 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject as Hotspots: An Anchor-Free 3D Object Detection Approach via Firing of Hotspots
Paper and Code
Dec 30, 2019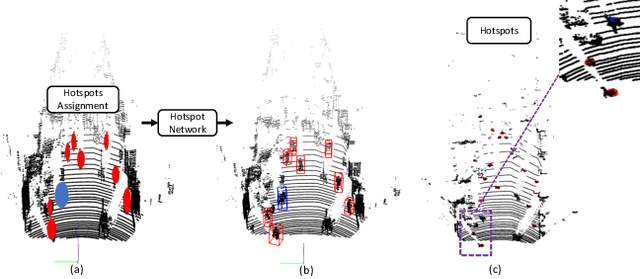



Accurate 3D object detection in LiDAR based point clouds suffers from the challenges of data sparsity and irregularities. Existing methods strive to organize the points regularly, e.g. voxelize, pass them through a designed 2D/3D neural network, and then define object-level anchors that predict offsets of 3D bounding boxes using collective evidence from all the points on the objects of interest. Converse to the state-of-the-art anchor-based methods, based on the very same nature of data sparsity and irregularities, we observe that even points on an isolated object part are informative about position and orientation of the object. We thus argue in this paper for an approach opposite to existing methods using object-level anchors. Technically, we propose to represent an object as a collection of point cliques; one can intuitively think of these point cliques as hotspots, giving rise to the representation of Object as Hotspots (OHS). Based on OHS, we propose a Hotspot Network (HotSpotNet) that performs 3D object detection via firing of hotspots without setting the predefined bounding boxes. A distinctive feature of HotSpotNet is that it makes predictions directly from individual hotspots, and final results are obtained by aggregating these hotspot predictions. Experiments on the KITTI benchmark show the efficacy of our proposed OHS representation. Our one-stage, anchor-free HotSpotNet beats all other one-stage detectors by at least 2% on cars , cyclists and pedestrian for all difficulty levels. Notably, our proposed method performs better on small and difficult objects and we rank the first among all the submitted methods on pedestrian of KITTI test set.