 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho: Towards Advanced Audio Comprehension via Audio-Interleaved Reasoning
Feb 12, 2026The maturation of Large Audio Language Models (LALMs) has raised growing expectations for them to comprehend complex audio much like humans. Current efforts primarily replicate text-based reasoning by contextualizing audio content through a one-time encoding, which introduces a critical information bottleneck. Drawing inspiration from human cognition, we propose audio-interleaved reasoning to break through this bottleneck. It treats audio as an active reasoning component, enabling sustained audio engagement and perception-grounded analysis. To instantiate it, we introduce a two-stage training framework, first teaching LALMs to localize salient audio segments through supervised fine-tuning, and then incentivizing proficient re-listening via reinforcement learning. In parallel, a structured data generation pipeline is developed to produce high-quality training data. Consequently, we present Echo, a LALM capable of dynamically re-listening to audio in demand during reasoning. On audio comprehension benchmarks, Echo achieves overall superiority in both challenging expert-level and general-purpose tasks. Comprehensive analysis further confirms the efficiency and generalizability of audio-interleaved reasoning, establishing it as a promising direction for advancing audio comprehension. Project page: https://github.com/wdqqdw/Echo.
EmoCaliber: Advancing Reliable Visual Emotion Comprehension via Confidence Verbalization and Calibration
Dec 17, 2025Visual Emotion Comprehension (VEC) aims to infer sentiment polarities or emotion categories from affective cues embedded in images. In recent years, Multimodal Large Language Models (MLLMs) have established a popular paradigm in VEC, leveraging their generalizability to unify VEC tasks defined under diverse emotion taxonomies. While this paradigm achieves notable success, it typically formulates VEC as a deterministic task, requiring the model to output a single, definitive emotion label for each image. Such a formulation insufficiently accounts for the inherent subjectivity of emotion perception, overlooking alternative interpretations that may be equally plausible to different viewers. To address this limitation, we propose equipping MLLMs with capabilities to verbalize their confidence in emotion predictions. This additional signal provides users with an estimate of both the plausibility of alternative interpretations and the MLLMs' self-assessed competence, thereby enhancing reliability in practice. Building on this insight, we introduce a three-stage training framework that progressively endows with structured reasoning, teaches to verbalize confidence, and calibrates confidence expression, culminating in EmoCaliber, a confidence-aware MLLM for VEC. Through fair and comprehensive evaluations on the unified benchmark VECBench, EmoCaliber demonstrates overall superiority against existing methods in both emotion prediction and confidence estimation. These results validate the effectiveness of our approach and mark a feasible step toward more reliable VEC systems. Project page: https://github.com/wdqqdw/EmoCaliber.
Customizing Visual Emotion Evaluation for MLLMs: An Open-vocabulary, Multifaceted, and Scalable Approach
Sep 26, 2025Recently, Multimodal Large Language Models (MLLMs) have achieved exceptional performance across diverse tasks, continually surpassing previous expectations regarding their capabilities. Nevertheless, their proficiency in perceiving emotions from images remains debated, with studies yielding divergent results in zero-shot scenarios. We argue that this inconsistency stems partly from constraints in existing evaluation methods, including the oversight of plausible responses, limited emotional taxonomies, neglect of contextual factors, and labor-intensive annotations. To facilitate customized visual emotion evaluation for MLLMs, we propose an Emotion Statement Judgment task that overcomes these constraints. Complementing this task, we devise an automated pipeline that efficiently constructs emotion-centric statements with minimal human effort. Through systematically evaluating prevailing MLLMs, our study showcases their stronger performance in emotion interpretation and context-based emotion judgment, while revealing relative limitations in comprehending perception subjectivity. When compared to humans, even top-performing MLLMs like GPT4o demonstrate remarkable performance gaps, underscoring key areas for future improvement. By developing a fundamental evaluation framework and conducting a comprehensive MLLM assessment, we hope this work contributes to advancing emotional intelligence in MLLMs. Project page: https://github.com/wdqqdw/MVEI.
Gather and Trace: Rethinking Video TextVQA from an Instance-oriented Perspective
Aug 06, 2025Video text-based visual question answering (Video TextVQA) aims to answer questions by explicitly reading and reasoning about the text involved in a video. Most works in this field follow a frame-level framework which suffers from redundant text entities and implicit relation modeling, resulting in limitations in both accuracy and efficiency. In this paper, we rethink the Video TextVQA task from an instance-oriented perspective and propose a novel model termed GAT (Gather and Trace). First, to obtain accurate reading result for each video text instance, a context-aggregated instance gathering module is designed to integrate the visual appearance, layout characteristics, and textual contents of the related entities into a unified textual representation. Then, to capture dynamic evolution of text in the video flow, an instance-focused trajectory tracing module is utilized to establish spatio-temporal relationships between instances and infer the final answer. Extensive experiments on several public Video TextVQA datasets validate the effectiveness and generalization of our framework. GAT outperforms existing Video TextVQA methods, video-language pretraining methods, and video large language models in both accuracy and inference speed. Notably, GAT surpasses the previous state-of-the-art Video TextVQA methods by 3.86\% in accuracy and achieves ten times of faster inference speed than video large language models. The source code is available at https://github.com/zhangyan-ucas/GAT.
An Empirical Study on Configuring In-Context Learning Demonstrations for Unleashing MLLMs' Sentimental Perception Capability
May 22, 2025The advancements in Multimodal Large Language Models (MLLMs) have enabled various multimodal tasks to be addressed under a zero-shot paradigm. This paradigm sidesteps the cost of model fine-tuning, emerging as a dominant trend in practical application. Nevertheless, Multimodal Sentiment Analysis (MSA), a pivotal challenge in the quest for general artificial intelligence, fails to accommodate this convenience. The zero-shot paradigm exhibits undesirable performance on MSA, casting doubt on whether MLLMs can perceive sentiments as competent as supervised models. By extending the zero-shot paradigm to In-Context Learning (ICL) and conducting an in-depth study on configuring demonstrations, we validate that MLLMs indeed possess such capability. Specifically, three key factors that cover demonstrations' retrieval, presentation, and distribution are comprehensively investigated and optimized. A sentimental predictive bias inherent in MLLMs is also discovered and later effectively counteracted. By complementing each other, the devised strategies for three factors result in average accuracy improvements of 15.9% on six MSA datasets against the zero-shot paradigm and 11.2% against the random ICL baseline.
Char-SAM: Turning Segment Anything Model into Scene Text Segmentation Annotator with Character-level Visual Prompts
Dec 27, 2024



The recent emergence of the Segment Anything Model (SAM) enables various domain-specific segmentation tasks to be tackled cost-effectively by using bounding boxes as prompts. However, in scene text segmentation, SAM can not achieve desirable performance. The word-level bounding box as prompts is too coarse for characters, while the character-level bounding box as prompts suffers from over-segmentation and under-segmentation issues. In this paper, we propose an automatic annotation pipeline named Char-SAM, that turns SAM into a low-cost segmentation annotator with a Character-level visual prompt. Specifically, leveraging some existing text detection datasets with word-level bounding box annotations, we first generate finer-grained character-level bounding box prompts using the Character Bounding-box Refinement CBR module. Next, we employ glyph information corresponding to text character categories as a new prompt in the Character Glyph Refinement (CGR) module to guide SAM in producing more accurate segmentation masks, addressing issues of over-segmentation and under-segmentation. These modules fully utilize the bbox-to-mask capability of SAM to generate high-quality text segmentation annotations automatically. Extensive experiments on TextSeg validate the effectiveness of Char-SAM. Its training-free nature also enables the generation of high-quality scene text segmentation datasets from real-world datasets like COCO-Text and MLT17.
Track the Answer: Extending TextVQA from Image to Video with Spatio-Temporal Clues
Dec 17, 2024



Video text-based visual question answering (Video TextVQA) is a practical task that aims to answer questions by jointly reasoning textual and visual information in a given video. Inspired by the development of TextVQA in image domain, existing Video TextVQA approaches leverage a language model (e.g. T5) to process text-rich multiple frames and generate answers auto-regressively. Nevertheless, the spatio-temporal relationships among visual entities (including scene text and objects) will be disrupted and models are susceptible to interference from unrelated information, resulting in irrational reasoning and inaccurate answering. To tackle these challenges, we propose the TEA (stands for ``\textbf{T}rack th\textbf{E} \textbf{A}nswer'') method that better extends the generative TextVQA framework from image to video. TEA recovers the spatio-temporal relationships in a complementary way and incorporates OCR-aware clues to enhance the quality of reasoning questions. Extensive experiments on several public Video TextVQA datasets validate the effectiveness and generalization of our framework. TEA outperforms existing TextVQA methods, video-language pretraining methods and video large language models by great margins.
Resolving Sentiment Discrepancy for Multimodal Sentiment Detection via Semantics Completion and Decomposition
Jul 09, 2024



With the proliferation of social media posts in recent years, the need to detect sentiments in multimodal (image-text) content has grown rapidly. Since posts are user-generated, the image and text from the same post can express different or even contradictory sentiments, leading to potential \textbf{sentiment discrepancy}. However, existing works mainly adopt a single-branch fusion structure that primarily captures the consistent sentiment between image and text. The ignorance or implicit modeling of discrepant sentiment results in compromised unimodal encoding and limited performances. In this paper, we propose a semantics Completion and Decomposition (CoDe) network to resolve the above issue. In the semantics completion module, we complement image and text representations with the semantics of the OCR text embedded in the image, helping bridge the sentiment gap. In the semantics decomposition module, we decompose image and text representations with exclusive projection and contrastive learning, thereby explicitly capturing the discrepant sentiment between modalities. Finally, we fuse image and text representations by cross-attention and combine them with the learned discrepant sentiment for final classification. Extensive experiments conducted on four multimodal sentiment datasets demonstrate the superiority of CoDe against SOTA methods.
Towards Escaping from Language Bias and OCR Error: Semantics-Centered Text Visual Question Answering
Mar 24, 2022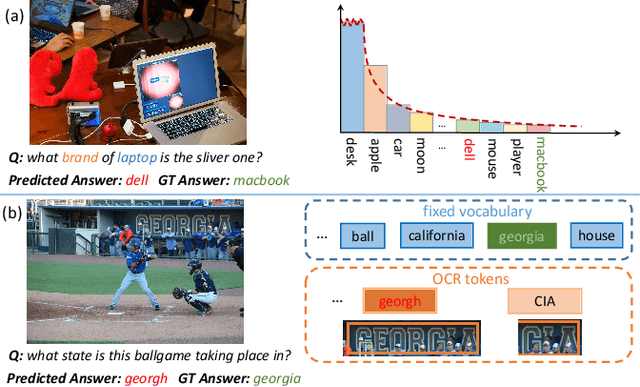

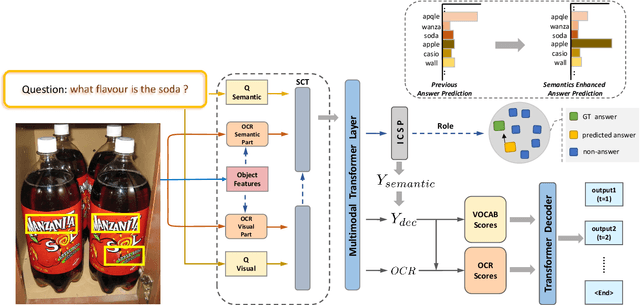

Texts in scene images convey critical information for scene understanding and reasoning. The abilities of reading and reasoning matter for the model in the text-based visual question answering (TextVQA) process. However, current TextVQA models do not center on the text and suffer from several limitations. The model is easily dominated by language biases and optical character recognition (OCR) errors due to the absence of semantic guidance in the answer prediction process. In this paper, we propose a novel Semantics-Centered Network (SC-Net) that consists of an instance-level contrastive semantic prediction module (ICSP) and a semantics-centered transformer module (SCT). Equipped with the two modules, the semantics-centered model can resist the language biases and the accumulated errors from OCR. Extensive experiments on TextVQA and ST-VQA datasets show the effectiveness of our model. SC-Net surpasses previous works with a noticeable margin and is more reasonable for the TextVQA task.