 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMKG-RDS: Reasoning Data Synthesis via Deep Mining of Multimodal Knowledge Graphs
Feb 27, 2026Synthesizing high-quality training data is crucial for enhancing domain models' reasoning abilities. Existing methods face limitations in long-tail knowledge coverage, effectiveness verification, and interpretability. Knowledge-graph-based approaches still fall short in functionality, granularity, customizability, and evaluation. To address these issues, we propose MMKG-RDS, a flexible framework for reasoning data synthesis that leverages multimodal knowledge graphs. It supports fine-grained knowledge extraction, customizable path sampling, and multidimensional data quality scoring. We validate MMKG-RDS with the MMKG-RDS-Bench dataset, covering five domains, 17 task types, and 14,950 samples. Experimental results show fine-tuning Qwen3 models (0.6B/8B/32B) on a small number of synthesized samples improves reasoning accuracy by 9.2%. The framework also generates distinct data, challenging existing models on tasks involving tables and formulas, useful for complex benchmark construction. The dataset and code are available at https://github.com/360AILAB-NLP/MMKG-RDS
Enhancing Complex Formula Recognition with Hierarchical Detail-Focused Network
Sep 18, 2024



Hierarchical and complex Mathematical Expression Recognition (MER) is challenging due to multiple possible interpretations of a formula, complicating both parsing and evaluation. In this paper, we introduce the Hierarchical Detail-Focused Recognition dataset (HDR), the first dataset specifically designed to address these issues. It consists of a large-scale training set, HDR-100M, offering an unprecedented scale and diversity with one hundred million training instances. And the test set, HDR-Test, includes multiple interpretations of complex hierarchical formulas for comprehensive model performance evaluation. Additionally, the parsing of complex formulas often suffers from errors in fine-grained details. To address this, we propose the Hierarchical Detail-Focused Recognition Network (HDNet), an innovative framework that incorporates a hierarchical sub-formula module, focusing on the precise handling of formula details, thereby significantly enhancing MER performance. Experimental results demonstrate that HDNet outperforms existing MER models across various datasets.
First Multi-Dimensional Evaluation of Flowchart Comprehension for Multimodal Large Language Models
Jun 18, 2024



With the development of Multimodal Large Language Models (MLLMs) technology, its general capabilities are increasingly powerful. To evaluate the various abilities of MLLMs, numerous evaluation systems have emerged. But now there is still a lack of a comprehensive method to evaluate MLLMs in the tasks related to flowcharts, which are very important in daily life and work. We propose the first comprehensive method, FlowCE, to assess MLLMs across various dimensions for tasks related to flowcharts. It encompasses evaluating MLLMs' abilities in Reasoning, Localization Recognition, Information Extraction, Logical Verification, and Summarization on flowcharts. However, we find that even the GPT4o model achieves only a score of 56.63. Among open-source models, Phi-3-Vision obtained the highest score of 49.97. We hope that FlowCE can contribute to future research on MLLMs for tasks based on flowcharts. \url{https://github.com/360AILAB-NLP/FlowCE} \end{abstract}
CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models
Jan 30, 2024



Retrieval-Augmented Generation (RAG) is a technique that enhances the capabilities of large language models (LLMs) by incorporating external knowledge sources. This method addresses common LLM limitations, including outdated information and the tendency to produce inaccurate "hallucinated" content. However, the evaluation of RAG systems is challenging, as existing benchmarks are limited in scope and diversity. Most of the current benchmarks predominantly assess question-answering applications, overlooking the broader spectrum of situations where RAG could prove advantageous. Moreover, they only evaluate the performance of the LLM component of the RAG pipeline in the experiments, and neglect the influence of the retrieval component and the external knowledge database. To address these issues, this paper constructs a large-scale and more comprehensive benchmark, and evaluates all the components of RAG systems in various RAG application scenarios. Specifically, we have categorized the range of RAG applications into four distinct types-Create, Read, Update, and Delete (CRUD), each representing a unique use case. "Create" refers to scenarios requiring the generation of original, varied content. "Read" involves responding to intricate questions in knowledge-intensive situations. "Update" focuses on revising and rectifying inaccuracies or inconsistencies in pre-existing texts. "Delete" pertains to the task of summarizing extensive texts into more concise forms. For each of these CRUD categories, we have developed comprehensive datasets to evaluate the performance of RAG systems. We also analyze the effects of various components of the RAG system, such as the retriever, the context length, the knowledge base construction, and the LLM. Finally, we provide useful insights for optimizing the RAG technology for different scenarios.
TripleRE: Knowledge Graph Embeddings via Tripled Relation Vectors
Sep 17, 2022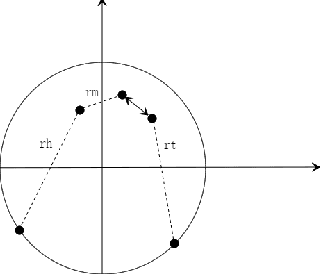
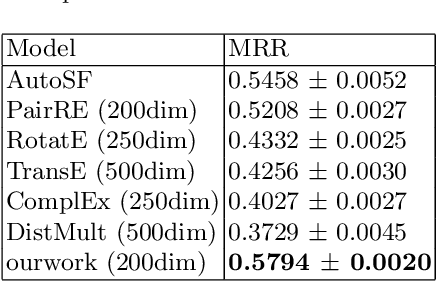

Translation-based knowledge graph embedding has been one of the most important branches for knowledge representation learning since TransE came out. Although many translation-based approaches have achieved some progress in recent years, the performance was still unsatisfactory. This paper proposes a novel knowledge graph embedding method named TripleRE with two versions. The first version of TripleRE creatively divide the relationship vector into three parts. The second version takes advantage of the concept of residual and achieves better performance. In addition, attempts on using NodePiece to encode entities achieved promising results in reducing the parametric size, and solved the problems of scalability. Experiments show that our approach achieved state-of-the-art performance on the large-scale knowledge graph dataset, and competitive performance on other datasets.