 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonic Adversarial Attack Method
Paper and Code

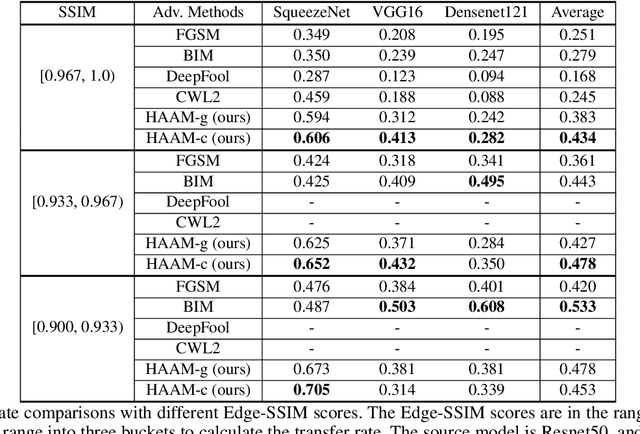

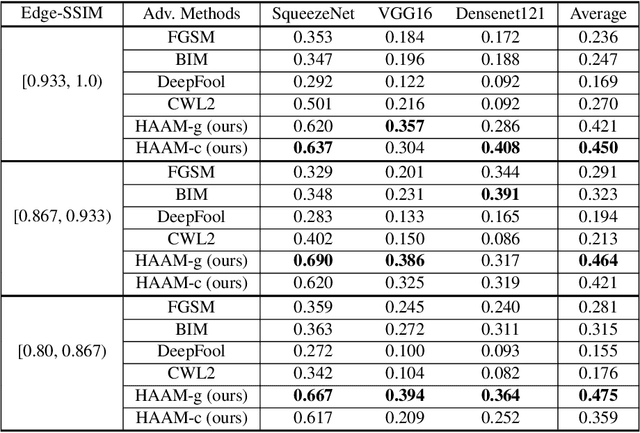
Adversarial attacks find perturbations that can fool models into misclassifying images. Previous works had successes in generating noisy/edge-rich adversarial perturbations, at the cost of degradation of image quality. Such perturbations, even when they are small in scale, are usually easily spottable by human vision. In contrast, we propose Harmonic Adversar- ial Attack Methods (HAAM), that generates edge-free perturbations by using harmonic functions. The property of edge-free guarantees that the generated adversarial images can still preserve visual quality, even when perturbations are of large magnitudes. Experiments also show that adversaries generated by HAAM often have higher rates of success when transferring between models. In addition, we find harmonic perturbations can simulate natural phenomena like natural lighting and shadows. It would then be possible to help find corner cases for given models, as a first step to improving them.