 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTPD: Cross-Modal Temporal Pattern Discovery for Enhanced Multimodal Electronic Health Records Analysis
Nov 01, 2024



Integrating multimodal Electronic Health Records (EHR) data, such as numerical time series and free-text clinical reports, has great potential in predicting clinical outcomes. However, prior work has primarily focused on capturing temporal interactions within individual samples and fusing multimodal information, overlooking critical temporal patterns across patients. These patterns, such as trends in vital signs like abnormal heart rate or blood pressure, can indicate deteriorating health or an impending critical event. Similarly, clinical notes often contain textual descriptions that reflect these patterns. Identifying corresponding temporal patterns across different modalities is crucial for improving the accuracy of clinical outcome predictions, yet it remains a challenging task. To address this gap, we introduce a Cross-Modal Temporal Pattern Discovery (CTPD) framework, designed to efficiently extract meaningful cross-modal temporal patterns from multimodal EHR data. Our approach introduces shared initial temporal pattern representations which are refined using slot attention to generate temporal semantic embeddings. To ensure rich cross-modal temporal semantics in the learned patterns, we introduce a contrastive-based TPNCE loss for cross-modal alignment, along with two reconstruction losses to retain core information of each modality. Evaluations on two clinically critical tasks, 48-hour in-hospital mortality and 24-hour phenotype classification, using the MIMIC-III database demonstrate the superiority of our method over existing approaches.
HERGen: Elevating Radiology Report Generation with Longitudinal Data
Jul 21, 2024



Radiology reports provide detailed descriptions of medical imaging integrated with patients' medical histories, while report writing is traditionally labor-intensive, increasing radiologists' workload and the risk of diagnostic errors. Recent efforts in automating this process seek to mitigate these issues by enhancing accuracy and clinical efficiency. Emerging research in automating this process promises to alleviate these challenges by reducing errors and streamlining clinical workflows. However, existing automated approaches are based on a single timestamp and often neglect the critical temporal aspect of patients' imaging histories, which is essential for accurate longitudinal analysis. To address this gap, we propose a novel History Enhanced Radiology Report Generation (HERGen) framework that employs a employs a group causal transformer to efficiently integrate longitudinal data across patient visits. Our approach not only allows for comprehensive analysis of varied historical data but also improves the quality of generated reports through an auxiliary contrastive objective that aligns image sequences with their corresponding reports. More importantly, we introduce a curriculum learning-based strategy to adeptly handle the inherent complexity of longitudinal radiology data and thus stabilize the optimization of our framework. The extensive evaluations across three datasets demonstrate that our framework surpasses existing methods in generating accurate radiology reports and effectively predicting disease progression from medical images.
Multi-Granularity Cross-modal Alignment for Generalized Medical Visual Representation Learning
Oct 12, 2022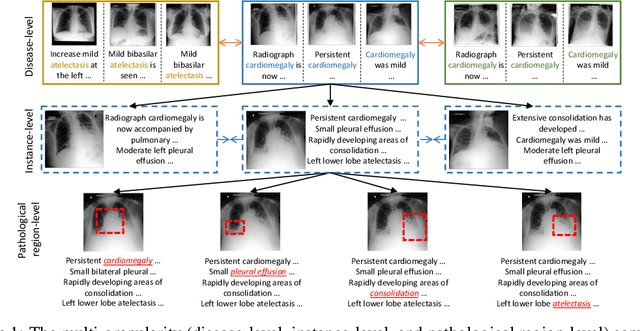
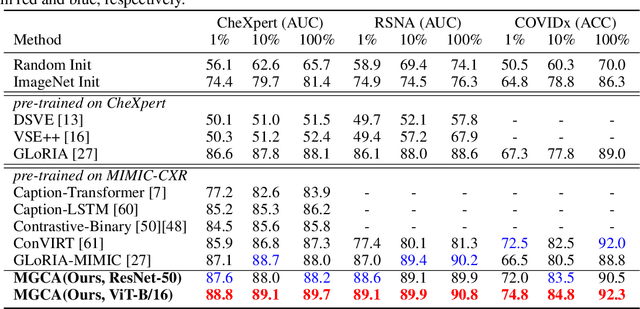

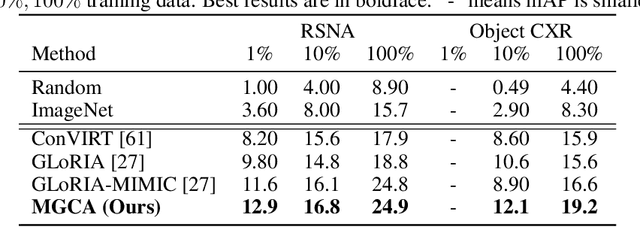
Learning medical visual representations directly from paired radiology reports has become an emerging topic in representation learning. However, existing medical image-text joint learning methods are limited by instance or local supervision analysis, ignoring disease-level semantic correspondences. In this paper, we present a novel Multi-Granularity Cross-modal Alignment (MGCA) framework for generalized medical visual representation learning by harnessing the naturally exhibited semantic correspondences between medical image and radiology reports at three different levels, i.e., pathological region-level, instance-level, and disease-level. Specifically, we first incorporate the instance-wise alignment module by maximizing the agreement between image-report pairs. Further, for token-wise alignment, we introduce a bidirectional cross-attention strategy to explicitly learn the matching between fine-grained visual tokens and text tokens, followed by contrastive learning to align them. More important, to leverage the high-level inter-subject relationship semantic (e.g., disease) correspondences, we design a novel cross-modal disease-level alignment paradigm to enforce the cross-modal cluster assignment consistency. Extensive experimental results on seven downstream medical image datasets covering image classification, object detection, and semantic segmentation tasks demonstrate the stable and superior performance of our framework.