 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Semi-supervised to Almost-unsupervised Speech Recognition with Very-low Resource by Jointly Learning Phonetic Structures from Audio and Text Embeddings
Paper and Code
Apr 10, 2019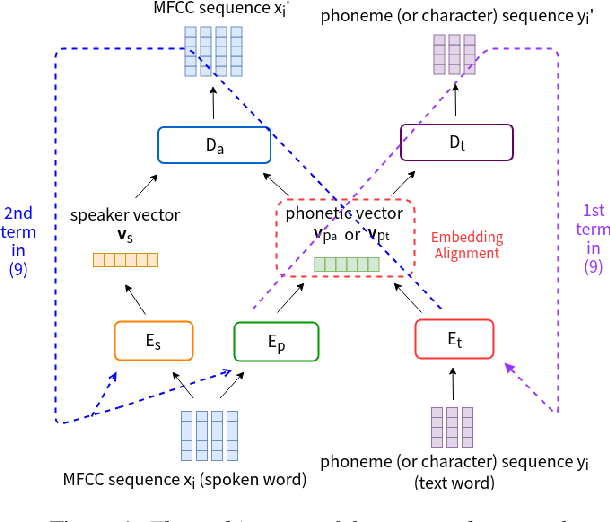
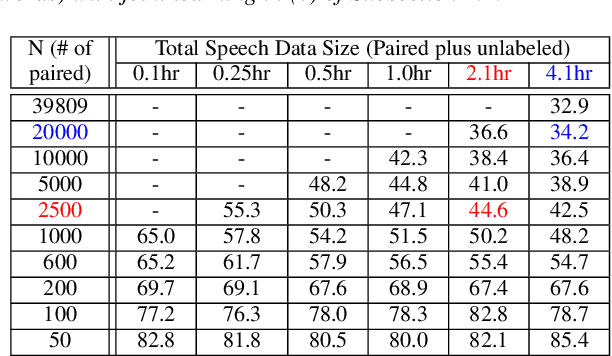
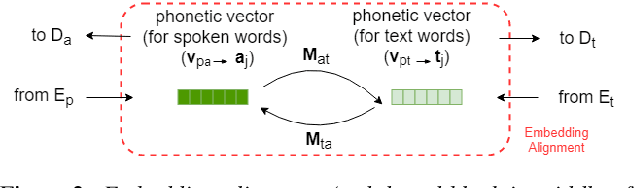

Producing a large amount of annotated speech data for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced. However, we note human babies start to learn the language by the sounds (or phonetic structures) of a small number of exemplar words, and "generalize" such knowledge to other words without hearing a large amount of data. We initiate some preliminary work in this direction. Audio Word2Vec is used to learn the phonetic structures from spoken words (signal segments), while another autoencoder is used to learn the phonetic structures from text words. The relationships among the above two can be learned jointly, or separately after the above two are well trained. This relationship can be used in speech recognition with very low resource. In the initial experiments on the TIMIT dataset, only 2.1 hours of speech data (in which 2500 spoken words were annotated and the rest unlabeled) gave a word error rate of 44.6%, and this number can be reduced to 34.2% if 4.1 hr of speech data (in which 20000 spoken words were annotated) were given. These results are not satisfactory, but a good starting point.