 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPO: Global Plane Optimization for Fast and Accurate Monocular SLAM Initialization
May 24, 2020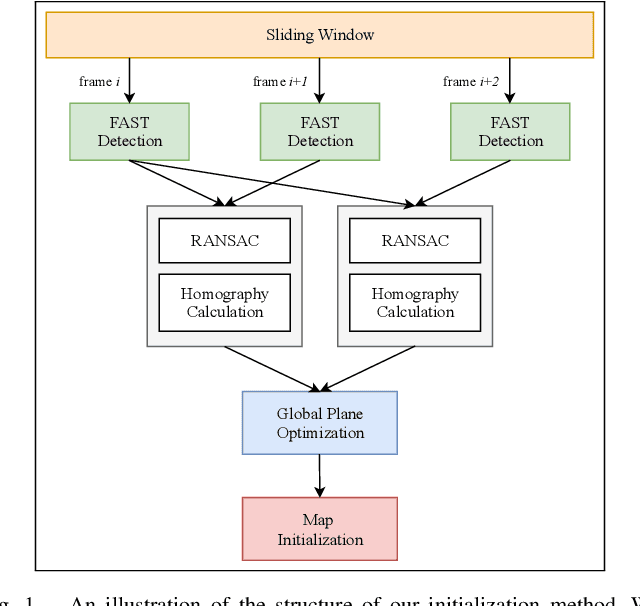
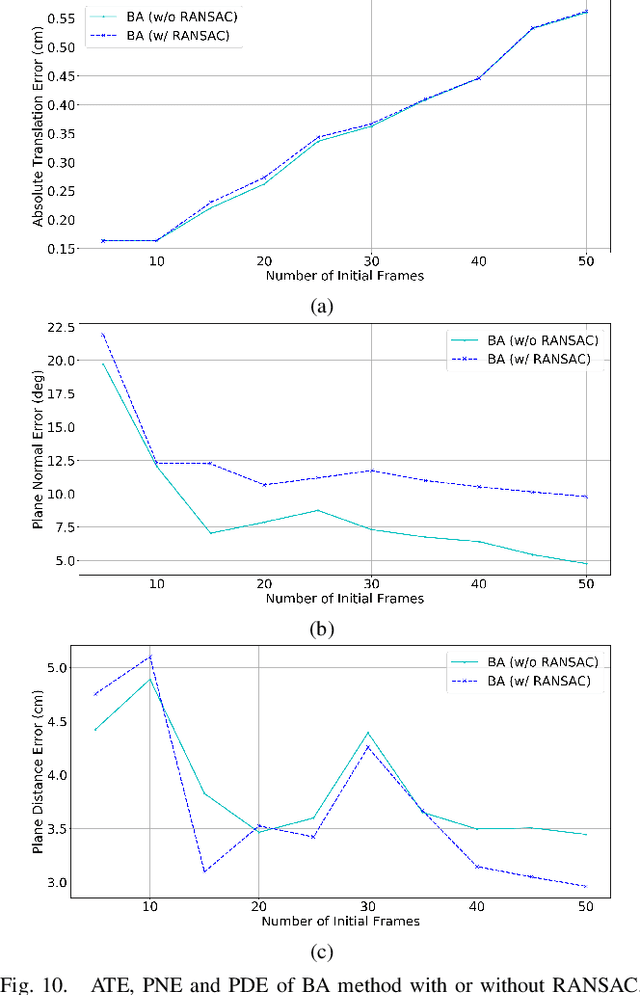
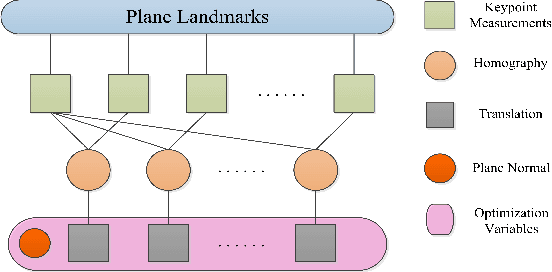

Initialization is essential to monocular Simultaneous Localization and Mapping (SLAM) problems. This paper focuses on a novel initialization method for monocular SLAM based on planar features. The algorithm starts by homography estimation in a sliding window. It then proceeds to a global plane optimization (GPO) to obtain camera poses and the plane normal. 3D points can be recovered using planar constraints without triangulation. The proposed method fully exploits the plane information from multiple frames and avoids the ambiguities in homography decomposition. We validate our algorithm on the collected chessboard dataset against baseline implementations and present extensive analysis. Experimental results show that our method outperforms the fine-tuned baselines in both accuracy and real-time.
DeepSquare: Boosting the Learning Power of Deep Convolutional Neural Networks with Elementwise Square Operators
Jun 12, 2019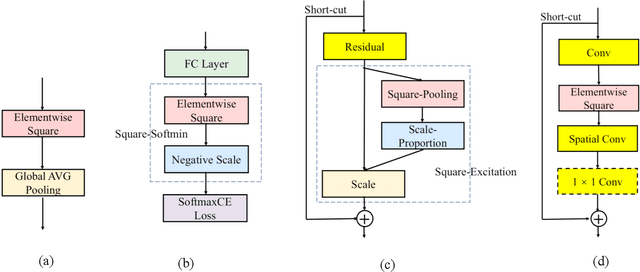
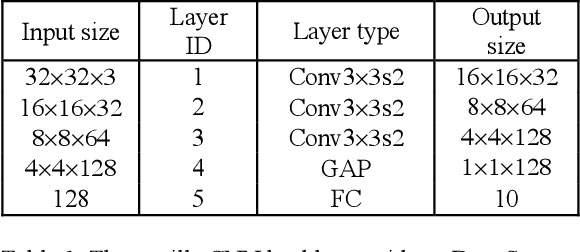
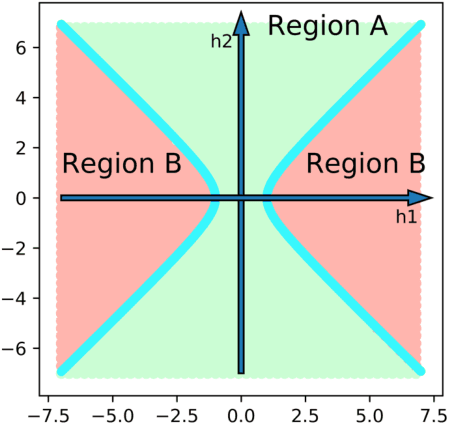
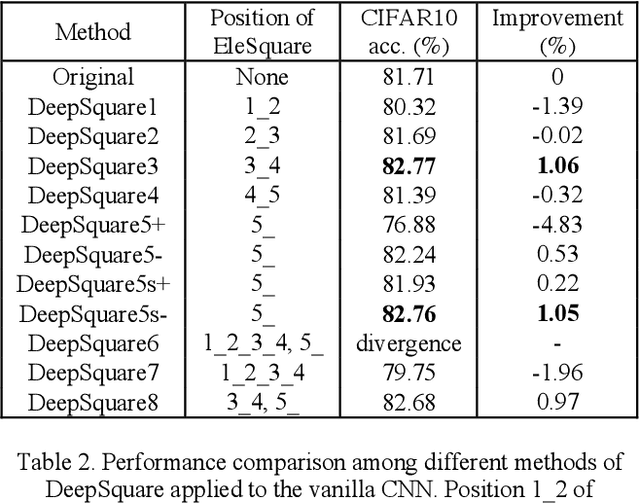
Modern neural network modules which can significantly enhance the learning power usually add too much computational complexity to the original neural networks. In this paper, we pursue very efficient neural network modules which can significantly boost the learning power of deep convolutional neural networks with negligible extra computational cost. We first present both theoretically and experimentally that elementwise square operator has a potential to enhance the learning power of neural networks. Then, we design four types of lightweight modules with elementwise square operators, named as Square-Pooling, Square-Softmin, Square-Excitation, and Square-Encoding. We add our four lightweight modules to Resnet18, Resnet50, and ShuffleNetV2 for better performance in the experiment on ImageNet 2012 dataset. The experimental results show that our modules can bring significant accuracy improvements to the base convolutional neural network models. The performance of our lightweight modules is even comparable to many complicated modules such as bilinear pooling, Squeeze-and-Excitation, and Gather-Excite. Our highly efficient modules are particularly suitable for mobile models. For example, when equipped with a single Square-Pooling module, the top-1 classification accuracy of ShuffleNetV2-0.5x on ImageNet 2012 is absolutely improved by 1.45% with no additional parameters and negligible inference time overhead.
Multi-Domain Pose Network for Multi-Person Pose Estimation and Tracking
Oct 19, 2018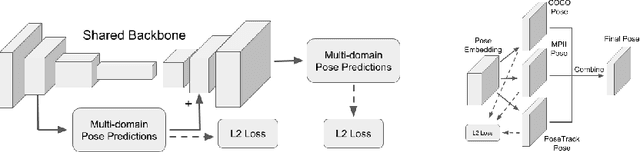


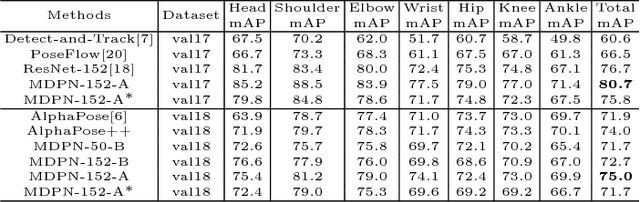
Multi-person human pose estimation and tracking in the wild is important and challenging. For training a powerful model, large-scale training data are crucial. While there are several datasets for human pose estimation, the best practice for training on multi-dataset has not been investigated. In this paper, we present a simple network called Multi-Domain Pose Network (MDPN) to address this problem. By treating the task as multi-domain learning, our methods can learn a better representation for pose prediction. Together with prediction heads fine-tuning and multi-branch combination, it shows significant improvement over baselines and achieves the best performance on PoseTrack ECCV 2018 Challenge without additional datasets other than MPII and COCO.