 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalizing black-box models for nonparametric regression with minimax optimality
Jan 04, 2026Recent advances in large-scale models, including deep neural networks and large language models, have substantially improved performance across a wide range of learning tasks. The widespread availability of such pre-trained models creates new opportunities for data-efficient statistical learning, provided they can be effectively integrated into downstream tasks. Motivated by this setting, we study few-shot personalization, where a pre-trained black-box model is adapted to a target domain using a limited number of samples. We develop a theoretical framework for few-shot personalization in nonparametric regression and propose algorithms that can incorporate a black-box pre-trained model into the regression procedure. We establish the minimax optimal rate for the personalization problem and show that the proposed method attains this rate. Our results clarify the statistical benefits of leveraging pre-trained models under sample scarcity and provide robustness guarantees when the pre-trained model is not informative. We illustrate the finite-sample performance of the methods through simulations and an application to the California housing dataset with several pre-trained models.
MHRC: Closed-loop Decentralized Multi-Heterogeneous Robot Collaboration with Large Language Models
Sep 25, 2024



The integration of large language models (LLMs) with robotics has significantly advanced robots' abilities in perception, cognition, and task planning. The use of natural language interfaces offers a unified approach for expressing the capability differences of heterogeneous robots, facilitating communication between them, and enabling seamless task allocation and collaboration. Currently, the utilization of LLMs to achieve decentralized multi-heterogeneous robot collaborative tasks remains an under-explored area of research. In this paper, we introduce a novel framework that utilizes LLMs to achieve decentralized collaboration among multiple heterogeneous robots. Our framework supports three robot categories, mobile robots, manipulation robots, and mobile manipulation robots, working together to complete tasks such as exploration, transportation, and organization. We developed a rich set of textual feedback mechanisms and chain-of-thought (CoT) prompts to enhance task planning efficiency and overall system performance. The mobile manipulation robot can adjust its base position flexibly, ensuring optimal conditions for grasping tasks. The manipulation robot can comprehend task requirements, seek assistance when necessary, and handle objects appropriately. Meanwhile, the mobile robot can explore the environment extensively, map object locations, and communicate this information to the mobile manipulation robot, thus improving task execution efficiency. We evaluated the framework using PyBullet, creating scenarios with three different room layouts and three distinct operational tasks. We tested various LLM models and conducted ablation studies to assess the contributions of different modules. The experimental results confirm the effectiveness and necessity of our proposed framework.
FAIRM: Learning invariant representations for algorithmic fairness and domain generalization with minimax optimality
Apr 02, 2024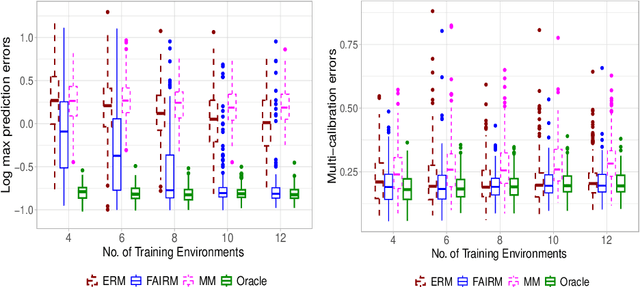
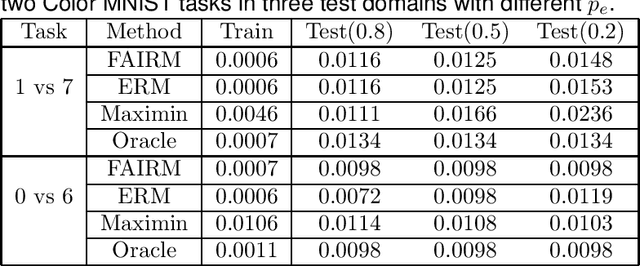
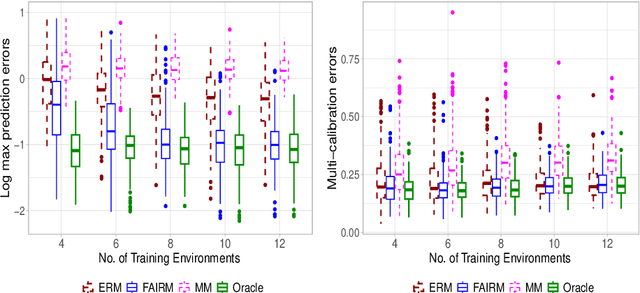
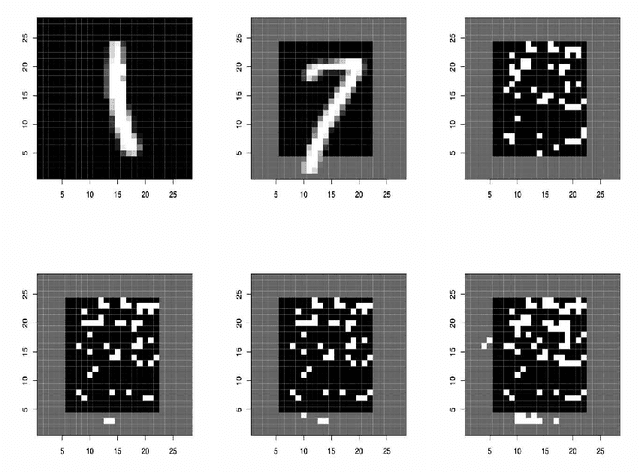
Machine learning methods often assume that the test data have the same distribution as the training data. However, this assumption may not hold due to multiple levels of heterogeneity in applications, raising issues in algorithmic fairness and domain generalization. In this work, we address the problem of fair and generalizable machine learning by invariant principles. We propose a training environment-based oracle, FAIRM, which has desirable fairness and domain generalization properties under a diversity-type condition. We then provide an empirical FAIRM with finite-sample theoretical guarantees under weak distributional assumptions. We then develop efficient algorithms to realize FAIRM in linear models and demonstrate the nonasymptotic performance with minimax optimality. We evaluate our method in numerical experiments with synthetic data and MNIST data and show that it outperforms its counterparts.
Multi-dimensional domain generalization with low-rank structures
Sep 18, 2023In conventional statistical and machine learning methods, it is typically assumed that the test data are identically distributed with the training data. However, this assumption does not always hold, especially in applications where the target population are not well-represented in the training data. This is a notable issue in health-related studies, where specific ethnic populations may be underrepresented, posing a significant challenge for researchers aiming to make statistical inferences about these minority groups. In this work, we present a novel approach to addressing this challenge in linear regression models. We organize the model parameters for all the sub-populations into a tensor. By studying a structured tensor completion problem, we can achieve robust domain generalization, i.e., learning about sub-populations with limited or no available data. Our method novelly leverages the structure of group labels and it can produce more reliable and interpretable generalization results. We establish rigorous theoretical guarantees for the proposed method and demonstrate its minimax optimality. To validate the effectiveness of our approach, we conduct extensive numerical experiments and a real data study focused on education level prediction for multiple ethnic groups, comparing our results with those obtained using other existing methods.
Transferred Q-learning
Feb 09, 2022We consider $Q$-learning with knowledge transfer, using samples from a target reinforcement learning (RL) task as well as source samples from different but related RL tasks. We propose transfer learning algorithms for both batch and online $Q$-learning with offline source studies. The proposed transferred $Q$-learning algorithm contains a novel re-targeting step that enables vertical information-cascading along multiple steps in an RL task, besides the usual horizontal information-gathering as transfer learning (TL) for supervised learning. We establish the first theoretical justifications of TL in RL tasks by showing a faster rate of convergence of the $Q$ function estimation in the offline RL transfer, and a lower regret bound in the offline-to-online RL transfer under certain similarity assumptions. Empirical evidences from both synthetic and real datasets are presented to back up the proposed algorithm and our theoretical results.
Improving Out-of-Distribution Robustness via Selective Augmentation
Jan 02, 2022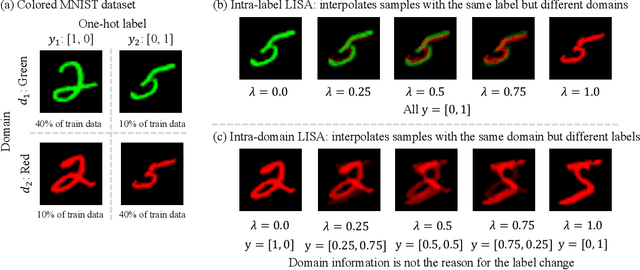
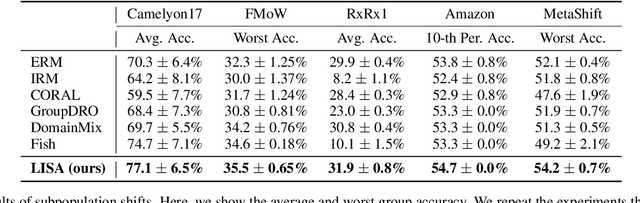
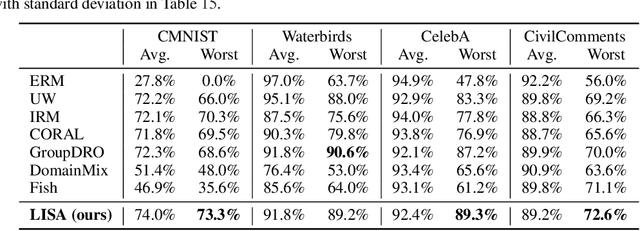
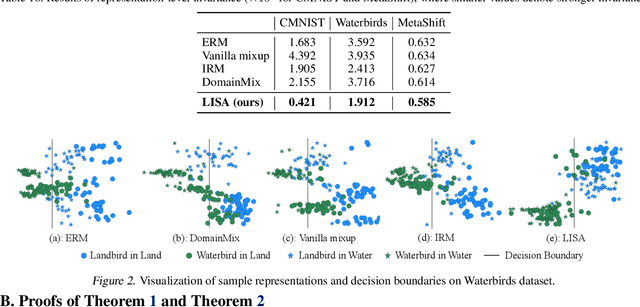
Machine learning algorithms typically assume that training and test examples are drawn from the same distribution. However, distribution shift is a common problem in real-world applications and can cause models to perform dramatically worse at test time. In this paper, we specifically consider the problems of domain shifts and subpopulation shifts (eg. imbalanced data). While prior works often seek to explicitly regularize internal representations and predictors of the model to be domain invariant, we instead aim to regularize the whole function without restricting the model's internal representations. This leads to a simple mixup-based technique which learns invariant functions via selective augmentation called LISA. LISA selectively interpolates samples either with the same labels but different domains or with the same domain but different labels. We analyze a linear setting and theoretically show how LISA leads to a smaller worst-group error. Empirically, we study the effectiveness of LISA on nine benchmarks ranging from subpopulation shifts to domain shifts, and we find that LISA consistently outperforms other state-of-the-art methods.
Targeting Underrepresented Populations in Precision Medicine: A Federated Transfer Learning Approach
Aug 27, 2021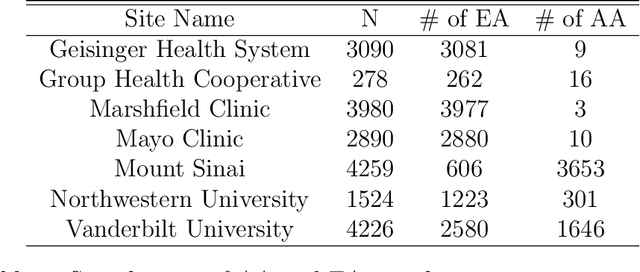

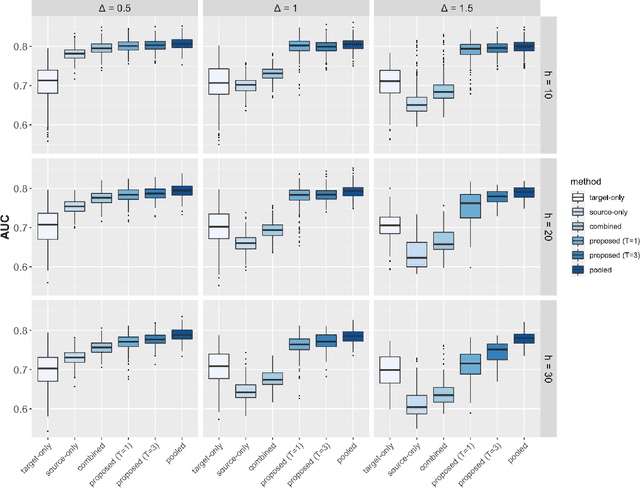
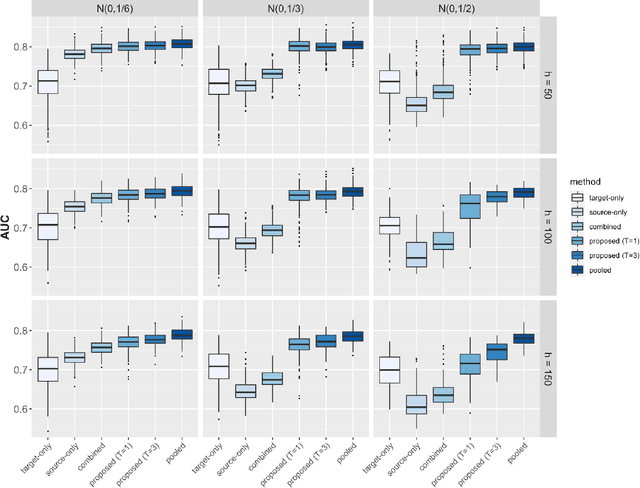
The limited representation of minorities and disadvantaged populations in large-scale clinical and genomics research has become a barrier to translating precision medicine research into practice. Due to heterogeneity across populations, risk prediction models are often found to be underperformed in these underrepresented populations, and therefore may further exacerbate known health disparities. In this paper, we propose a two-way data integration strategy that integrates heterogeneous data from diverse populations and from multiple healthcare institutions via a federated transfer learning approach. The proposed method can handle the challenging setting where sample sizes from different populations are highly unbalanced. With only a small number of communications across participating sites, the proposed method can achieve performance comparable to the pooled analysis where individual-level data are directly pooled together. We show that the proposed method improves the estimation and prediction accuracy in underrepresented populations, and reduces the gap of model performance across populations. Our theoretical analysis reveals how estimation accuracy is influenced by communication budgets, privacy restrictions, and heterogeneity across populations. We demonstrate the feasibility and validity of our methods through numerical experiments and a real application to a multi-center study, in which we construct polygenic risk prediction models for Type II diabetes in AA population.
Transfer Learning in Large-scale Gaussian Graphical Models with False Discovery Rate Control
Oct 21, 2020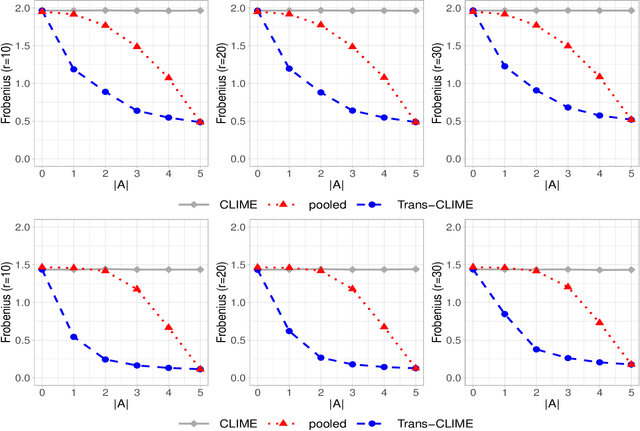
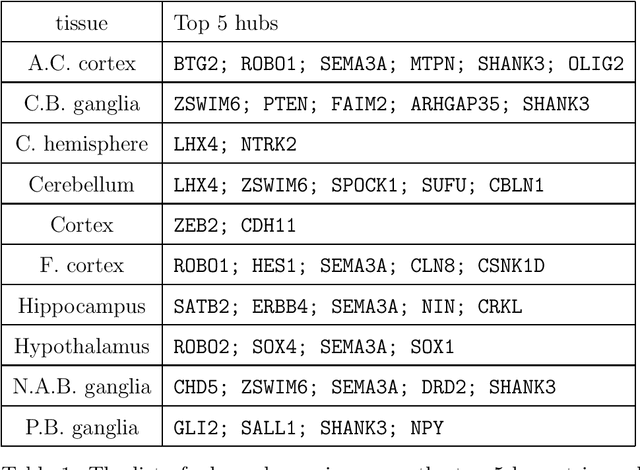
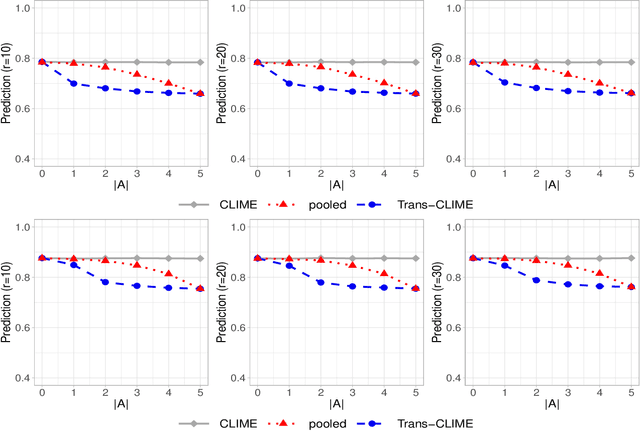
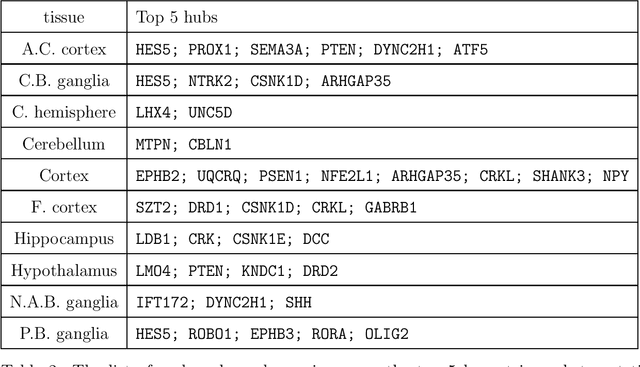
Transfer learning for high-dimensional Gaussian graphical models (GGMs) is studied with the goal of estimating the target GGM by utilizing the data from similar and related auxiliary studies. The similarity between the target graph and each auxiliary graph is characterized by the sparsity of a divergence matrix. An estimation algorithm, Trans-CLIME, is proposed and shown to attain a faster convergence rate than the minimax rate in the single study setting. Furthermore, a debiased Trans-CLIME estimator is introduced and shown to be element-wise asymptotically normal. It is used to construct a multiple testing procedure for edge detection with false discovery rate control. The proposed estimation and multiple testing procedures demonstrate superior numerical performance in simulations and are applied to infer the gene networks in a target brain tissue by leveraging the gene expressions from multiple other brain tissues. A significant decrease in prediction errors and a significant increase in power for link detection are observed.
Transfer Learning for High-dimensional Linear Regression: Prediction, Estimation, and Minimax Optimality
Jun 18, 2020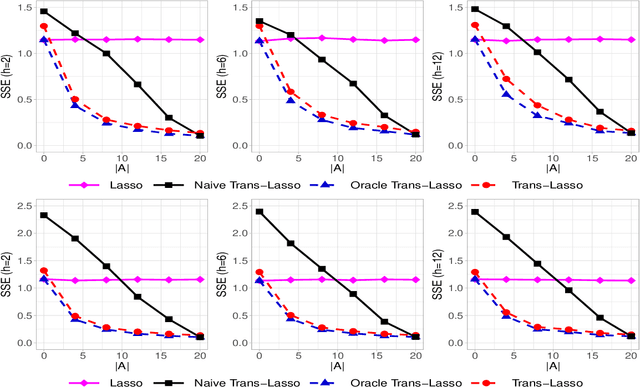
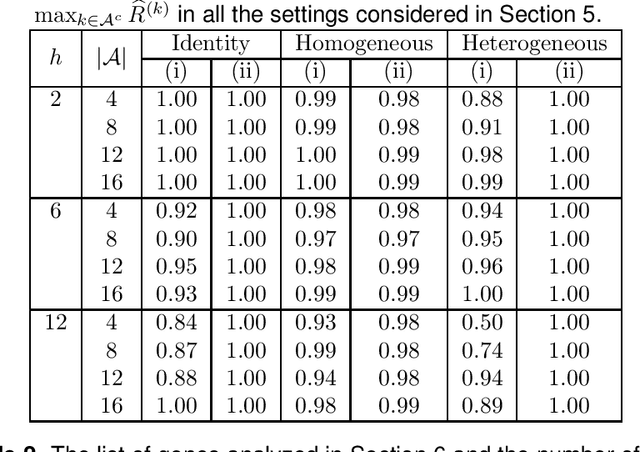
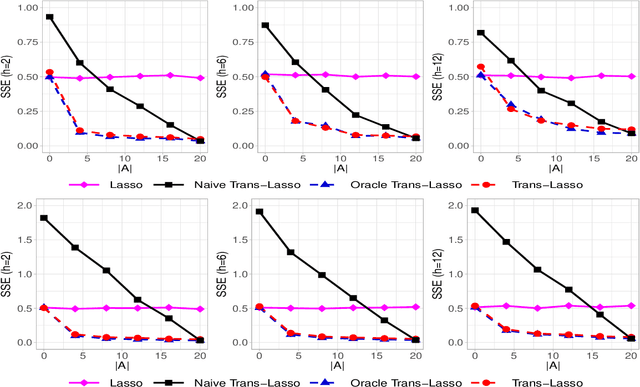
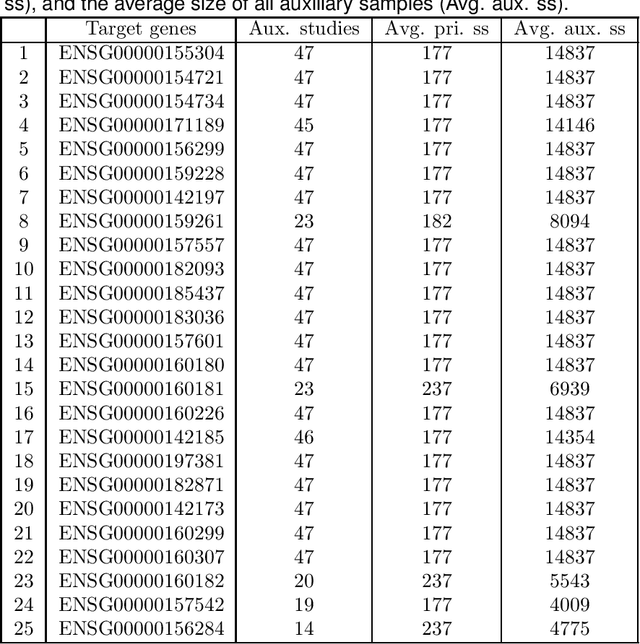
This paper considers the estimation and prediction of a high-dimensional linear regression in the setting of transfer learning, using samples from the target model as well as auxiliary samples from different but possibly related regression models. When the set of "informative" auxiliary samples is known, an estimator and a predictor are proposed and their optimality is established. The optimal rates of convergence for prediction and estimation are faster than the corresponding rates without using the auxiliary samples. This implies that knowledge from the informative auxiliary samples can be transferred to improve the learning performance of the target problem. In the case that the set of informative auxiliary samples is unknown, we propose a data-driven procedure for transfer learning, called Trans-Lasso, and reveal its robustness to non-informative auxiliary samples and its efficiency in knowledge transfer. The proposed procedures are demonstrated in numerical studies and are applied to a dataset concerning the associations among gene expressions. It is shown that Trans-Lasso leads to improved performance in gene expression prediction in a target tissue by incorporating the data from multiple different tissues as auxiliary samples.