 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Recurrence Modeling for Video Action Anticipation
Paper and Code
Jun 02, 2022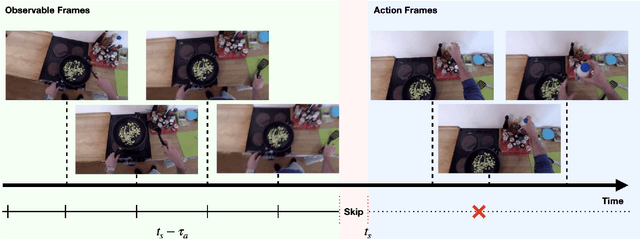
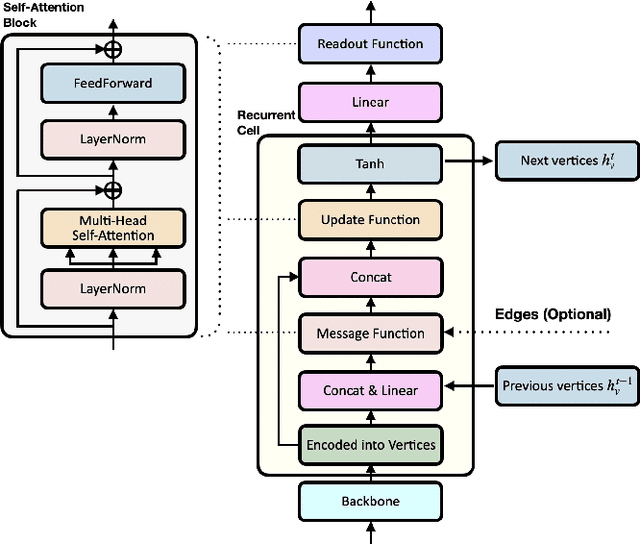


Forecasting future events based on evidence of current conditions is an innate skill of human beings, and key for predicting the outcome of any decision making. In artificial vision for example, we would like to predict the next human action before it happens, without observing the future video frames associated to it. Computer vision models for action anticipation are expected to collect the subtle evidence in the preamble of the target actions. In prior studies recurrence modeling often leads to better performance, the strong temporal inference is assumed to be a key element for reasonable prediction. To this end, we propose a unified recurrence modeling for video action anticipation via message passing framework. The information flow in space-time can be described by the interaction between vertices and edges, and the changes of vertices for each incoming frame reflects the underlying dynamics. Our model leverages self-attention as the building blocks for each of the message passing functions. In addition, we introduce different edge learning strategies that can be end-to-end optimized to gain better flexibility for the connectivity between vertices. Our experimental results demonstrate that our proposed method outperforms previous works on the large-scale EPIC-Kitchen dataset.