 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipation-free Training for Simultaneous Translation
Jan 30, 2022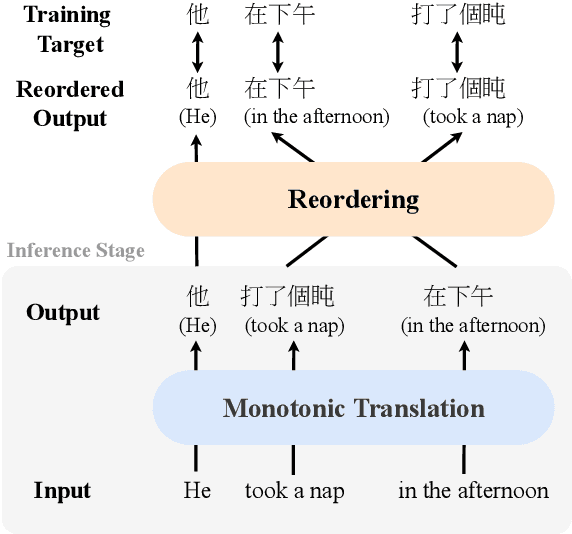



Simultaneous translation (SimulMT) speeds up the translation process by starting to translate before the source sentence is completely available. It is difficult due to limited context and word order difference between languages. Existing methods increase latency or introduce adaptive read-write policies for SimulMT models to handle local reordering and improve translation quality. However, the long-distance reordering would make the SimulMT models learn translation mistakenly. Specifically, the model may be forced to predict target tokens when the corresponding source tokens have not been read. This leads to aggressive anticipation during inference, resulting in the hallucination phenomenon. To mitigate this problem, we propose a new framework that decompose the translation process into the monotonic translation step and the reordering step, and we model the latter by the auxiliary sorting network (ASN). The ASN rearranges the hidden states to match the order in the target language, so that the SimulMT model could learn to translate more reasonably. The entire model is optimized end-to-end and does not rely on external aligners or data. During inference, ASN is removed to achieve streaming. Experiments show the proposed framework could outperform previous methods with less latency.\footnote{The source code is available.
Investigating the Reordering Capability in CTC-based Non-Autoregressive End-to-End Speech Translation
May 11, 2021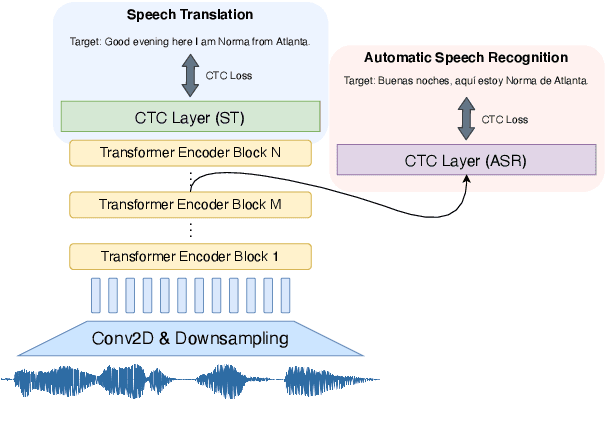
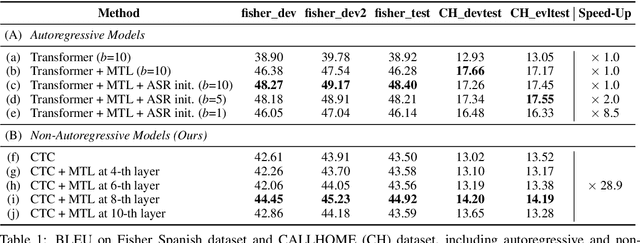
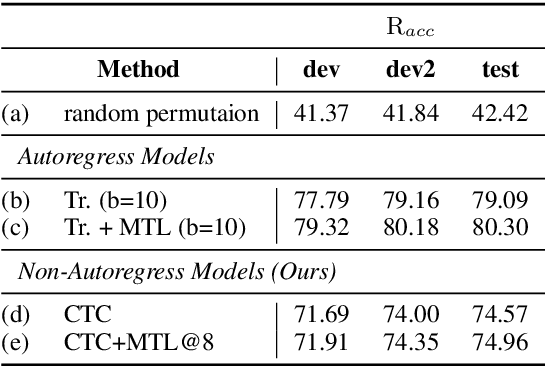
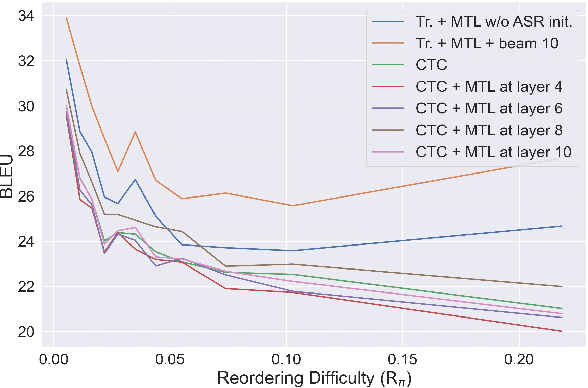
We study the possibilities of building a non-autoregressive speech-to-text translation model using connectionist temporal classification (CTC), and use CTC-based automatic speech recognition as an auxiliary task to improve the performance. CTC's success on translation is counter-intuitive due to its monotonicity assumption, so we analyze its reordering capability. Kendall's tau distance is introduced as the quantitative metric, and gradient-based visualization provides an intuitive way to take a closer look into the model. Our analysis shows that transformer encoders have the ability to change the word order and points out the future research direction that worth being explored more on non-autoregressive speech translation.