 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeta-Rank: A Robust Convolutional Filter Pruning Method For Imbalanced Medical Image Analysis
Paper and Code
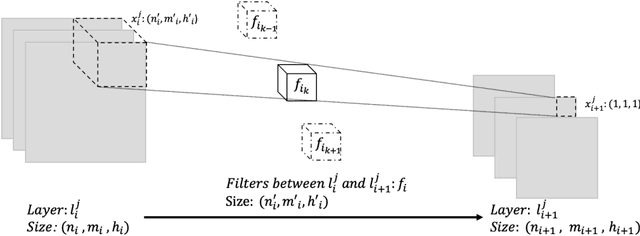
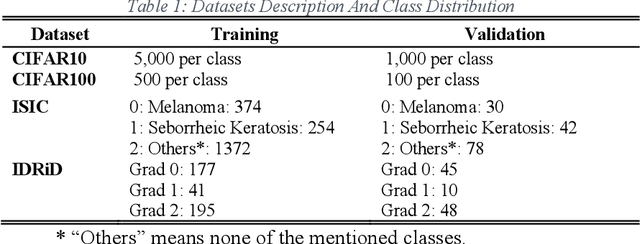
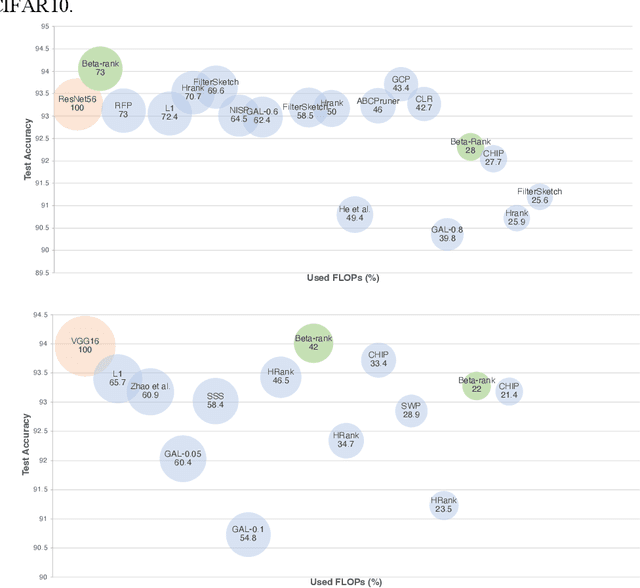
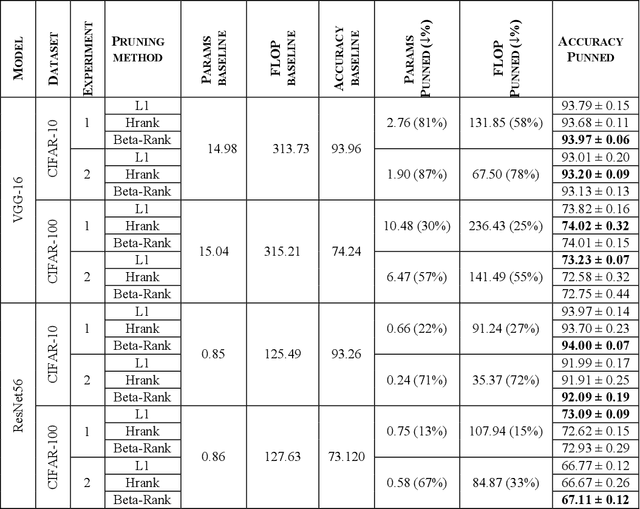
As deep neural networks include a high number of parameters and operations, it can be a challenge to implement these models on devices with limited computational resources. Despite the development of novel pruning methods toward resource-efficient models, it has become evident that these models are not capable of handling "imbalanced" and "limited number of data points". With input and output information, along with the values of the filters, a novel filter pruning method is proposed. Our pruning method considers the fact that all information about the importance of a filter may not be reflected in the value of the filter. Instead, it is reflected in the changes made to the data after the filter is applied to it. In this work, three methods are compared with the same training conditions except for the ranking of each method. We demonstrated that our model performed significantly better than other methods for medical datasets which are inherently imbalanced. When we removed up to 58% of FLOPs for the IDRID dataset and up to 45% for the ISIC dataset, our model was able to yield an equivalent (or even superior) result to the baseline model while other models were unable to achieve similar results. To evaluate FLOP and parameter reduction using our model in real-world settings, we built a smartphone app, where we demonstrated a reduction of up to 79% in memory usage and 72% in prediction time. All codes and parameters for training different models are available at https://github.com/mohofar/Beta-Rank