 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond What to Select: A Plug-and-play Oscillatory Data-Volume Scheduling for Efficient Model Training
May 14, 2026Data selection accelerates training by identifying representative training data while preserving model performance. However, existing methods mainly focus on designing sample-importance criteria, i.e., deciding what to select, while typically fixing the selected data volume as the target ratio throughout training. Thus, they are often dynamic in sample identity but static in data volume. In this work, we revisit data selection from an optimization perspective and show that selected-data training induces an implicit regularization effect modulated by the instantaneous selection ratio. This reveals a key trade-off: lower ratios amplify selection-induced regularization, whereas higher ratios preserve data coverage and optimization fidelity. Motivated by this insight, we propose PODS, a Plug-and-play Oscillatory Data-volume Scheduling framework. Rather than introducing another sample-scoring metric, PODS serves as a lightweight module that dynamically schedules how much data to select over training. Under the target selection ratio, PODS alternates between low-ratio regularization phases and high-ratio recovery phases to exploit selection-induced regularization without sacrificing optimization stability. With its lightweight, ratio-level, and task-agnostic design, PODS is compatible with existing static and dynamic selection methods and broadly applicable across training paradigms. Experiments across various datasets, architectures, and tasks show that PODS consistently improves the efficiency-generalization trade-off, e.g., reducing ImageNet-1k training cost by 50% with improved accuracy and accelerating LLM instruction tuning by over 2x without performance degradation.
Map++: Towards User-Participatory Visual SLAM Systems with Efficient Map Expansion and Sharing
Nov 04, 2024



Constructing precise 3D maps is crucial for the development of future map-based systems such as self-driving and navigation. However, generating these maps in complex environments, such as multi-level parking garages or shopping malls, remains a formidable challenge. In this paper, we introduce a participatory sensing approach that delegates map-building tasks to map users, thereby enabling cost-effective and continuous data collection. The proposed method harnesses the collective efforts of users, facilitating the expansion and ongoing update of the maps as the environment evolves. We realized this approach by developing Map++, an efficient system that functions as a plug-and-play extension, supporting participatory map-building based on existing SLAM algorithms. Map++ addresses a plethora of scalability issues in this participatory map-building system by proposing a set of lightweight, application-layer protocols. We evaluated Map++ in four representative settings: an indoor garage, an outdoor plaza, a public SLAM benchmark, and a simulated environment. The results demonstrate that Map++ can reduce traffic volume by approximately 46% with negligible degradation in mapping accuracy, i.e., less than 0.03m compared to the baseline system. It can support approximately $2 \times$ as many concurrent users as the baseline under the same network bandwidth. Additionally, for users who travel on already-mapped trajectories, they can directly utilize the existing maps for localization and save 47% of the CPU usage.
VPFNet: Improving 3D Object Detection with Virtual Point based LiDAR and Stereo Data Fusion
Dec 01, 2021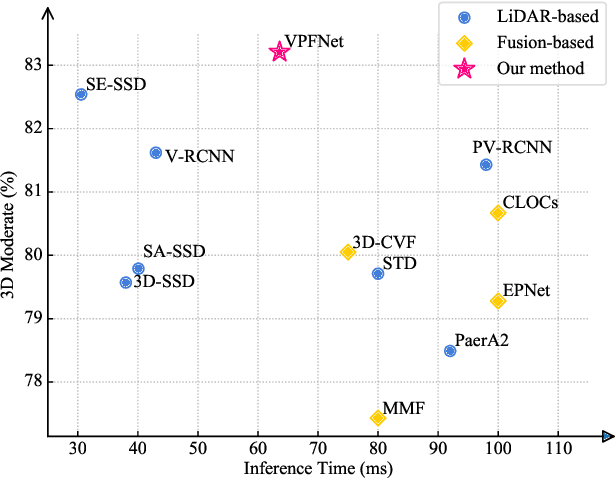

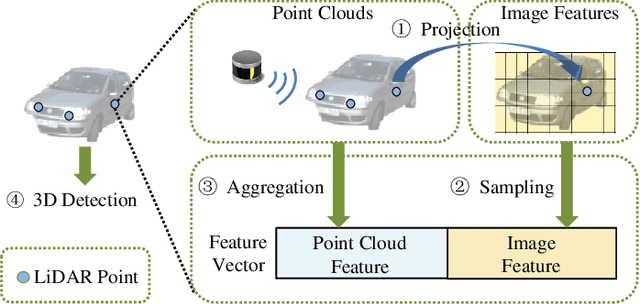
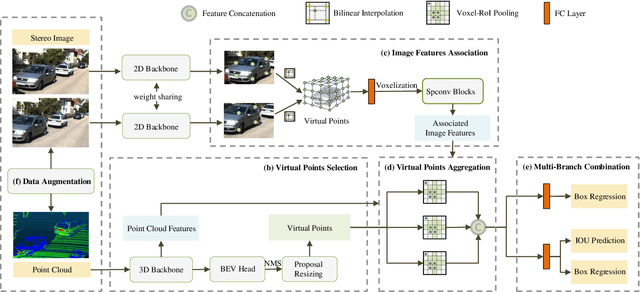
It has been well recognized that fusing the complementary information from depth-aware LiDAR point clouds and semantic-rich stereo images would benefit 3D object detection. Nevertheless, it is not trivial to explore the inherently unnatural interaction between sparse 3D points and dense 2D pixels. To ease this difficulty, the recent proposals generally project the 3D points onto the 2D image plane to sample the image data and then aggregate the data at the points. However, this approach often suffers from the mismatch between the resolution of point clouds and RGB images, leading to sub-optimal performance. Specifically, taking the sparse points as the multi-modal data aggregation locations causes severe information loss for high-resolution images, which in turn undermines the effectiveness of multi-sensor fusion. In this paper, we present VPFNet -- a new architecture that cleverly aligns and aggregates the point cloud and image data at the `virtual' points. Particularly, with their density lying between that of the 3D points and 2D pixels, the virtual points can nicely bridge the resolution gap between the two sensors, and thus preserve more information for processing. Moreover, we also investigate the data augmentation techniques that can be applied to both point clouds and RGB images, as the data augmentation has made non-negligible contribution towards 3D object detectors to date. We have conducted extensive experiments on KITTI dataset, and have observed good performance compared to the state-of-the-art methods. Remarkably, our VPFNet achieves 83.21\% moderate 3D AP and 91.86\% moderate BEV AP on the KITTI test set, ranking the 1st since May 21th, 2021. The network design also takes computation efficiency into consideration -- we can achieve a FPS of 15 on a single NVIDIA RTX 2080Ti GPU. The code will be made available for reproduction and further investigation.
Multi-Modal 3D Object Detection in Autonomous Driving: a Survey
Jun 25, 2021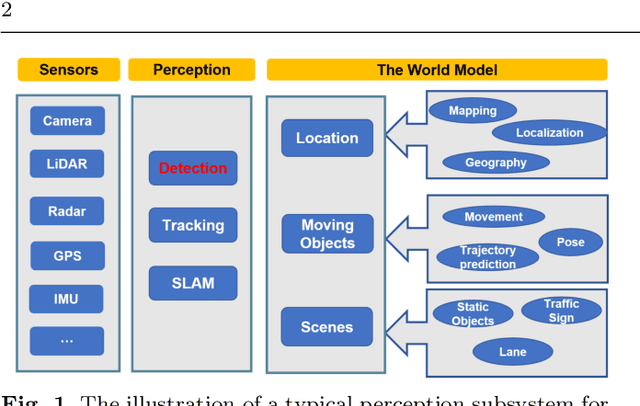
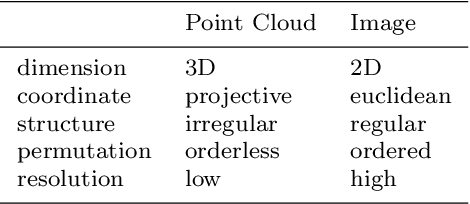

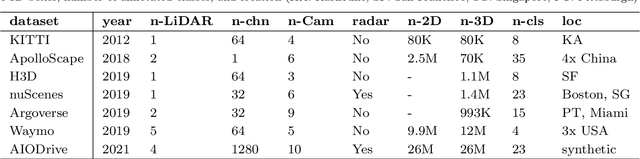
In the past few years, we have witnessed rapid development of autonomous driving. However, achieving full autonomy remains a daunting task due to the complex and dynamic driving environment. As a result, self-driving cars are equipped with a suite of sensors to conduct robust and accurate environment perception. As the number and type of sensors keep increasing, combining them for better perception is becoming a natural trend. So far, there has been no indepth review that focuses on multi-sensor fusion based perception. To bridge this gap and motivate future research, this survey devotes to review recent fusion-based 3D detection deep learning models that leverage multiple sensor data sources, especially cameras and LiDARs. In this survey, we first introduce the background of popular sensors for autonomous cars, including their common data representations as well as object detection networks developed for each type of sensor data. Next, we discuss some popular datasets for multi-modal 3D object detection, with a special focus on the sensor data included in each dataset. Then we present in-depth reviews of recent multi-modal 3D detection networks by considering the following three aspects of the fusion: fusion location, fusion data representation, and fusion granularity. After a detailed review, we discuss open challenges and point out possible solutions. We hope that our detailed review can help researchers to embark investigations in the area of multi-modal 3D object detection.