 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Out-of-Distribution Robustness via Selective Augmentation
Paper and Code
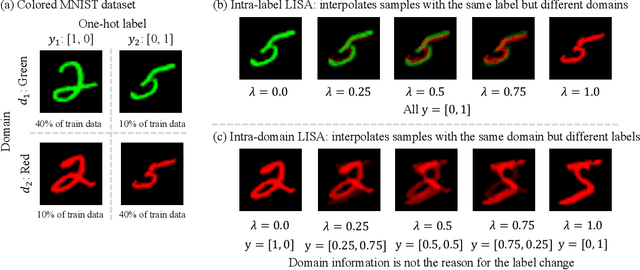
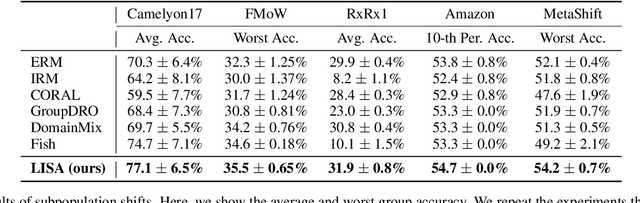
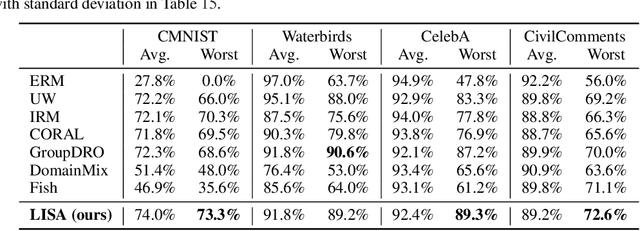
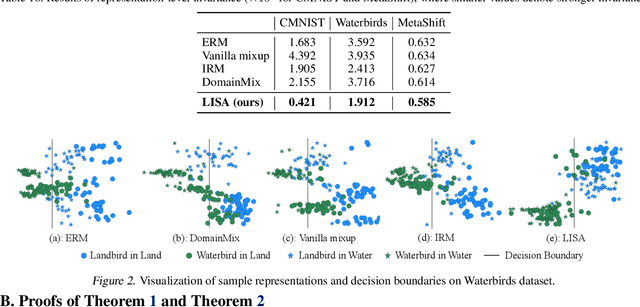
Machine learning algorithms typically assume that training and test examples are drawn from the same distribution. However, distribution shift is a common problem in real-world applications and can cause models to perform dramatically worse at test time. In this paper, we specifically consider the problems of domain shifts and subpopulation shifts (eg. imbalanced data). While prior works often seek to explicitly regularize internal representations and predictors of the model to be domain invariant, we instead aim to regularize the whole function without restricting the model's internal representations. This leads to a simple mixup-based technique which learns invariant functions via selective augmentation called LISA. LISA selectively interpolates samples either with the same labels but different domains or with the same domain but different labels. We analyze a linear setting and theoretically show how LISA leads to a smaller worst-group error. Empirically, we study the effectiveness of LISA on nine benchmarks ranging from subpopulation shifts to domain shifts, and we find that LISA consistently outperforms other state-of-the-art methods.