 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Representation Learning Through Self-supervised Pretraining And Multi-task Finetuning
Paper and Code
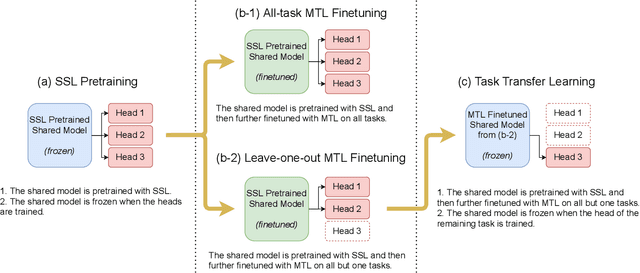
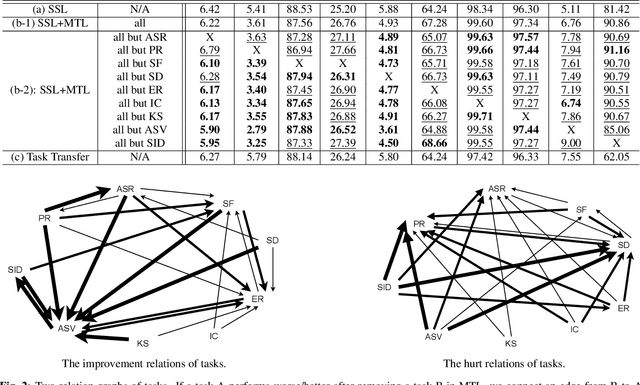
Speech representation learning plays a vital role in speech processing. Among them, self-supervised learning (SSL) has become an important research direction. It has been shown that an SSL pretraining model can achieve excellent performance in various downstream tasks of speech processing. On the other hand, supervised multi-task learning (MTL) is another representation learning paradigm, which has been proven effective in computer vision (CV) and natural language processing (NLP). However, there is no systematic research on the general representation learning model trained by supervised MTL in speech processing. In this paper, we show that MTL finetuning can further improve SSL pretraining. We analyze the generalizability of supervised MTL finetuning to examine if the speech representation learned by MTL finetuning can generalize to unseen new tasks.