 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Clustering-friendly Representations: Subspace Clustering via Graph Filtering
Paper and Code
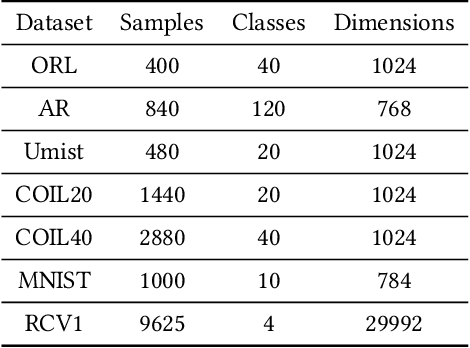
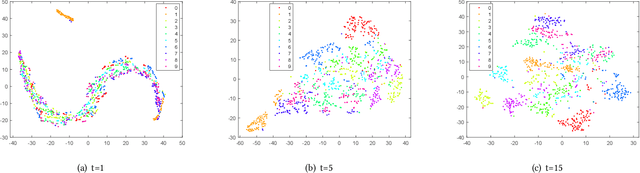
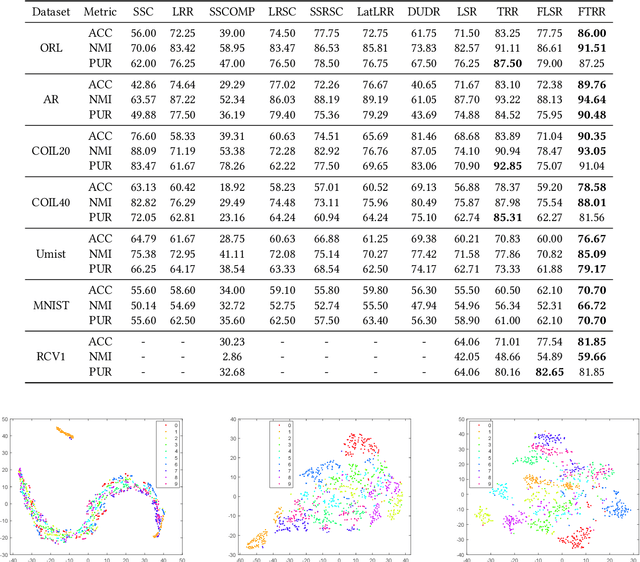

Finding a suitable data representation for a specific task has been shown to be crucial in many applications. The success of subspace clustering depends on the assumption that the data can be separated into different subspaces. However, this simple assumption does not always hold since the raw data might not be separable into subspaces. To recover the ``clustering-friendly'' representation and facilitate the subsequent clustering, we propose a graph filtering approach by which a smooth representation is achieved. Specifically, it injects graph similarity into data features by applying a low-pass filter to extract useful data representations for clustering. Extensive experiments on image and document clustering datasets demonstrate that our method improves upon state-of-the-art subspace clustering techniques. Especially, its comparable performance with deep learning methods emphasizes the effectiveness of the simple graph filtering scheme for many real-world applications. An ablation study shows that graph filtering can remove noise, preserve structure in the image, and increase the separability of classes.