 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPFNet: Improving 3D Object Detection with Virtual Point based LiDAR and Stereo Data Fusion
Dec 01, 2021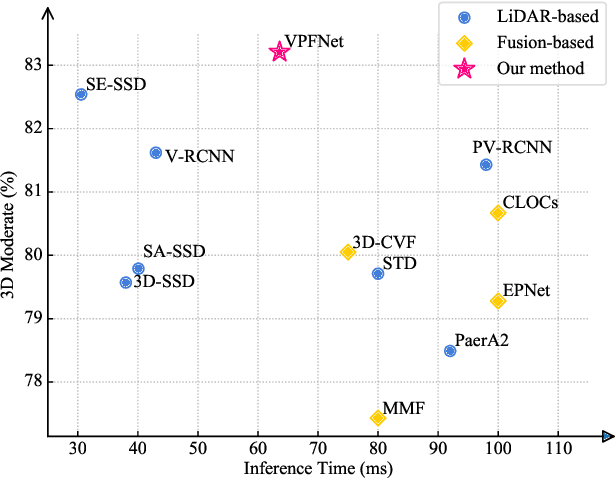

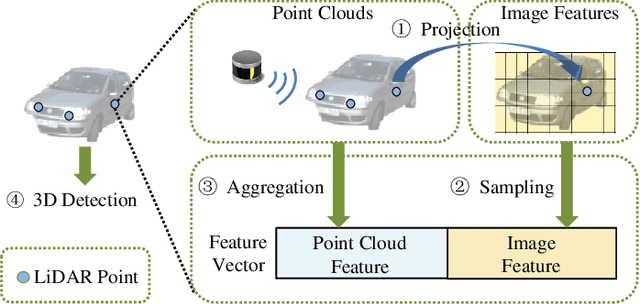
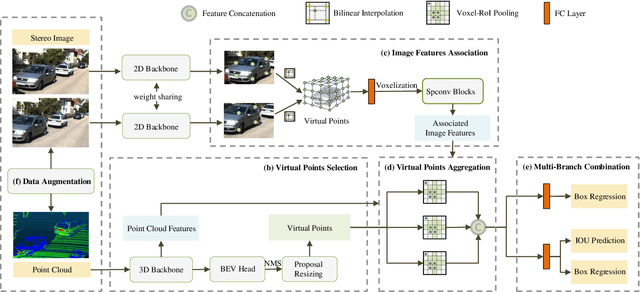
It has been well recognized that fusing the complementary information from depth-aware LiDAR point clouds and semantic-rich stereo images would benefit 3D object detection. Nevertheless, it is not trivial to explore the inherently unnatural interaction between sparse 3D points and dense 2D pixels. To ease this difficulty, the recent proposals generally project the 3D points onto the 2D image plane to sample the image data and then aggregate the data at the points. However, this approach often suffers from the mismatch between the resolution of point clouds and RGB images, leading to sub-optimal performance. Specifically, taking the sparse points as the multi-modal data aggregation locations causes severe information loss for high-resolution images, which in turn undermines the effectiveness of multi-sensor fusion. In this paper, we present VPFNet -- a new architecture that cleverly aligns and aggregates the point cloud and image data at the `virtual' points. Particularly, with their density lying between that of the 3D points and 2D pixels, the virtual points can nicely bridge the resolution gap between the two sensors, and thus preserve more information for processing. Moreover, we also investigate the data augmentation techniques that can be applied to both point clouds and RGB images, as the data augmentation has made non-negligible contribution towards 3D object detectors to date. We have conducted extensive experiments on KITTI dataset, and have observed good performance compared to the state-of-the-art methods. Remarkably, our VPFNet achieves 83.21\% moderate 3D AP and 91.86\% moderate BEV AP on the KITTI test set, ranking the 1st since May 21th, 2021. The network design also takes computation efficiency into consideration -- we can achieve a FPS of 15 on a single NVIDIA RTX 2080Ti GPU. The code will be made available for reproduction and further investigation.
Multi-Modal 3D Object Detection in Autonomous Driving: a Survey
Jun 25, 2021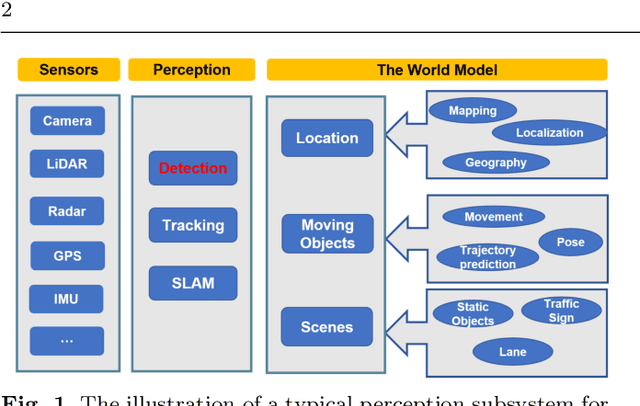
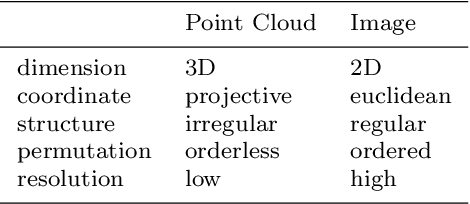

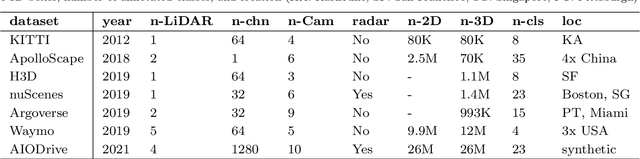
In the past few years, we have witnessed rapid development of autonomous driving. However, achieving full autonomy remains a daunting task due to the complex and dynamic driving environment. As a result, self-driving cars are equipped with a suite of sensors to conduct robust and accurate environment perception. As the number and type of sensors keep increasing, combining them for better perception is becoming a natural trend. So far, there has been no indepth review that focuses on multi-sensor fusion based perception. To bridge this gap and motivate future research, this survey devotes to review recent fusion-based 3D detection deep learning models that leverage multiple sensor data sources, especially cameras and LiDARs. In this survey, we first introduce the background of popular sensors for autonomous cars, including their common data representations as well as object detection networks developed for each type of sensor data. Next, we discuss some popular datasets for multi-modal 3D object detection, with a special focus on the sensor data included in each dataset. Then we present in-depth reviews of recent multi-modal 3D detection networks by considering the following three aspects of the fusion: fusion location, fusion data representation, and fusion granularity. After a detailed review, we discuss open challenges and point out possible solutions. We hope that our detailed review can help researchers to embark investigations in the area of multi-modal 3D object detection.