 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Feature Learning Against Noisy Labels
Jul 10, 2023



Supervised learning of deep neural networks heavily relies on large-scale datasets annotated by high-quality labels. In contrast, mislabeled samples can significantly degrade the generalization of models and result in memorizing samples, further learning erroneous associations of data contents to incorrect annotations. To this end, this paper proposes an efficient approach to tackle noisy labels by learning robust feature representation based on unsupervised augmentation restoration and cluster regularization. In addition, progressive self-bootstrapping is introduced to minimize the negative impact of supervision from noisy labels. Our proposed design is generic and flexible in applying to existing classification architectures with minimal overheads. Experimental results show that our proposed method can efficiently and effectively enhance model robustness under severely noisy labels.
Inductive Attention for Video Action Anticipation
Dec 17, 2022



Anticipating future actions based on video observations is an important task in video understanding, which would be useful for some precautionary systems that require response time to react before an event occurs. Since the input in action anticipation is only pre-action frames, models do not have enough information about the target action; moreover, similar pre-action frames may lead to different futures. Consequently, any solution using existing action recognition models can only be suboptimal. Recently, researchers have proposed using a longer video context to remedy the insufficient information in pre-action intervals, as well as the self-attention to query past relevant moments to address the anticipation problem. However, the indirect use of video input features as the query might be inefficient, as it only serves as the proxy to the anticipation goal. To this end, we propose an inductive attention model, which transparently uses prior prediction as the query to derive the anticipation result by induction from past experience. Our method naturally considers the uncertainty of multiple futures via the many-to-many association. On the large-scale egocentric video datasets, our model not only shows consistently better performance than state of the art using the same backbone, and is competitive to the methods that employ a stronger backbone, but also superior efficiency in less model parameters.
NVIDIA-UNIBZ Submission for EPIC-KITCHENS-100 Action Anticipation Challenge 2022
Jun 22, 2022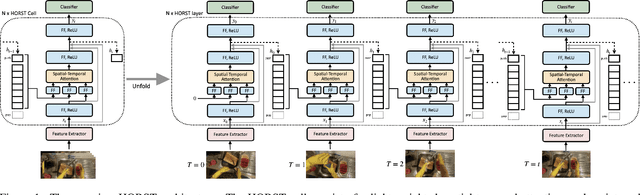
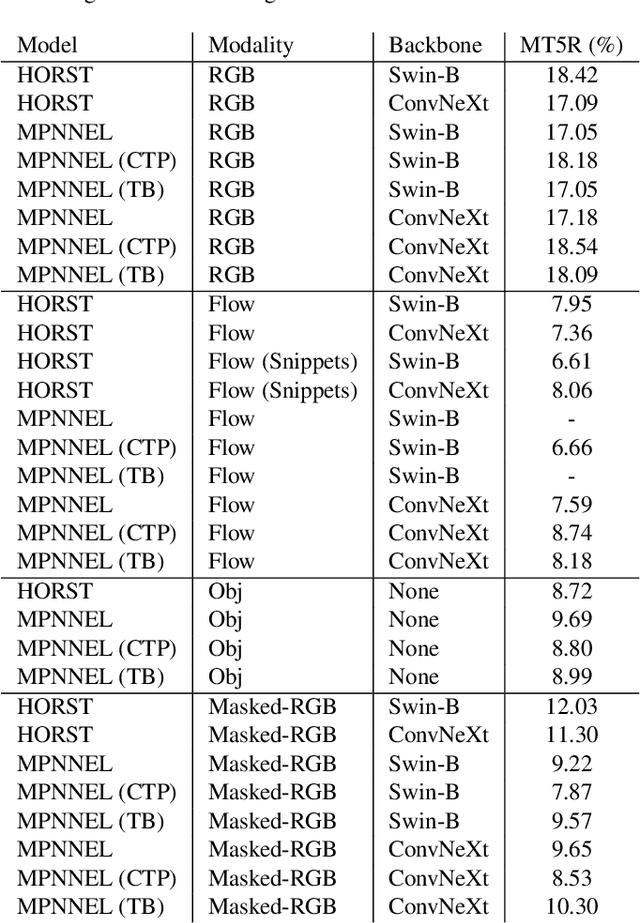
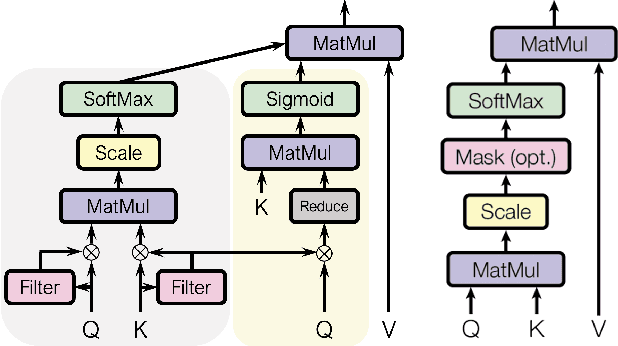

In this report, we describe the technical details of our submission for the EPIC-Kitchen-100 action anticipation challenge. Our modelings, the higher-order recurrent space-time transformer and the message-passing neural network with edge learning, are both recurrent-based architectures which observe only 2.5 seconds inference context to form the action anticipation prediction. By averaging the prediction scores from a set of models compiled with our proposed training pipeline, we achieved strong performance on the test set, which is 19.61% overall mean top-5 recall, recorded as second place on the public leaderboard.
Unified Recurrence Modeling for Video Action Anticipation
Jun 02, 2022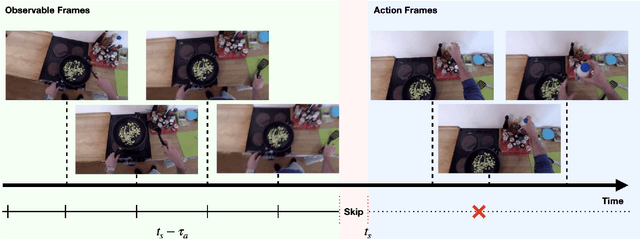
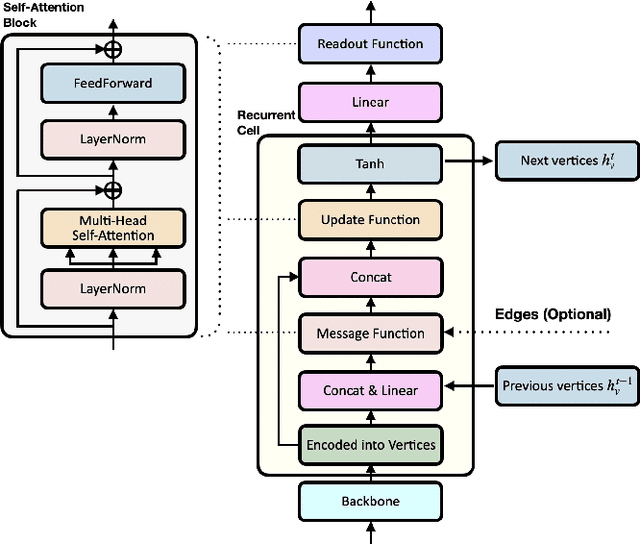


Forecasting future events based on evidence of current conditions is an innate skill of human beings, and key for predicting the outcome of any decision making. In artificial vision for example, we would like to predict the next human action before it happens, without observing the future video frames associated to it. Computer vision models for action anticipation are expected to collect the subtle evidence in the preamble of the target actions. In prior studies recurrence modeling often leads to better performance, the strong temporal inference is assumed to be a key element for reasonable prediction. To this end, we propose a unified recurrence modeling for video action anticipation via message passing framework. The information flow in space-time can be described by the interaction between vertices and edges, and the changes of vertices for each incoming frame reflects the underlying dynamics. Our model leverages self-attention as the building blocks for each of the message passing functions. In addition, we introduce different edge learning strategies that can be end-to-end optimized to gain better flexibility for the connectivity between vertices. Our experimental results demonstrate that our proposed method outperforms previous works on the large-scale EPIC-Kitchen dataset.
Speckle Image Restoration without Clean Data
May 18, 2022
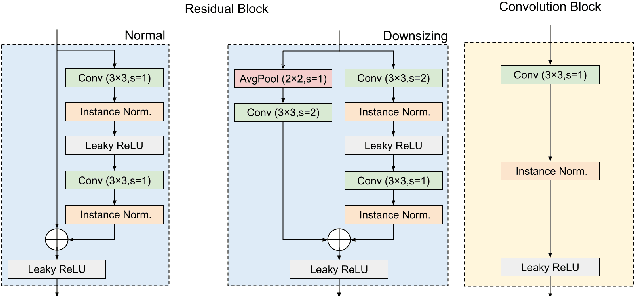


Speckle noise is an inherent disturbance in coherent imaging systems such as digital holography, synthetic aperture radar, optical coherence tomography, or ultrasound systems. These systems usually produce only single observation per view angle of the same interest object, imposing the difficulty to leverage the statistic among observations. We propose a novel image restoration algorithm that can perform speckle noise removal without clean data and does not require multiple noisy observations in the same view angle. Our proposed method can also be applied to the situation without knowing the noise distribution as prior. We demonstrate our method is especially well-suited for spectral images by first validating on the synthetic dataset, and also applied on real-world digital holography samples. The results are superior in both quantitative measurement and visual inspection compared to several widely applied baselines. Our method even shows promising results across different speckle noise strengths, without the clean data needed.
Higher Order Recurrent Space-Time Transformer
Apr 17, 2021
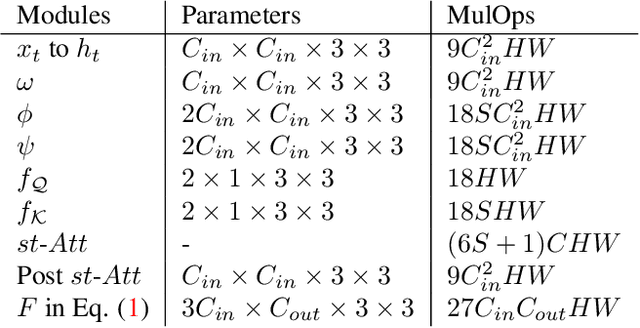


Endowing visual agents with predictive capability is a key step towards video intelligence at scale. The predominant modeling paradigm for this is sequence learning, mostly implemented through LSTMs. Feed-forward Transformer architectures have replaced recurrent model designs in ML applications of language processing and also partly in computer vision. In this paper we investigate on the competitiveness of Transformer-style architectures for video predictive tasks. To do so we propose HORST, a novel higher order recurrent layer design whose core element is a spatial-temporal decomposition of self-attention for video. HORST achieves state of the art competitive performance on Something-Something-V2 early action recognition and EPIC-Kitchens-55 action anticipation, without exploiting a task specific design. We believe this is promising evidence of causal predictive capability that we attribute to our recurrent higher order design of self-attention.
An Intelligent QoS Algorithm for Home Networks
Jul 22, 2020


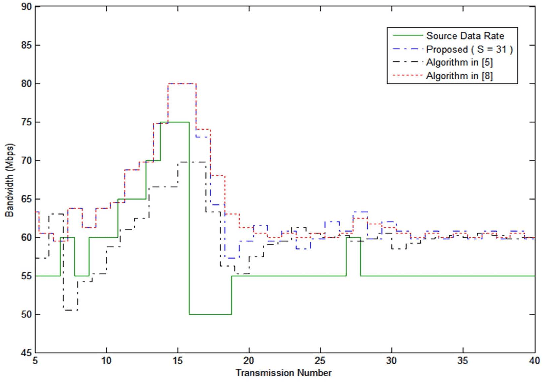
A novel quality of service (QoS) management algorithm for home networks is presented in this letter. The algorithm is based on service prediction for intelligent QoS management. The service prediction is carried out by a general regression neural network with a profile containing the past records of the service. A novel profile updating technique is proposed so that the profile size can remain small for fast bandwidth allocation. The analytical study and experiments over real LAN reveal that the proposed algorithm provides reliable QoS management for home networks with low computational overhead.
Sensor-Based Continuous Hand Gesture Recognition by Long Short-Term Memory
Jul 22, 2020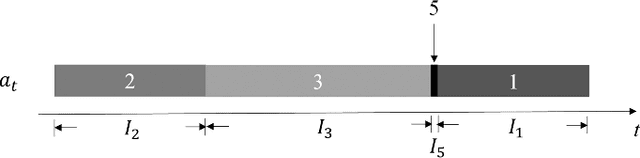


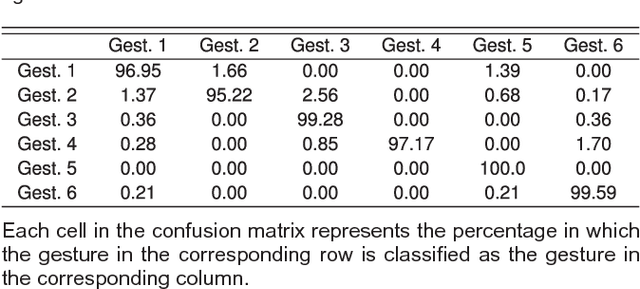
This article aims to present a novel sensor-based continuous hand gesture recognition algorithm by long short-term memory (LSTM). Only the basic accelerators and/or gyroscopes are required by the algorithm. Given a sequence of input sensory data, a many-to-many LSTM scheme is adopted to produce an output path. A maximum a posteriori estimation is then carried out based on the observed path to obtain the final classification results. A prototype system based on smartphones has been implemented for the performance evaluation. Experimental results show that the proposed algorithm is an effective alternative for robust and accurate hand-gesture recognition.