 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlmost-unsupervised Speech Recognition with Close-to-zero Resource Based on Phonetic Structures Learned from Very Small Unpaired Speech and Text Data
Paper and Code
Oct 30, 2018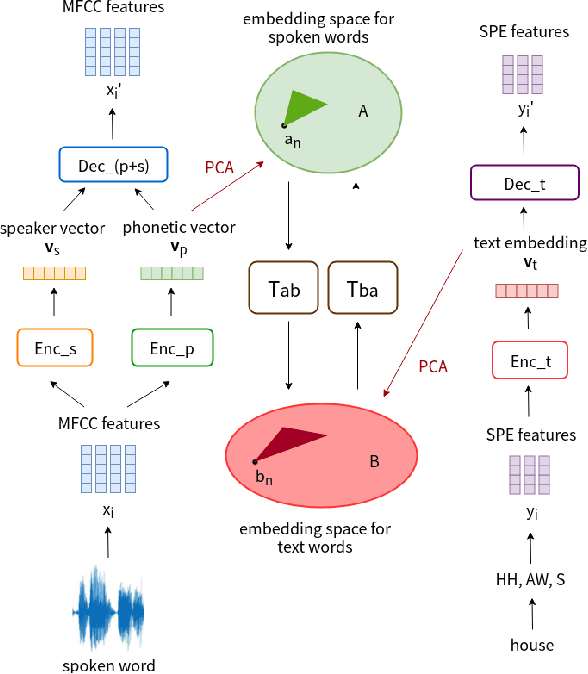
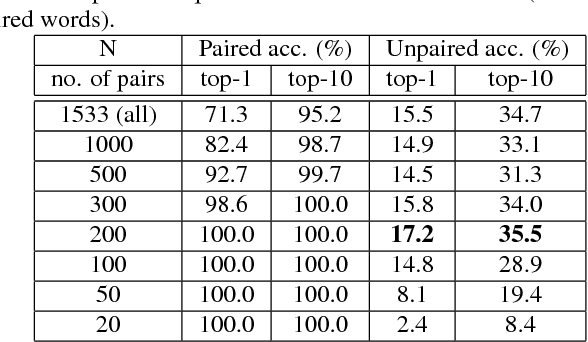
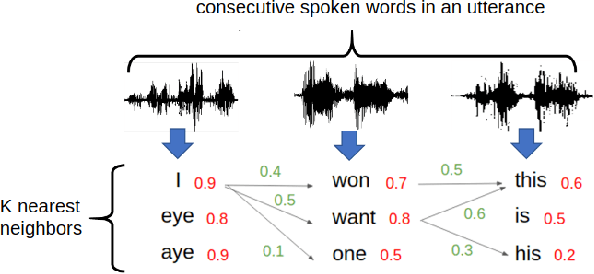
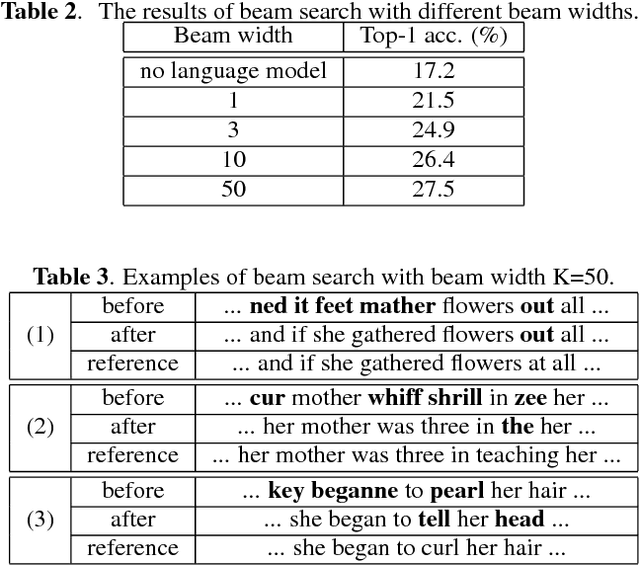
Producing a large amount of annotated speech data for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced. However, we note human babies start to learn the language by the sounds of a small number of exemplar words without hearing a large amount of data. We initiate some preliminary work in this direction in this paper. Audio Word2Vec is used to obtain embeddings of spoken words which carry phonetic information extracted from the signals. An autoencoder is used to generate embeddings of text words based on the articulatory features for the phoneme sequences. Both sets of embeddings for spoken and text words describe similar phonetic structures among words in their respective latent spaces. A mapping relation from the audio embeddings to text embeddings actually gives the word-level ASR. This can be learned by aligning a small number of spoken words and the corresponding text words in the embedding spaces. In the initial experiments only 200 annotated spoken words and one hour of speech data without annotation gave a word accuracy of 27.5%, which is low but a good starting point.