 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeting Underrepresented Populations in Precision Medicine: A Federated Transfer Learning Approach
Paper and Code
Aug 27, 2021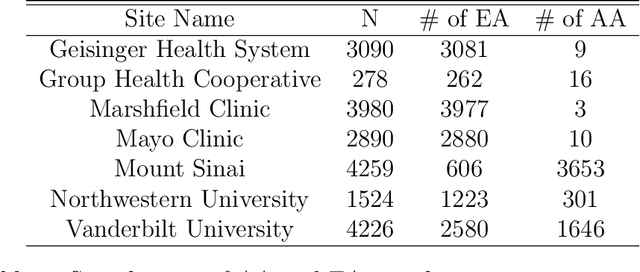

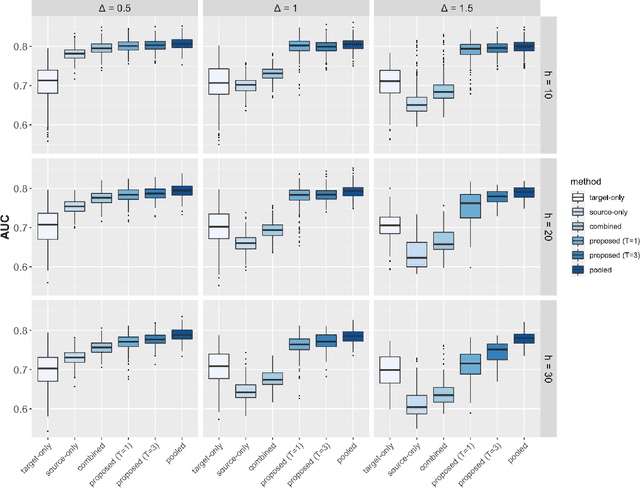
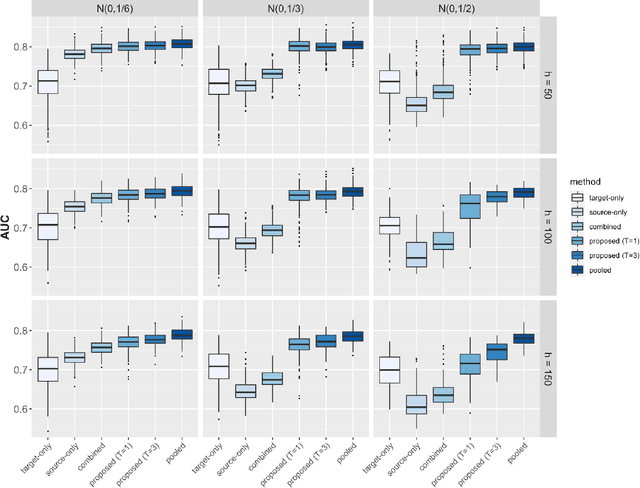
The limited representation of minorities and disadvantaged populations in large-scale clinical and genomics research has become a barrier to translating precision medicine research into practice. Due to heterogeneity across populations, risk prediction models are often found to be underperformed in these underrepresented populations, and therefore may further exacerbate known health disparities. In this paper, we propose a two-way data integration strategy that integrates heterogeneous data from diverse populations and from multiple healthcare institutions via a federated transfer learning approach. The proposed method can handle the challenging setting where sample sizes from different populations are highly unbalanced. With only a small number of communications across participating sites, the proposed method can achieve performance comparable to the pooled analysis where individual-level data are directly pooled together. We show that the proposed method improves the estimation and prediction accuracy in underrepresented populations, and reduces the gap of model performance across populations. Our theoretical analysis reveals how estimation accuracy is influenced by communication budgets, privacy restrictions, and heterogeneity across populations. We demonstrate the feasibility and validity of our methods through numerical experiments and a real application to a multi-center study, in which we construct polygenic risk prediction models for Type II diabetes in AA population.