 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Optimization of Source Weights and Transfer Quantities in Multi-Source Transfer Learning: An Asymptotic Framework
Jan 15, 2026Transfer learning plays a vital role in improving model performance in data-scarce scenarios. However, naive uniform transfer from multiple source tasks may result in negative transfer, highlighting the need to properly balance the contributions of heterogeneous sources. Moreover, existing transfer learning methods typically focus on optimizing either the source weights or the amount of transferred samples, while largely neglecting the joint consideration of the other. In this work, we propose a theoretical framework, Unified Optimization of Weights and Quantities (UOWQ), which formulates multi-source transfer learning as a parameter estimation problem grounded in an asymptotic analysis of a Kullback-Leibler divergence-based generalization error measure. The proposed framework jointly determines the optimal source weights and optimal transfer quantities for each source task. Firstly, we prove that using all available source samples is always optimal once the weights are properly adjusted, and we provide a theoretical explanation for this phenomenon. Moreover, to determine the optimal transfer weights, our analysis yields closed-form solutions in the single-source setting and develops a convex optimization-based numerical procedure for the multi-source case. Building on the theoretical results, we further propose practical algorithms for both multi-source transfer learning and multi-task learning settings. Extensive experiments on real-world benchmarks, including DomainNet and Office-Home, demonstrate that UOWQ consistently outperforms strong baselines. The results validate both the theoretical predictions and the practical effectiveness of our framework.
A Theoretical Framework for Data Efficient Multi-Source Transfer Learning Based on Cramér-Rao Bound
Feb 06, 2025



Multi-source transfer learning provides an effective solution to data scarcity in real-world supervised learning scenarios by leveraging multiple source tasks. In this field, existing works typically use all available samples from sources in training, which constrains their training efficiency and may lead to suboptimal results. To address this, we propose a theoretical framework that answers the question: what is the optimal quantity of source samples needed from each source task to jointly train the target model? Specifically, we introduce a generalization error measure that aligns with cross-entropy loss, and minimize it based on the Cram\'er-Rao Bound to determine the optimal transfer quantity for each source task. Additionally, we develop an architecture-agnostic and data-efficient algorithm OTQMS to implement our theoretical results for training deep multi-source transfer learning models. Experimental studies on diverse architectures and two real-world benchmark datasets show that our proposed algorithm significantly outperforms state-of-the-art approaches in both accuracy and data efficiency. The code and supplementary materials are available in https://anonymous.4open.science/r/Materials.
GADY: Unsupervised Anomaly Detection on Dynamic Graphs
Oct 25, 2023Anomaly detection on dynamic graphs refers to detecting entities whose behaviors obviously deviate from the norms observed within graphs and their temporal information. This field has drawn increasing attention due to its application in finance, network security, social networks, and more. However, existing methods face two challenges: dynamic structure constructing challenge - difficulties in capturing graph structure with complex time information and negative sampling challenge - unable to construct excellent negative samples for unsupervised learning. To address these challenges, we propose Unsupervised Generative Anomaly Detection on Dynamic Graphs (GADY). To tackle the first challenge, we propose a continuous dynamic graph model to capture the fine-grained information, which breaks the limit of existing discrete methods. Specifically, we employ a message-passing framework combined with positional features to get edge embeddings, which are decoded to identify anomalies. For the second challenge, we pioneer the use of Generative Adversarial Networks to generate negative interactions. Moreover, we design a loss function to alter the training goal of the generator while ensuring the diversity and quality of generated samples. Extensive experiments demonstrate that our proposed GADY significantly outperforms the previous state-of-the-art method on three real-world datasets. Supplementary experiments further validate the effectiveness of our model design and the necessity of each module.
KRACL: Contrastive Learning with Graph Context Modeling for Sparse Knowledge Graph Completion
Aug 16, 2022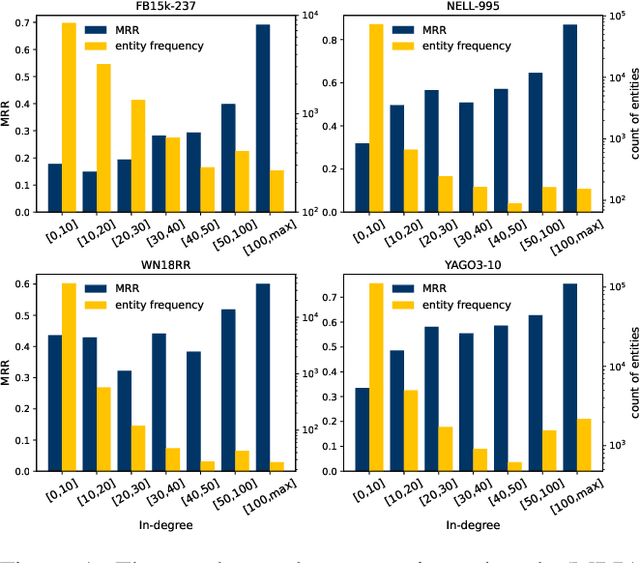

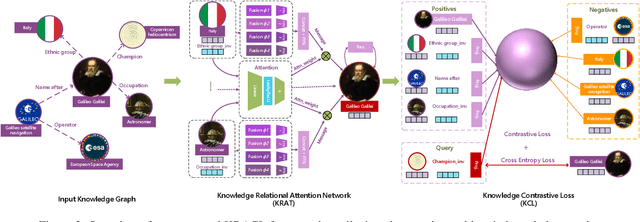

Knowledge Graph Embeddings (KGE) aim to map entities and relations to low dimensional spaces and have become the \textit{de-facto} standard for knowledge graph completion. Most existing KGE methods suffer from the sparsity challenge, where it is harder to predict entities that appear less frequently in knowledge graphs. In this work, we propose a novel framework KRACL to alleviate the widespread sparsity in KGs with graph context and contrastive learning. Firstly, we propose the Knowledge Relational Attention Network (KRAT) to leverage the graph context by simultaneously projecting neighboring triples to different latent spaces and jointly aggregating messages with the attention mechanism. KRAT is capable of capturing the subtle semantic information and importance of different context triples as well as leveraging multi-hop information in knowledge graphs. Secondly, we propose the knowledge contrastive loss by combining the contrastive loss with cross entropy loss, which introduces more negative samples and thus enriches the feedback to sparse entities. Our experiments demonstrate that KRACL achieves superior results across various standard knowledge graph benchmarks, especially on WN18RR and NELL-995 which have large numbers of low in-degree entities. Extensive experiments also bear out KRACL's effectiveness in handling sparse knowledge graphs and robustness against noisy triples.
TwiBot-22: Towards Graph-Based Twitter Bot Detection
Jun 12, 2022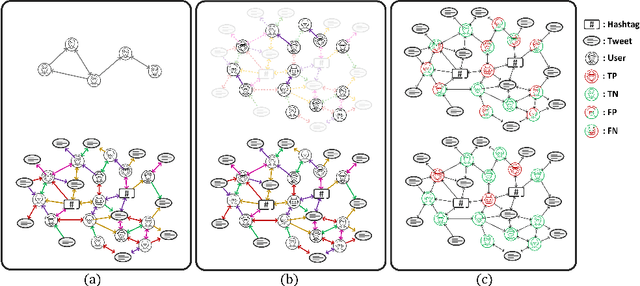
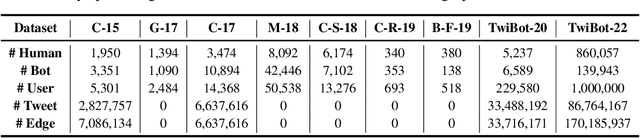
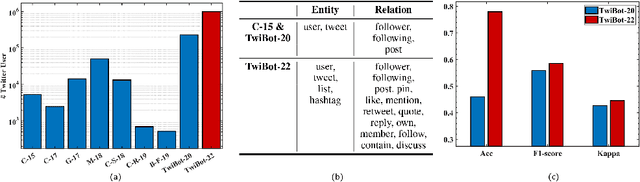
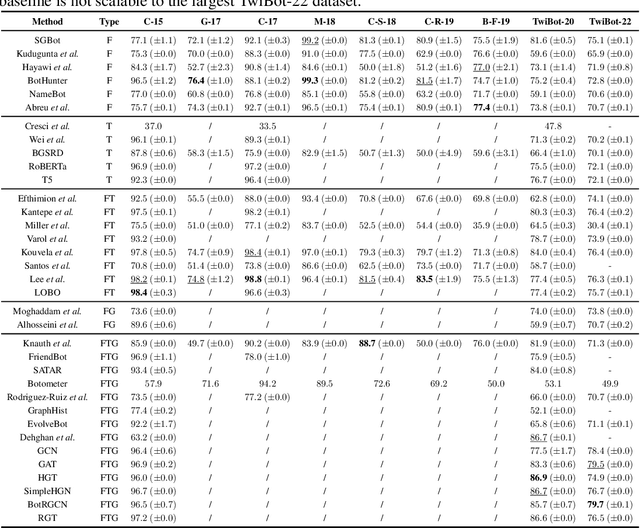
Twitter bot detection has become an increasingly important task to combat misinformation, facilitate social media moderation, and preserve the integrity of the online discourse. State-of-the-art bot detection methods generally leverage the graph structure of the Twitter network, and they exhibit promising performance when confronting novel Twitter bots that traditional methods fail to detect. However, very few of the existing Twitter bot detection datasets are graph-based, and even these few graph-based datasets suffer from limited dataset scale, incomplete graph structure, as well as low annotation quality. In fact, the lack of a large-scale graph-based Twitter bot detection benchmark that addresses these issues has seriously hindered the development and evaluation of novel graph-based bot detection approaches. In this paper, we propose TwiBot-22, a comprehensive graph-based Twitter bot detection benchmark that presents the largest dataset to date, provides diversified entities and relations on the Twitter network, and has considerably better annotation quality than existing datasets. In addition, we re-implement 35 representative Twitter bot detection baselines and evaluate them on 9 datasets, including TwiBot-22, to promote a fair comparison of model performance and a holistic understanding of research progress. To facilitate further research, we consolidate all implemented codes and datasets into the TwiBot-22 evaluation framework, where researchers could consistently evaluate new models and datasets. The TwiBot-22 Twitter bot detection benchmark and evaluation framework are publicly available at https://twibot22.github.io/