 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonetic-and-Semantic Embedding of Spoken Words with Applications in Spoken Content Retrieval
Paper and Code
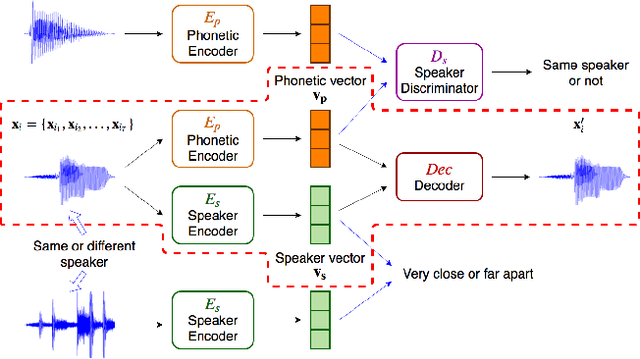
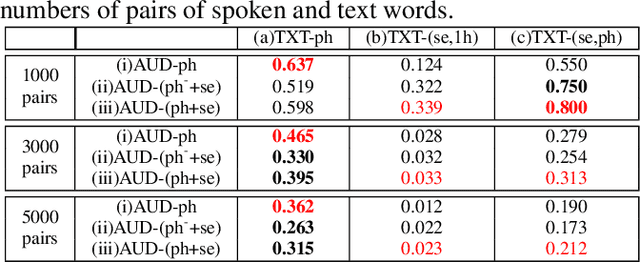
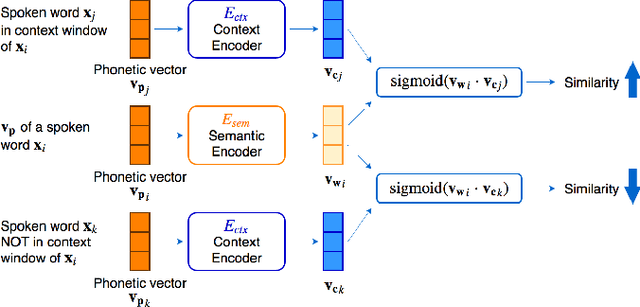
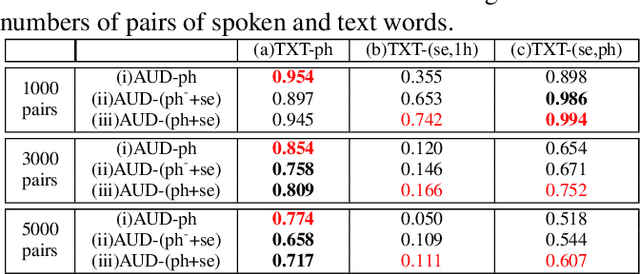
Word embedding or Word2Vec has been successful in offering semantics for text words learned from the context of words. Audio Word2Vec was shown to offer phonetic structures for spoken words (signal segments for words) learned from signals within spoken words. This paper proposes a two-stage framework to perform phonetic-and-semantic embedding on spoken words considering the context of the spoken words. Stage 1 performs phonetic embedding with speaker characteristics disentangled. Stage 2 then performs semantic embedding in addition. We further propose to evaluate the phonetic-and-semantic nature of the audio embeddings obtained in Stage 2 by parallelizing with text embeddings. In general, phonetic structure and semantics inevitably disturb each other. For example the words "brother" and "sister" are close in semantics but very different in phonetic structure, while the words "brother" and "bother" are in the other way around. But phonetic-and-semantic embedding is attractive, as shown in the initial experiments on spoken document retrieval. Not only spoken documents including the spoken query can be retrieved based on the phonetic structures, but spoken documents semantically related to the query but not including the query can also be retrieved based on the semantics.