 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOINTS-Long: Adaptive Dual-Mode Visual Reasoning in MLLMs
Apr 13, 2026Multimodal Large Language Models (MLLMs) have recently demonstrated remarkable capabilities in cross-modal understanding and generation. However, the rapid growth of visual token sequences--especially in long-video and streaming scenarios--poses a major challenge to their scalability and real-world deployment. Thus, we introduce POINTS-Long, a native dual-mode MLLM featuring dynamic visual token scaling inspired by the human visual system. The model supports two complementary perception modes: focus mode and standby mode, enabling users to dynamically trade off efficiency and accuracy during inference. On fine-grained visual tasks, the focus mode retains the optimal performance, while on long-form general visual understanding, the standby mode retains 97.7-99.7% of the original accuracy using only 1/40-1/10th of the visual tokens. Moreover, POINTS-Long natively supports streaming visual understanding via a dynamically detachable KV-cache design, allowing efficient maintenance of ultra-long visual memory. Our work provides new insights into the design of future MLLMs and lays the foundation for adaptive and efficient long-form visual understanding.
POINTS-GUI-G: GUI-Grounding Journey
Feb 06, 2026The rapid advancement of vision-language models has catalyzed the emergence of GUI agents, which hold immense potential for automating complex tasks, from online shopping to flight booking, thereby alleviating the burden of repetitive digital workflows. As a foundational capability, GUI grounding is typically established as a prerequisite for end-to-end task execution. It enables models to precisely locate interface elements, such as text and icons, to perform accurate operations like clicking and typing. Unlike prior works that fine-tune models already possessing strong spatial awareness (e.g., Qwen3-VL), we aim to master the full technical pipeline by starting from a base model with minimal grounding ability, such as POINTS-1.5. We introduce POINTS-GUI-G-8B, which achieves state-of-the-art performance with scores of 59.9 on ScreenSpot-Pro, 66.0 on OSWorld-G, 95.7 on ScreenSpot-v2, and 49.9 on UI-Vision. Our model's success is driven by three key factors: (1) Refined Data Engineering, involving the unification of diverse open-source datasets format alongside sophisticated strategies for augmentation, filtering, and difficulty grading; (2) Improved Training Strategies, including continuous fine-tuning of the vision encoder to enhance perceptual accuracy and maintaining resolution consistency between training and inference; and (3) Reinforcement Learning (RL) with Verifiable Rewards. While RL is traditionally used to bolster reasoning, we demonstrate that it significantly improves precision in the perception-intensive GUI grounding task. Furthermore, GUI grounding provides a natural advantage for RL, as rewards are easily verifiable and highly accurate.
Mitigating Communication Costs in Neural Networks: The Role of Dendritic Nonlinearity
Jun 21, 2023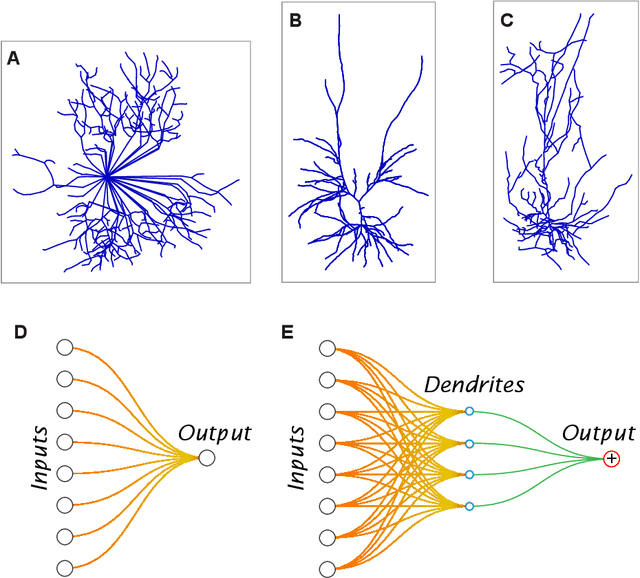
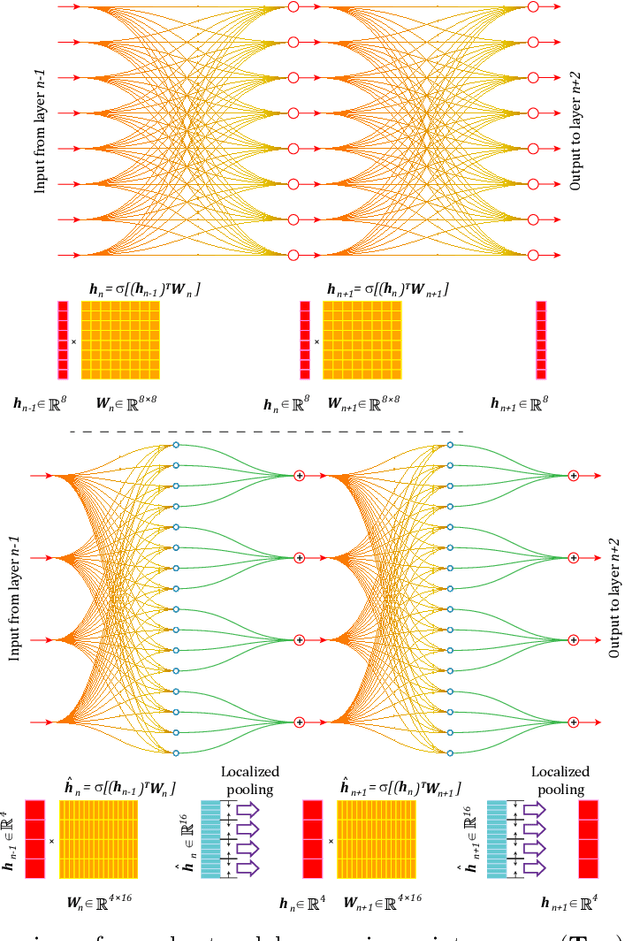
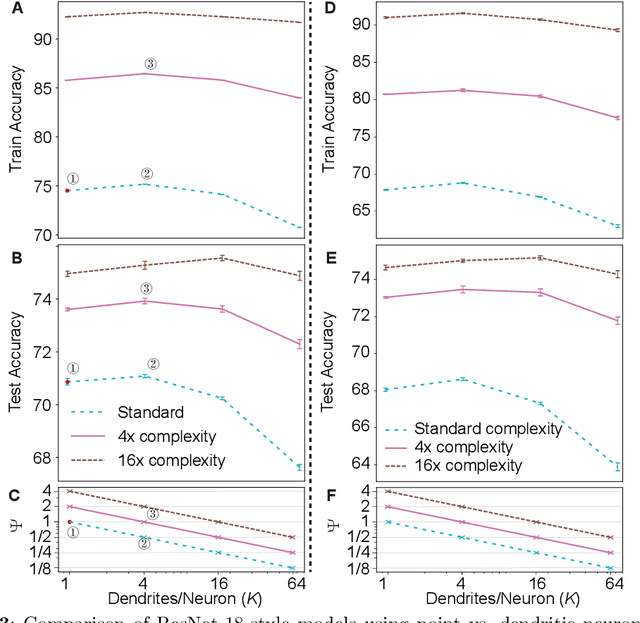
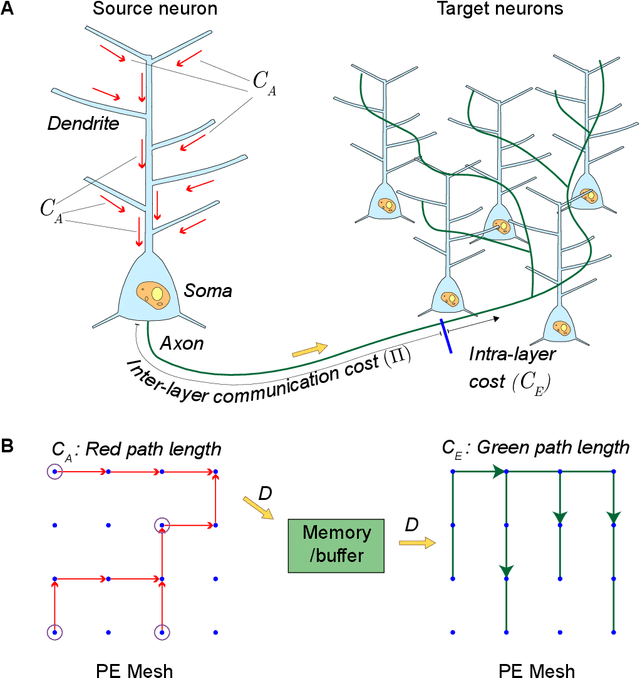
Our comprehension of biological neuronal networks has profoundly influenced the evolution of artificial neural networks (ANNs). However, the neurons employed in ANNs exhibit remarkable deviations from their biological analogs, mainly due to the absence of complex dendritic trees encompassing local nonlinearity. Despite such disparities, previous investigations have demonstrated that point neurons can functionally substitute dendritic neurons in executing computational tasks. In this study, we scrutinized the importance of nonlinear dendrites within neural networks. By employing machine-learning methodologies, we assessed the impact of dendritic structure nonlinearity on neural network performance. Our findings reveal that integrating dendritic structures can substantially enhance model capacity and performance while keeping signal communication costs effectively restrained. This investigation offers pivotal insights that hold considerable implications for the development of future neural network accelerators.
PP-OCR: A Practical Ultra Lightweight OCR System
Oct 15, 2020

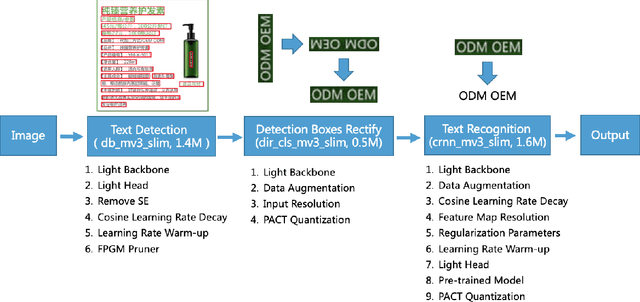
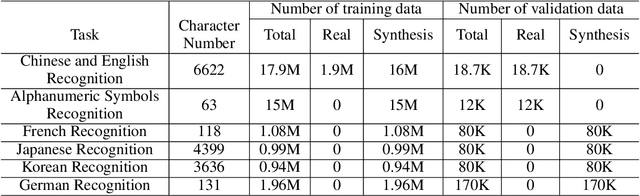
The Optical Character Recognition (OCR) systems have been widely used in various of application scenarios, such as office automation (OA) systems, factory automations, online educations, map productions etc. However, OCR is still a challenging task due to the various of text appearances and the demand of computational efficiency. In this paper, we propose a practical ultra lightweight OCR system, i.e., PP-OCR. The overall model size of the PP-OCR is only 3.5M for recognizing 6622 Chinese characters and 2.8M for recognizing 63 alphanumeric symbols, respectively. We introduce a bag of strategies to either enhance the model ability or reduce the model size. The corresponding ablation experiments with the real data are also provided. Meanwhile, several pre-trained models for the Chinese and English recognition are released, including a text detector (97K images are used), a direction classifier (600K images are used) as well as a text recognizer (17.9M images are used). Besides, the proposed PP-OCR are also verified in several other language recognition tasks, including French, Korean, Japanese and German. All of the above mentioned models are open-sourced and the codes are available in the GitHub repository, i.e., https://github.com/PaddlePaddle/PaddleOCR.