 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-autoregressive Mandarin-English Code-switching Speech Recognition with Pinyin Mask-CTC and Word Embedding Regularization
Paper and Code
Apr 06, 2021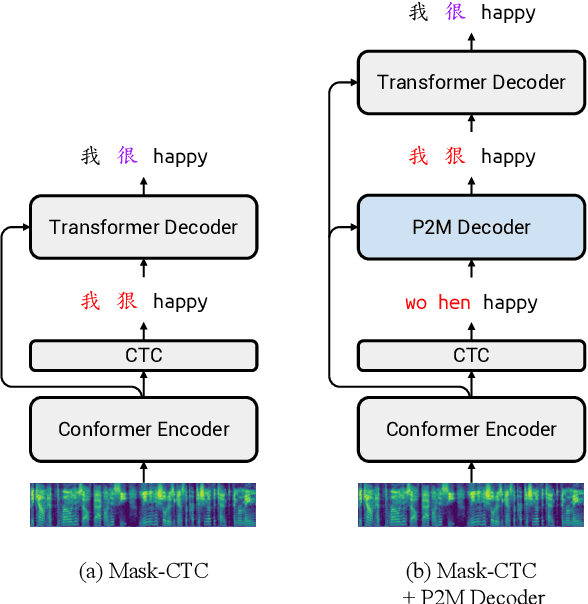
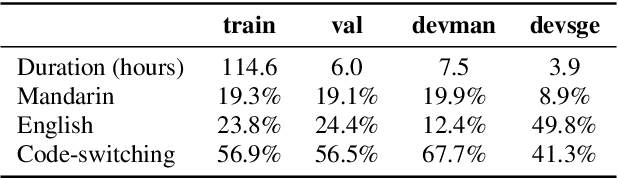
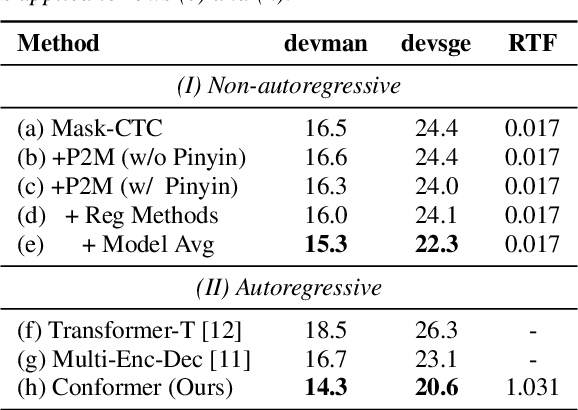
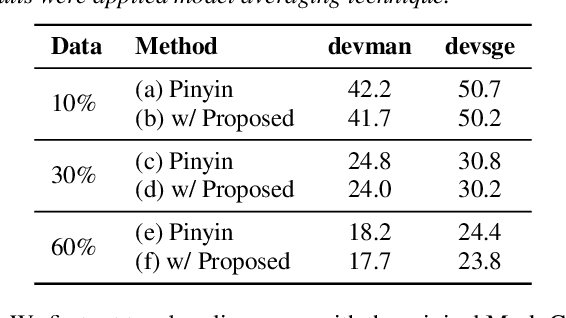
Mandarin-English code-switching (CS) is frequently used among East and Southeast Asian people. However, the intra-sentence language switching of the two very different languages makes recognizing CS speech challenging. Meanwhile, the recent successful non-autoregressive (NAR) ASR models remove the need for left-to-right beam decoding in autoregressive (AR) models and achieved outstanding performance and fast inference speed. Therefore, in this paper, we took advantage of the Mask-CTC NAR ASR framework to tackle the CS speech recognition issue. We propose changing the Mandarin output target of the encoder to Pinyin for faster encoder training, and introduce Pinyin-to-Mandarin decoder to learn contextualized information. Moreover, we propose word embedding label smoothing to regularize the decoder with contextualized information and projection matrix regularization to bridge that gap between the encoder and decoder. We evaluate the proposed methods on the SEAME corpus and achieved exciting results.