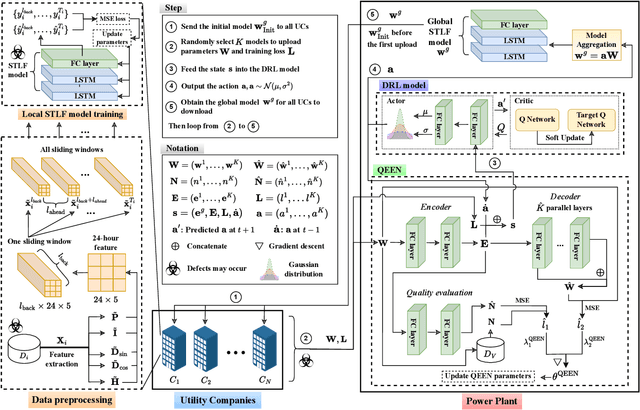
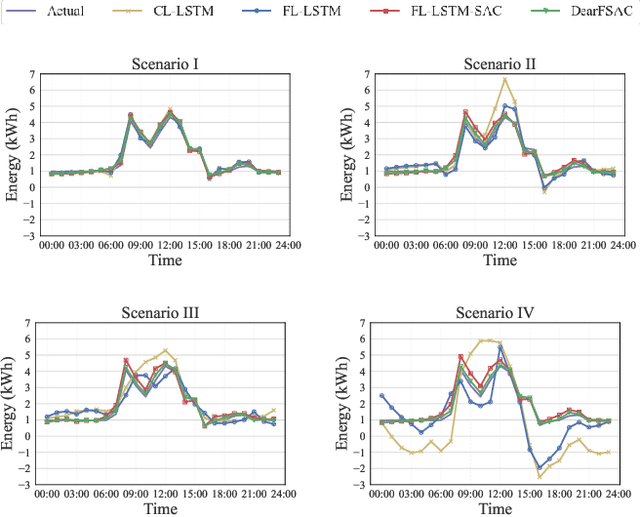
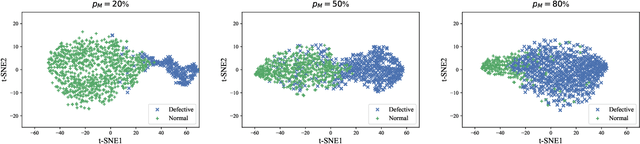
Short-term load forecasting (STLF) plays a significant role in the operation of electricity trading markets. Considering the growing concern of data privacy, federated learning (FL) is increasingly adopted to train STLF models for utility companies (UCs) in recent research. Inspiringly, in wholesale markets, as it is not realistic for power plants (PPs) to access UCs' data directly, FL is definitely a feasible solution of obtaining an accurate STLF model for PPs. However, due to FL's distributed nature and intense competition among UCs, defects increasingly occur and lead to poor performance of the STLF model, indicating that simply adopting FL is not enough. In this paper, we propose a DRL-assisted FL approach, DEfect-AwaRe federated soft actor-critic (DearFSAC), to robustly train an accurate STLF model for PPs to forecast precise short-term utility electricity demand. Firstly. we design a STLF model based on long short-term memory (LSTM) using just historical load data and time data. Furthermore, considering the uncertainty of defects occurrence, a deep reinforcement learning (DRL) algorithm is adopted to assist FL by alleviating model degradation caused by defects. In addition, for faster convergence of FL training, an auto-encoder is designed for both dimension reduction and quality evaluation of uploaded models. In the simulations, we validate our approach on real data of Helsinki's UCs in 2019. The results show that DearFSAC outperforms all the other approaches no matter if defects occur or not.
DearFSAC: An Approach to Optimizing Unreliable Federated Learning via Deep Reinforcement Learning
Jan 30, 2022In federated learning (FL), model aggregation has been widely adopted for data privacy. In recent years, assigning different weights to local models has been used to alleviate the FL performance degradation caused by differences between local datasets. However, when various defects make the FL process unreliable, most existing FL approaches expose weak robustness. In this paper, we propose the DEfect-AwaRe federated soft actor-critic (DearFSAC) to dynamically assign weights to local models to improve the robustness of FL. The deep reinforcement learning algorithm soft actor-critic is adopted for near-optimal performance and stable convergence. Besides, an auto-encoder is trained to output low-dimensional embedding vectors that are further utilized to evaluate model quality. In the experiments, DearFSAC outperforms three existing approaches on four datasets for both independent and identically distributed (IID) and non-IID settings under defective scenarios.
MeisterMorxrc at SemEval-2020 Task 9: Fine-Tune Bert and Multitask Learning for Sentiment Analysis of Code-Mixed Tweets
Dec 15, 2020
Natural language processing (NLP) has been applied to various fields including text classification and sentiment analysis. In the shared task of sentiment analysis of code-mixed tweets, which is a part of the SemEval-2020 competition~\cite{patwa2020sentimix}, we preprocess datasets by replacing emoji and deleting uncommon characters and so on, and then fine-tune the Bidirectional Encoder Representation from Transformers(BERT) to perform the best. After exhausting top3 submissions, Our team MeisterMorxrc achieves an averaged F1 score of 0.730 in this task, and and our codalab username is MeisterMorxrc.