 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeSQL: Yet Another Large-scale Session-level Chinese Text-to-SQL Dataset
Aug 26, 2022
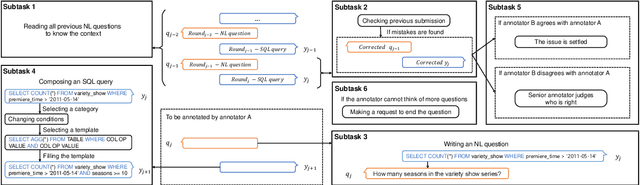
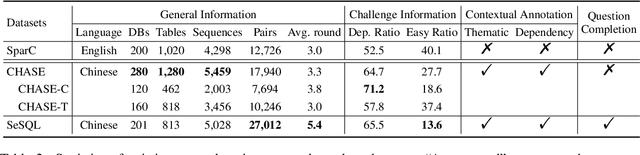
As the first session-level Chinese dataset, CHASE contains two separate parts, i.e., 2,003 sessions manually constructed from scratch (CHASE-C), and 3,456 sessions translated from English SParC (CHASE-T). We find the two parts are highly discrepant and incompatible as training and evaluation data. In this work, we present SeSQL, yet another large-scale session-level text-to-SQL dataset in Chinese, consisting of 5,028 sessions all manually constructed from scratch. In order to guarantee data quality, we adopt an iterative annotation workflow to facilitate intense and in-time review of previous-round natural language (NL) questions and SQL queries. Moreover, by completing all context-dependent NL questions, we obtain 27,012 context-independent question/SQL pairs, allowing SeSQL to be used as the largest dataset for single-round multi-DB text-to-SQL parsing. We conduct benchmark session-level text-to-SQL parsing experiments on SeSQL by employing three competitive session-level parsers, and present detailed analysis.
An In-depth Study on Internal Structure of Chinese Words
Jun 01, 2021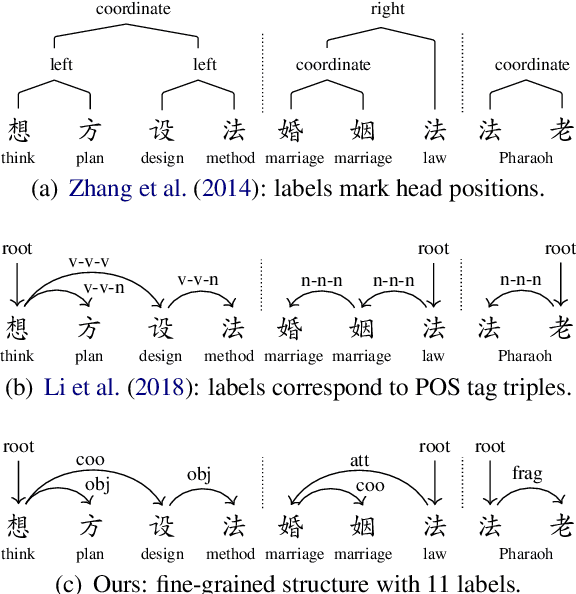
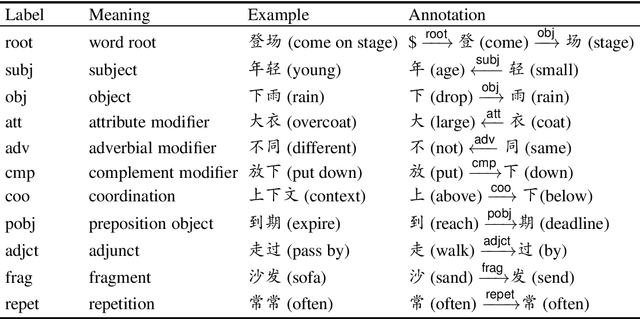
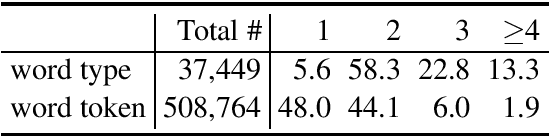
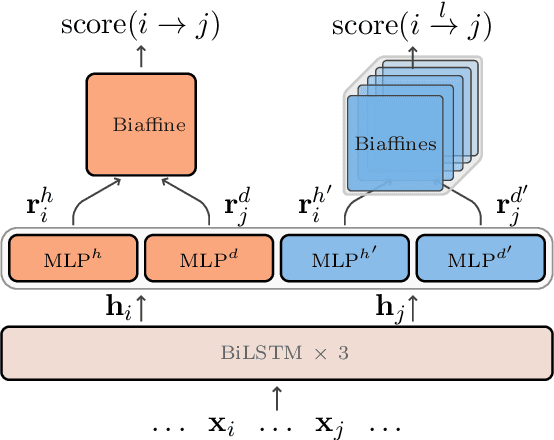
Unlike English letters, Chinese characters have rich and specific meanings. Usually, the meaning of a word can be derived from its constituent characters in some way. Several previous works on syntactic parsing propose to annotate shallow word-internal structures for better utilizing character-level information. This work proposes to model the deep internal structures of Chinese words as dependency trees with 11 labels for distinguishing syntactic relationships. First, based on newly compiled annotation guidelines, we manually annotate a word-internal structure treebank (WIST) consisting of over 30K multi-char words from Chinese Penn Treebank. To guarantee quality, each word is independently annotated by two annotators and inconsistencies are handled by a third senior annotator. Second, we present detailed and interesting analysis on WIST to reveal insights on Chinese word formation. Third, we propose word-internal structure parsing as a new task, and conduct benchmark experiments using a competitive dependency parser. Finally, we present two simple ways to encode word-internal structures, leading to promising gains on the sentence-level syntactic parsing task.