 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra-Low Latency Speech Enhancement - A Comprehensive Study
Paper and Code
Sep 16, 2024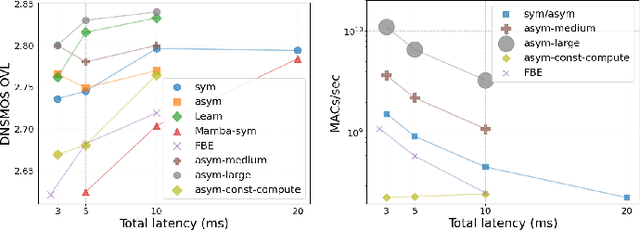


Speech enhancement models should meet very low latency requirements typically smaller than 5 ms for hearing assistive devices. While various low-latency techniques have been proposed, comparing these methods in a controlled setup using DNNs remains blank. Previous papers have variations in task, training data, scripts, and evaluation settings, which make fair comparison impossible. Moreover, all methods are tested on small, simulated datasets, making it difficult to fairly assess their performance in real-world conditions, which could impact the reliability of scientific findings. To address these issues, we comprehensively investigate various low-latency techniques using consistent training on large-scale data and evaluate with more relevant metrics on real-world data. Specifically, we explore the effectiveness of asymmetric windows, learnable windows, adaptive time domain filterbanks, and the future-frame prediction technique. Additionally, we examine whether increasing the model size can compensate for the reduced window size, as well as the novel Mamba architecture in low-latency environments.