 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripleRE: Knowledge Graph Embeddings via Tripled Relation Vectors
Sep 17, 2022
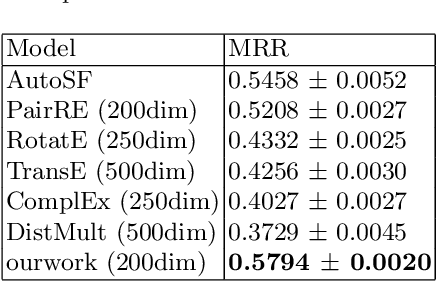

Translation-based knowledge graph embedding has been one of the most important branches for knowledge representation learning since TransE came out. Although many translation-based approaches have achieved some progress in recent years, the performance was still unsatisfactory. This paper proposes a novel knowledge graph embedding method named TripleRE with two versions. The first version of TripleRE creatively divide the relationship vector into three parts. The second version takes advantage of the concept of residual and achieves better performance. In addition, attempts on using NodePiece to encode entities achieved promising results in reducing the parametric size, and solved the problems of scalability. Experiments show that our approach achieved state-of-the-art performance on the large-scale knowledge graph dataset, and competitive performance on other datasets.
StarGraph: A Coarse-to-Fine Representation Method for Large-Scale Knowledge Graph
May 27, 2022
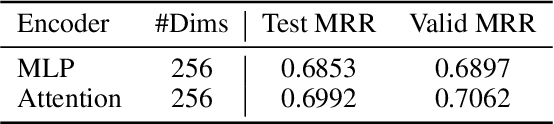
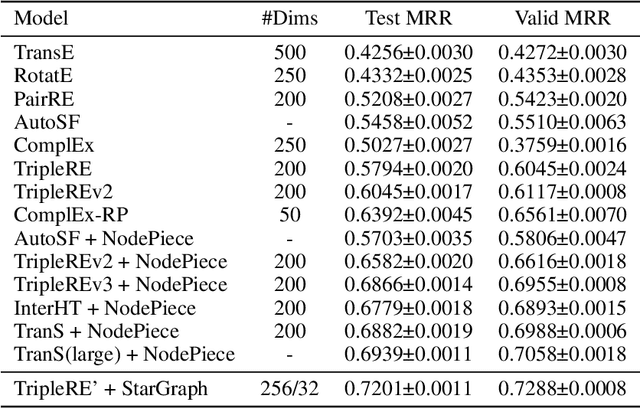
Conventional representation learning algorithms for knowledge graphs (KG) map each entity to a unique embedding vector, ignoring the rich information contained in neighbor entities. We propose a method named StarGraph, which gives a novel way to utilize the neighborhood information for large-scale knowledge graphs to get better entity representations. The core idea is to divide the neighborhood information into different levels for sampling and processing, where the generalized coarse-grained information and unique fine-grained information are combined to generate an efficient subgraph for each node. In addition, a self-attention network is proposed to process the subgraphs and get the entity representations, which are used to replace the entity embeddings in conventional methods. The proposed method achieves the best results on the ogbl-wikikg2 dataset, which validates the effectiveness of it. The code is now available at https://github.com/hzli-ucas/StarGraph
Reinterpreting CTC training as iterative fitting
Apr 24, 2019



The connectionist temporal classification (CTC) enables end-to-end sequence learning by maximizing the probability of correctly recognizing sequences during training. With an extra $blank$ class, the CTC implicitly converts recognizing a sequence into classifying each timestep within the sequence. But the CTC loss is not intuitive for such classification task, so the class imbalance within each sequence, caused by the overwhelming $blank$ timesteps, is a knotty problem. In this paper, we define a piece-wise function as the pseudo ground-truth to reinterpret the CTC loss based on sequences as the cross entropy loss based on timesteps. The cross entropy form makes it easy to re-weight the CTC loss. Experiments on text recognition show that the weighted CTC loss solves the class imbalance problem as well as facilitates the convergence, generally leading to better results than the CTC loss. Beside this, the reinterpretation of CTC, as a brand new perspective, may be potentially useful in some other situations.