 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMG-3D: Multi-Grained Knowledge-Enhanced 3D Medical Vision-Language Pre-training
Paper and Code
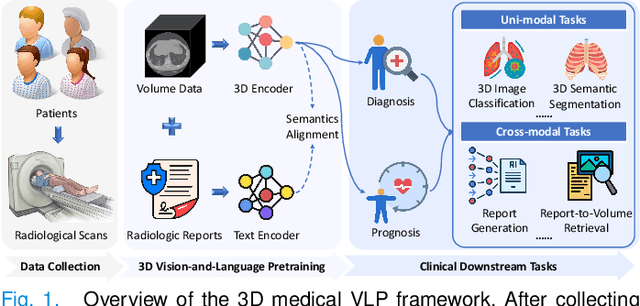

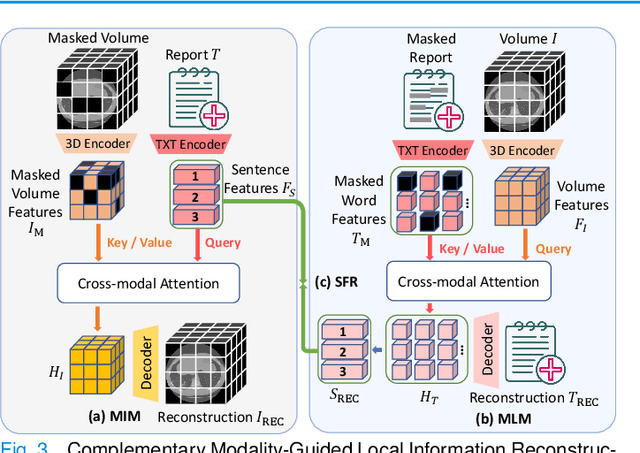

3D medical image analysis is pivotal in numerous clinical applications. However, the scarcity of labeled data and limited generalization capabilities hinder the advancement of AI-empowered models. Radiology reports are easily accessible and can serve as weakly-supervised signals. However, large-scale vision-language pre-training (VLP) remains underexplored in 3D medical image analysis. Specifically, the insufficient investigation into multi-grained radiology semantics and their correlations across patients leads to underutilization of large-scale volume-report data. Considering intra-patient cross-modal semantic consistency and inter-patient semantic correlations, we propose a multi-task VLP method, MG-3D, pre-trained on large-scale data (47.1K), addressing the challenges by the following two aspects: 1) Establishing the correspondence between volume semantics and multi-grained medical knowledge of each patient with cross-modal global alignment and complementary modality-guided local reconstruction, ensuring intra-patient features of different modalities cohesively represent the same semantic content; 2) Correlating inter-patient visual semantics based on fine-grained report correlations across patients, and keeping sensitivity to global individual differences via contrastive learning, enhancing the discriminative feature representation. Furthermore, we delve into the scaling law to explore potential performance improvements. Comprehensive evaluations across nine uni- and cross-modal clinical tasks are carried out to assess model efficacy. Extensive experiments on both internal and external datasets demonstrate the superior transferability, scalability, and generalization of MG-3D, showcasing its potential in advancing feature representation for 3D medical image analysis. Code will be available: https://github.com/Xuefeng-Ni/MG-3D.