 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparate and Locate: Rethink the Text in Text-based Visual Question Answering
Aug 31, 2023


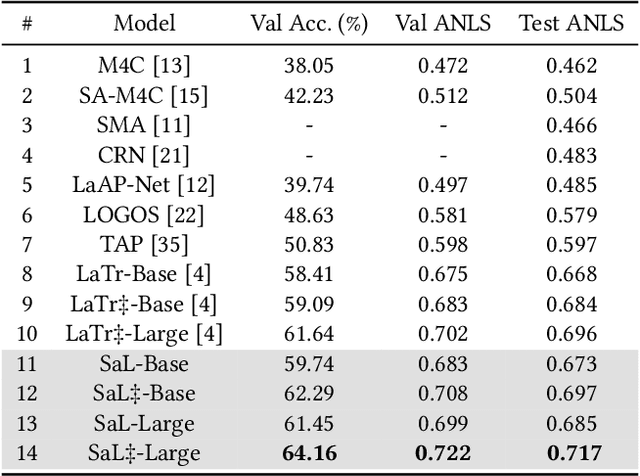
Text-based Visual Question Answering (TextVQA) aims at answering questions about the text in images. Most works in this field focus on designing network structures or pre-training tasks. All these methods list the OCR texts in reading order (from left to right and top to bottom) to form a sequence, which is treated as a natural language ``sentence''. However, they ignore the fact that most OCR words in the TextVQA task do not have a semantical contextual relationship. In addition, these approaches use 1-D position embedding to construct the spatial relation between OCR tokens sequentially, which is not reasonable. The 1-D position embedding can only represent the left-right sequence relationship between words in a sentence, but not the complex spatial position relationship. To tackle these problems, we propose a novel method named Separate and Locate (SaL) that explores text contextual cues and designs spatial position embedding to construct spatial relations between OCR texts. Specifically, we propose a Text Semantic Separate (TSS) module that helps the model recognize whether words have semantic contextual relations. Then, we introduce a Spatial Circle Position (SCP) module that helps the model better construct and reason the spatial position relationships between OCR texts. Our SaL model outperforms the baseline model by 4.44% and 3.96% accuracy on TextVQA and ST-VQA datasets. Compared with the pre-training state-of-the-art method pre-trained on 64 million pre-training samples, our method, without any pre-training tasks, still achieves 2.68% and 2.52% accuracy improvement on TextVQA and ST-VQA. Our code and models will be released at https://github.com/fangbufang/SaL.
Towards Escaping from Language Bias and OCR Error: Semantics-Centered Text Visual Question Answering
Mar 24, 2022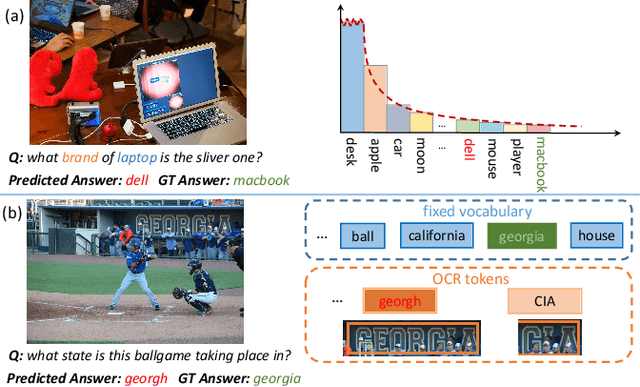

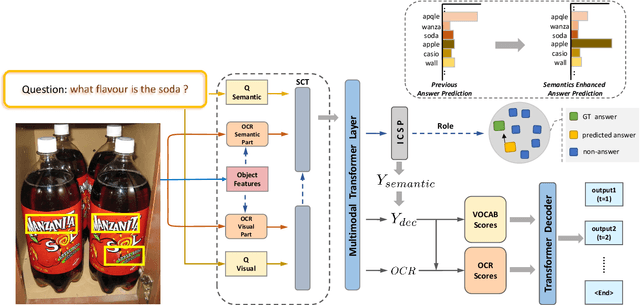

Texts in scene images convey critical information for scene understanding and reasoning. The abilities of reading and reasoning matter for the model in the text-based visual question answering (TextVQA) process. However, current TextVQA models do not center on the text and suffer from several limitations. The model is easily dominated by language biases and optical character recognition (OCR) errors due to the absence of semantic guidance in the answer prediction process. In this paper, we propose a novel Semantics-Centered Network (SC-Net) that consists of an instance-level contrastive semantic prediction module (ICSP) and a semantics-centered transformer module (SCT). Equipped with the two modules, the semantics-centered model can resist the language biases and the accumulated errors from OCR. Extensive experiments on TextVQA and ST-VQA datasets show the effectiveness of our model. SC-Net surpasses previous works with a noticeable margin and is more reasonable for the TextVQA task.
Learning Better Representation for Tables by Self-Supervised Tasks
Oct 15, 2020



Table-to-text generation aims at automatically generating natural text to help people to conveniently obtain the important information in tables. Although neural models for table-to-text have achieved remarkable progress, some problems still overlooked. The first is that the values recorded in many tables are mostly numbers in practice. The existing approaches do not do special treatment for these, and still regard these as words in natural language text. Secondly, the target texts in training dataset may contain redundant information or facts do not exist in the input tables. These may give wrong supervision signals to some methods based on content selection and planning and auxiliary supervision. To solve these problems, we propose two self-supervised tasks, Number Ordering and Significance Ordering, to help to learn better table representation. The former works on the column dimension to help to incorporate the size property of numbers into table representation. The latter acts on row dimension and help to learn a significance-aware table representation. We test our methods on the widely used dataset ROTOWIRE which consists of NBA game statistic and related news. The experimental results demonstrate that the model trained together with these two self-supervised tasks can generate text that contains more salient and well-organized facts, even without modeling context selection and planning. And we achieve the state-of-the-art performance on automatic metrics.