 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3D-SWIN:Use Shifted Window Attention for Single-View 3D Reconstruction
Dec 09, 2023



Recently, vision transformers have performed well in various computer vision tasks, including voxel 3D reconstruction. However, the windows of the vision transformer are not multi-scale, and there is no connection between the windows, which limits the accuracy of voxel 3D reconstruction. Therefore, we propose a voxel 3D reconstruction network based on shifted window attention. To the best of our knowledge, this is the first work to apply shifted window attention to voxel 3D reconstruction. Experimental results on ShapeNet verify our method achieves SOTA accuracy in single-view reconstruction.
High-resolution power equipment recognition based on improved self-attention
Nov 06, 2023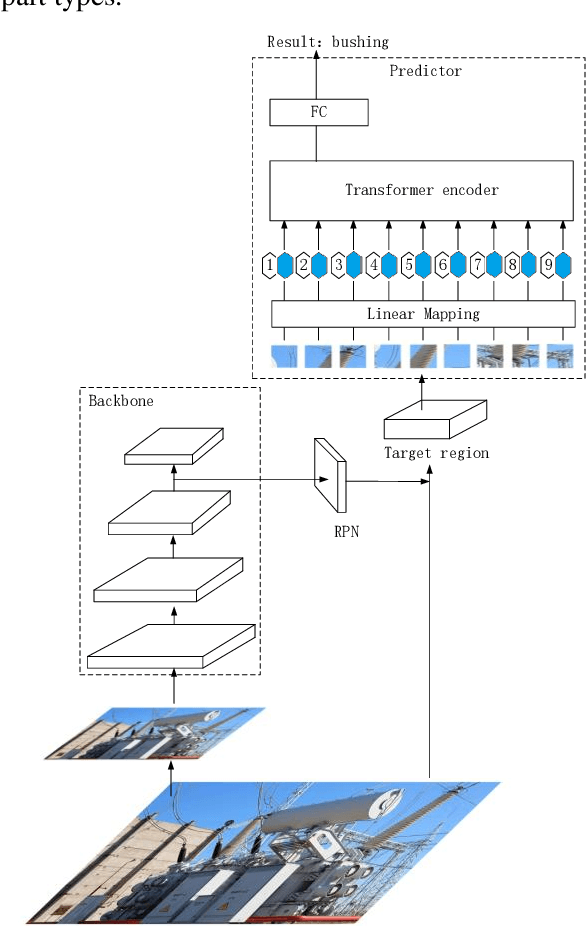
The current trend of automating inspections at substations has sparked a surge in interest in the field of transformer image recognition. However, due to restrictions in the number of parameters in existing models, high-resolution images can't be directly applied, leaving significant room for enhancing recognition accuracy. Addressing this challenge, the paper introduces a novel improvement on deep self-attention networks tailored for this issue. The proposed model comprises four key components: a foundational network, a region proposal network, a module for extracting and segmenting target areas, and a final prediction network. The innovative approach of this paper differentiates itself by decoupling the processes of part localization and recognition, initially using low-resolution images for localization followed by high-resolution images for recognition. Moreover, the deep self-attention network's prediction mechanism uniquely incorporates the semantic context of images, resulting in substantially improved recognition performance. Comparative experiments validate that this method outperforms the two other prevalent target recognition models, offering a groundbreaking perspective for automating electrical equipment inspections.